This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured data management that really hit its stride in the early 1990s.
Introduction A datalake is a centralized and scalable repository storing structured and unstructureddata. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary Working with unstructureddata has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Datawarehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. datawarehouse. It is often used as a foundation for enterprise datalakes.
Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While datawarehouses are still in use, they are limited in use-cases as they only support structured data.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a datawarehouse. What is a DataWarehouse? What is a DataLake?
The terms “ DataWarehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataWarehouse? .
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Different vendors offering datawarehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
“DataLake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Datalake?
[link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructureddata is a top question for every organization.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Interoperable storage: Snowflake enables customers to access and process structured, semi-structured and unstructureddata seamlessly, without silos or delays. Unique automations and optimizations include encryption by default, built-in storage compression and fast access to data even at petabyte scale.
In the early 2000s, organizations started dealing with more semi-structured and unstructureddata, which consisted of images, videos, log files, text, and sensor data. They needed a storage solution that was more flexible than a datawarehouse.
A robust data infrastructure is a must-have to compete in the F1 business. We’ll build a data architecture to support our racing team starting from the three canonical layers : DataLake, DataWarehouse, and Data Mart. Data Marts There is a thin line between DataWarehouses and Data Marts.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a datawarehouse for further processing, analysis, and consumption.
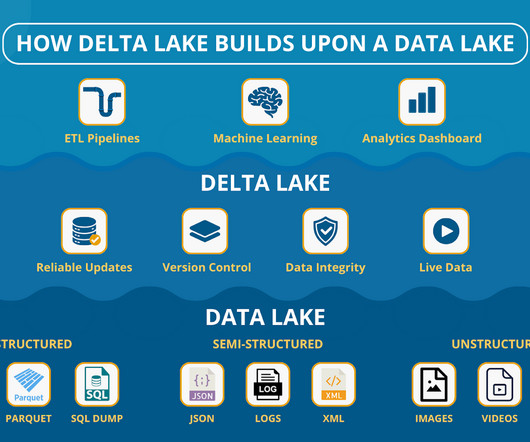
Datalakes turned into swamps , pipelines burst, and just when you thought youd earned a degree in hydrology, someone leaned in and whispered: Delta Lake. Are we building data dams next? Lets break it down and see when a plain datalake works and when youll want the extra reliability of Delta Lake.
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build datalakes and ingest raw data extracted from different sources, including structured, semi-structured, and unstructureddata.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a DataLake? Consistency of data throughout the datalake.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
The Rise of Data Observability Data observability has become increasingly critical as companies seek greater visibility into their data processes. This growing demand has found a natural synergy with the rise of the datalake. As a result, monitoring data in real time was often an afterthought.
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently. And what is the reason for that?
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically datawarehouses. This method is advantageous when dealing with structured data that requires pre-processing before storage.
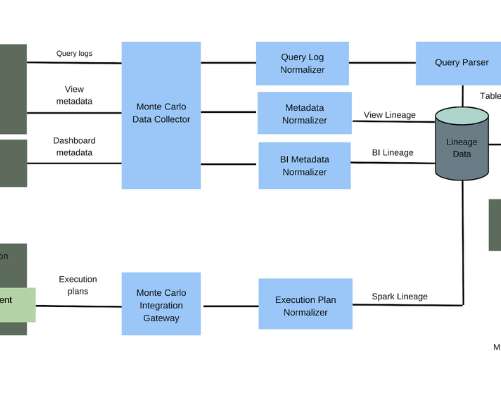
With the new Databricks integration from Monte Carlo, teams working in datalakes can finally trust their data through end-to-end data observability and automated lineage of their entire data ecosystem. Over the last few years, datalakes have emerged as a must-have for the modern data stack.
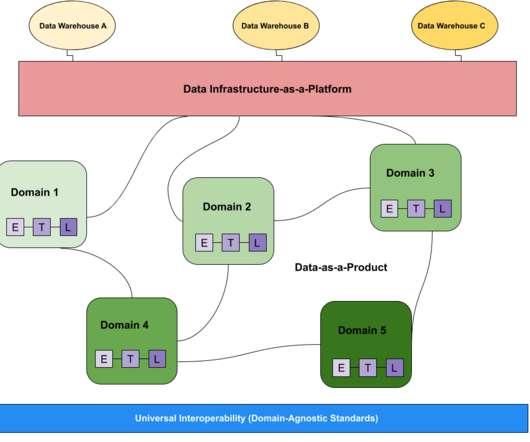
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Monte Carlo also gives you a holistic picture of data health with automatic, end-to-end lineage from ingestion to the BI layer directly out of the box. images, documents, etc.) images, documents, etc.)
Morgan Stanley Data Engineer Interview Questions As a data engineer at Morgan Stanley, you will be responsible for creating and maintaining the infrastructure for their datawarehouse. Analyzing this data often involves Machine Learning, a part of Data Science. What is a datawarehouse?
Data Store Another significant change from 2021 to 2024 lies in the shift from “DataWarehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of DataLakes. Their robust core offering seamlessly integrates datawarehouses with data-hungry applications.
When implementing a data lakehouse, the table format is a critical piece because it acts as an abstraction layer, making it easy to access all the structured, unstructureddata in the lakehouse by any engine or tool, concurrently. Some of the popular table formats are Apache Iceberg, Delta Lake, Hudi, and Hive ACID.
Metadata from the datawarehouse/lake and from the BI tool of record can then be used to map the dependencies between the tables and dashboards. It also becomes outdated virtually the moment it’s mapped as your environment continues to ingest more data and you continue to layer on additional solutions.
Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. And second, for the data that is used, 80% is semi- or unstructured. Both obstacles can be overcome using modern data architectures, specifically data fabric and data lakehouse.
It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, datawarehouses, etc., Glue uses ETL jobs for extracting data from various AWS cloud services and integrating it into datawarehouses and lakes.
They make data workflows more resilient and easier to manage when things inevitably go sideways. This guide tackles the big decisions every data engineer faces: Should you clean your data before or after loading it? Datalake or warehouse? DataLakes vs. DataWarehouses: Where Should Your Data Live?
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. Data storage and compute are very much the foundation of your data platform. Let’s jump in! So, let’s take a look at each in a bit more detail.
Now let’s think of sweets as the data required for your company’s daily operations. Instead of combing through the vast amounts of all organizational data stored in a datawarehouse, you can use a data mart — a repository that makes specific pieces of data available quickly to any given business unit.
Data lakehouse architecture combines the benefits of datawarehouses and datalakes, bringing together the structure and performance of a datawarehouse with the flexibility of a datalake. Image courtesy of Databricks.
Data lakehouse architecture combines the benefits of datawarehouses and datalakes, bringing together the structure and performance of a datawarehouse with the flexibility of a datalake. Image courtesy of Databricks.
Datalakes, datawarehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content