This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Datalakes are notoriously complex. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free!
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Datalakes are notoriously complex.
In this episode Tasso Argyros, CEO of ActionIQ, gives a summary of the major epochs in database technologies and how he is applying the capabilities of cloud datawarehouses to the challenge of building more comprehensive experiences for end-users through a modern customer data platform (CDP).
Datalakes are notoriously complex. Your host is Tobias Macey and today I'm interviewing Ronen Korman and Stav Elkayam about pulling back the curtain on your real-time data streams by bringing intuitive observability to Flink streams Interview Introduction How did you get involved in the area of data management?
Shifting left involves moving data processing upstream, closer to the source, enabling broader access to high-qualitydata through well-defined data products and contracts, thus reducing duplication, enhancing data integrity, and bridging the gap between operational and analytical data domains.
There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Cloud computing has made it much easier to integrate data sets, but that’s only the beginning. Creating a datalake has become much easier, but that’s only ten percent of the job of delivering analytics to users. It often takes months to progress from a datalake to the final delivery of insights.
Cloudera’s mission, values, and culture have long centered around using open source engines on open data and table formats to enable customers to build flexible and open datalakes. The Open Data Lakehouse . dbt used in transformation pipelines on datawarehouses (Image source: [link].
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and datalakes, bringing together the structure and performance of a datawarehouse with the flexibility of a datalake.
You know what they always say: data lakehouse architecture is like an onion. …ok, Data lakehouse architecture combines the benefits of datawarehouses and datalakes, bringing together the structure and performance of a datawarehouse with the flexibility of a datalake.
A data fabric offers several key benefits that transform your data management: Accelerates analytics and decision-making processes by enhancing data accessibility through seamless data integration and retrieval across diverse environments. Increase metadata maturity.
They need high-qualitydata in an answer-ready format to address many scenarios with minimal keyboarding. What they are getting from IT and other data sources is, in reality, poor-qualitydata in a format that requires manual customization. IT-created infrastructure such as a datalake/warehouse).
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring dataquality for either type of asset are much the same. We’ll take a closer look at variables that can impact your data next. Rise of the Data Lakehouse Datawarehouse or datalake?
And this renewed focus on dataquality is bringing much needed visibility into the health of technical systems. As generative AI (and the data powering it) takes center stage, it’s critical to bring this level of observability to where your data lives, in your datawarehouse , datalake , or data lakehouse.
It’s our goal at Monte Carlo to provide data observability and quality across the enterprise by monitoring every system vital in the delivery of data from source to consumption. We started with popular modern datawarehouses and quickly expanded our support as datalakes became data lakehouses.
They should also be proficient in programming languages such as Python , SQL , and Scala , and be familiar with big data technologies such as HDFS , Spark , and Hive. Learn programming languages: Azure Data Engineers should have a strong understanding of programming languages such as Python , SQL , and Scala.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , datawarehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
While different solutions or tools may have significant differences in features offered, there is no real difference between data observability and data reliability engineering. Both terms are focused on the practice of ensuring healthy, highqualitydata across an organization. It is still relevant today.
And this renewed focus on dataquality is bringing much needed visibility into the health of technical systems. As generative AI (and the data powering it) takes center stage, it’s critical to bring this level of observability to where your data lives, in your datawarehouse , datalake , or data lakehouse.
They provide insights into the health of data integration processes, detect issues in real-time, and enable teams to optimize data flows. Datalake and datawarehouse monitoring: These tools monitor the performance, storage, and access patterns of datalakes and datawarehouses, ensuring optimal performance and data availability.
At some point in the last two decades, the size of our data became inextricably linked to our ego. We watched enviously as FAANG companies talked about optimizing hundreds of petabyes in their datalakes or datawarehouses. We imagined what it would be like to manage big dataquality at that scale.
Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manage Data Pipelines for the latest, high-qualitydata in Delta Lake. Azure Blob Storage serves as the datalake to store raw data. It does the job.
With these points in mind, I argue that the biggest hurdle to the widespread adoption of these advanced techniques in the healthcare industry is not intrinsic to the industry itself, or in any way related to its practitioners or patients, but simply the current lack of high-qualitydata pipelines.
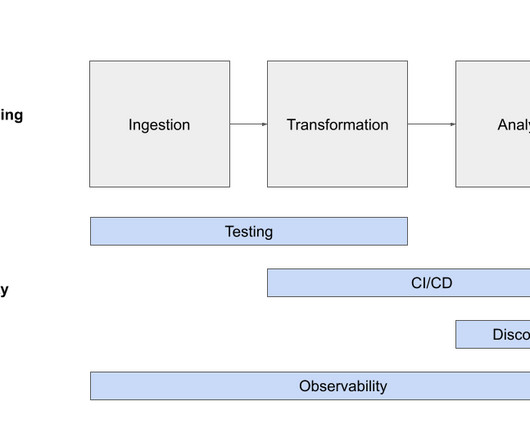
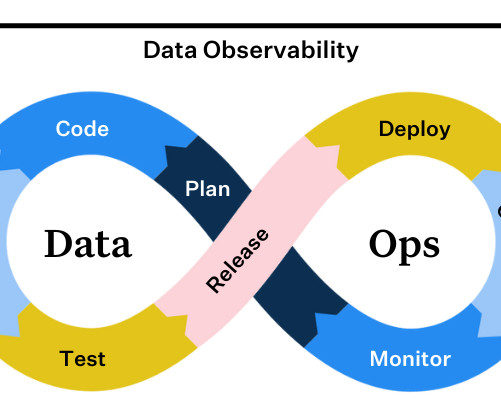
Similarly, the discipline of DataOps helps teams remove silos and work more efficiently to deliver high-qualitydata products across the organization. DataOps professionals also leverage observability to decrease downtime as companies begint o ingest large amounts of data from various sources.
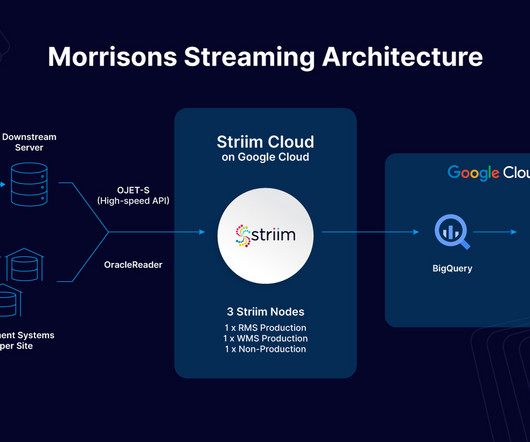
During data ingestion, raw data is extracted from sources and ferried to either a staging server for transformation or directly into the storage level of your data stack—usually in the form of a datawarehouse or datalake. There are two primary types of raw data.
Key components include: ETL Tools: To extract, transform, and load data from systems such as enterprise resource planning (ERP) software, customer relationship management (CRM) platforms, and other operational systems. BI Platforms: For data visualization and reporting.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content