This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In this constantly growing era, the volume of data is increasing rapidly, and tons of data points are produced every second. Now, businesses are looking for different types of datastorage to store and manage their data effectively.
Datastorage has been evolving, from databases to datawarehouses and expansive datalakes, with each architecture responding to different business and data needs. Now you dont have to choose. This is why Snowflake is fully embracing this open table format.
A comparative overview of datawarehouses, datalakes, and data marts to help you make informed decisions on datastorage solutions for your data architecture.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a datawarehouse. What is a DataWarehouse? What is a DataLake?
A brief history of datastorage The value of data has been apparent for as long as people have been writing things down. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Though basic and easy to use, traditional table storage formats struggle to keep up. Track data files within the table along with their column statistics.
“DataLake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Datalake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for datastorage are evolving quickly. So let’s get to the bottom of the big question: what kind of datastorage layer will provide the strongest foundation for your data platform?
[link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified datawarehouse. GetYourGuide discusses migrating its Business Intelligence (BI) data source from Snowflake to Databricks, achieving a 20% cost reduction.
There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate. DataStorage Solutions As we all know, data can be stored in a variety of ways.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Datalakes are useful, flexible datastorage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption.
Striim, for instance, facilitates the seamless integration of real-time streaming data from various sources, ensuring that it is continuously captured and delivered to big datastorage targets. This method is advantageous when dealing with structured data that requires pre-processing before storage.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. Picking the right format for your datastorage.
A datalake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this datastorage and processing layer, or a data lakehouse or datawarehouse, to store data and process it before it is later transformed and sent off for analysis.
In 2010, a transformative concept took root in the realm of datastorage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
This approach is fantastic when you’re not quite sure how you’ll need to use the data later, or when different teams might need to transform it in different ways. It’s more flexible than ETL and works great with the low cost of modern datastorage.
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission-critical, large-scale data analytics and AI use cases—including enterprise datawarehouses.
Concepts, theory, and functionalities of this modern datastorage framework Photo by Nick Fewings on Unsplash Introduction I think it’s now perfectly clear to everybody the value data can have. To use a hyped example, models like ChatGPT could only be built on a huge mountain of data, produced and collected over years.
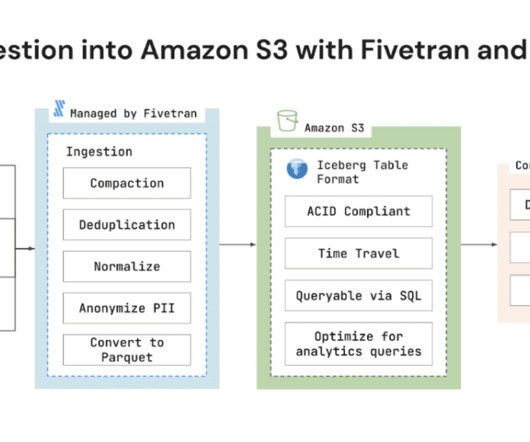
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
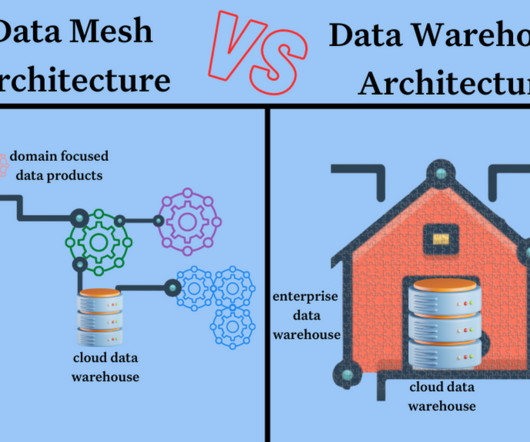
Data mesh vs datawarehouse is an interesting framing because it is not necessarily a binary choice depending on what exactly you mean by datawarehouse (more on that later). Despite their differences, however, both approaches require high-quality, reliable data in order to function. What is a Data Mesh?
Nowadays, the term is used for petabytes or even exabytes of data (1024 Petabytes), close to trillions of records from billions of people. In this fast-moving landscape, the key to making a difference is picking up the correct datastorage solution for your business. […]
With the vast amount of data being collected today for various purposes, there is an increasing need to find the proper datastorage, which also heavily depends on your specific analytical objectives. This […]
For example, we have some customers using their data platform originally established for compliance initiatives to drive new use cases. These datalakes house much of the data needed to also support other use cases. We see this consistently in the data platform/datastorage space. .
Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads? Hightouch is the easiest way to sync data into the platforms that your business teams rely on. The data you’re looking for is already in your datawarehouse and BI tools. No more scripts, just SQL.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Datastorage and compute are very much the foundation of your data platform. Let’s jump in!
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, datawarehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
They make data workflows more resilient and easier to manage when things inevitably go sideways. This guide tackles the big decisions every data engineer faces: Should you clean your data before or after loading it? Datalake or warehouse? DataLakes vs. DataWarehouses: Where Should Your Data Live?
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
Data platforms are no longer skunkworks projects or science experiments. As customers import their mainframe and legacy datawarehouse workloads, there is an expectation on the platform that it can meet, if not exceed, the resilience of the prior system and its associated dependencies.
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks.
Data engineer’s integral task is building and maintaining data infrastructure — the system managing the flow of data from its source to destination. This typically includes setting up two processes: an ETL pipeline , which moves data, and a datastorage (typically, a datawarehouse ), where it’s kept.
Datalakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
Taking a hard look at data privacy puts our habits and choices in a different context, however. Data scientists’ instincts and desires often work in tension with the needs of data privacy and security. Anyone who’s fought to get access to a database or datawarehouse in order to build a model can relate.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like data pipelines, datastorage and retrieval, data orchestrators or infrastructure-as-code.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and datawarehouses and this post will explain this all. What is a data lakehouse? Datawarehouse vs datalake vs data lakehouse: What’s the difference.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content