This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Want to process peta-byte scale data with real-time streaming ingestions rates, build 10 times faster data pipelines with 99.999% reliability, witness 20 x improvement in query performance compared to traditional datalakes, enter the world of Databricks Delta Lake now. Delta Lake is a game-changer for big data.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
This guide is your roadmap to building a datalake from scratch. We'll break down the fundamentals, walk you through the architecture, and share actionable steps to set up a robust and scalable datalake. That’s where datalakes come in. Table of Contents What is a DataLake?
Many organizations are struggling to store, manage, and analyze data due to its exponential growth. Cloud-based datalakes allow organizations to gather any form of data, whether structured or unstructured, and make this data accessible for usage across various applications, to address these issues.
In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time datalake without all of the headache. What is the impact of continuous data flows on dags/orchestration of transforms? RudderStack also supports real-time use cases.
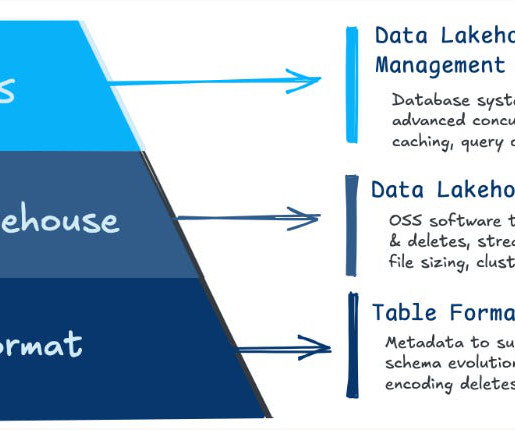
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a Data Warehouse? Asked yourself what components and features would that include.
Image by Rachel Claire on Pexels Ever wanted or been asked to build an open-source DataLake offloading data for analytics? Didn’t know the difference between a Data Lakehouse and a Data Warehouse? Asked yourself what components and features would that include.
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Datafold has recently launched data replication testing, providing ongoing validation for source-to-target replication.
Did you know that the global datalakes market will likely grow at a CAGR of 29.9% Modern businesses are more likely to make data-driven decisions. Organizations are generating a massive volume of data due to the rise in digitalization. What is Azure DataLake ? and reach USD 17.60 billion by 2026?
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Summary A significant portion of data workflows involve storing and processing information in database engines. In this episode Gleb Mezhanskiy, founder and CEO of Datafold, discusses the different error conditions and solutions that you need to know about to ensure the accuracy of your data. Datalakes are notoriously complex.
Microsoft offers Azure DataLake, a cloud-based data storage and analytics solution. It is capable of effectively handling enormous amounts of structured and unstructured data. Therefore, it is a popular choice for organizations that need to process and analyze big data files.
Summary Building a database engine requires a substantial amount of engineering effort and time investment. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database. Datalakes are notoriously complex.
The demand for higher data velocity, faster access and analysis of data as its created and modified without waiting for slow, time-consuming bulk movement, became critical to business agility. Which turned into datalakes and data lakehouses Poor data quality turned Hadoop into a data swamp, and what sounds better than a data swamp?
A few months ago, I uploaded a video where I discussed data warehouses, datalakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning.
Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products. With Materialize, you can!
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. Well also dive into […] The post How to Use Apache Iceberg Tables? appeared first on Analytics Vidhya.
One question that puzzled me, though, was how tools like the Debezium CDC connectors can read changes from MySQL and PostgreSQL databases. Change Data Capture (CDC) SystemExample Diagram (Created using Lucidchart) What is Change DataCapture? MysqlBinlog MySQL uses a binary log to record changes to the database.
Data Access API over DataLake Tables Without the Complexity Build a robust GraphQL API service on top of your S3 datalake files with DuckDB and Go Photo by Joshua Sortino on Unsplash 1. This data might be primarily used for internal reporting, but might also be valuable for other services in our organization.
Unify transactional and analytical workloads in Snowflake for greater simplicity Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads.
It offers a simple and efficient solution for data processing in organizations. It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, data warehouses , etc., being data exactly matches the classifier, and 0.0
Before it migrated to Snowflake in 2022, WHOOP was using a catalog of tools — Amazon Redshift for SQL queries and BI tooling, Dremio for a datalake, PostgreSQL databases and others — that had ultimately become expensive to manage and difficult to maintain, let alone scale.
Azure Data Factory is a cloud-based, fully managed, serverless ETL and data integration service offered by Microsoft Azure for automating data movement from its native place to, say, a datalake or data warehouse using ETL (extract-transform-load) OR extract-load-transform (ELT).
What if your datalake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data.
Managing the operational concerns for your database can be complex and expensive, especially if you need to scale to large volumes of data, high traffic, or geographically distributed usage. No more shipping and praying, you can now know exactly what will change in your database! or any other destination you choose.
RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Starburst : 
















































Let's personalize your content