This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A datalake is essentially a vast digital dumping ground where companies toss all their raw data, structured or not. A modern data stack can be built on top of this data storage and processing layer, or a data lakehouse or data warehouse, to store data and process it before it is later transformed and sent off for analysis.
A data leader from the manufacturing industry mentioned their need for a data mesh, but was still wrestling with a number of manual data management processes and needed to first focus on organizing their data into a local data warehouse or datalake.
Summary The "data lakehouse" architecture balances the scalability and flexibility of datalakes with the ease of use and transaction support of data warehouses. Enter Metaplane, the industry’s only self-serve data observability tool. Setup takes 30 minutes. Setup takes 30 minutes.
The Gartner Data & Analytics Summit offers an immersive learning experience tailored to help you: Stay Competitive : Hear real-life success stories and learn best practices that can be directly applied to your own data strategies. Register here.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Setup takes 30 minutes.
Enter Metaplane, the industry’s only self-serve data observability tool. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. Setup takes 30 minutes.
Enter Metaplane, the industry’s only self-serve data observability tool. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. Setup takes 30 minutes.
Enter Metaplane, the industry’s only self-serve data observability tool. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. Setup takes 30 minutes.
Enter Metaplane, the industry’s only self-serve data observability tool. Data leaders at Imperfect Foods, Drift, and Vendr love Metaplane because it helps them catch, investigate, and fix data quality issues before their stakeholders ever notice they exist. Setup takes 30 minutes. Setup takes 30 minutes.
Editor’s Note: Chennai, India Meetup - March-08 Update We are thankful to Ideas2IT to host our first Data Hero’s meetup. There will be food, networking, and real-world talks around data engineering. Visit rudderstack.com to learn more.
Building Spark Lineage For DataLakes Everyone writes about the successful projects, but you learn more from the failures. Our engineering team at Monte Carlo describes why developing Spark lineage for datalakes is so much harder than for data warehouses.
Use cases could include but are not limited to: optimizing healthcare processes to save lives, data analysis for emergency resource management, building smarter cities with data science, using data and analytics to fight climate change, tackle the food crisis or prioritize actions against poverty, and more.
(Source : [link] ANZ bank to move 'quaint' data ponds into single Hadoop-based data lake.Zdnet.com, February 21, 2017 Australia and New Zealand Banking Group is working on a project to build an enterprise wide datalake so that it can capitalise on the most strategic assets. Source - [link] ) Attunity Wins $1.8
Transforming Go-to-Market After years of acquiring and integrating smaller companies, a $37 billion multinational manufacturer of confectionery, pet food, and other food products was struggling with complex and largely disparate processes, systems, and data models that needed to be normalized.
This initiative demonstrates how advanced AI technologies can empower data engineering efforts to create more intelligent and user-centric systems in the food delivery industry. link] Grab: Ensuring data reliability and observability in risk systems.
However, another way to think about it is that solving for data quality requires you to think beyond a point in time, and consider how the quality changes over time in a variety of real-world conditions. That is true data reliability.
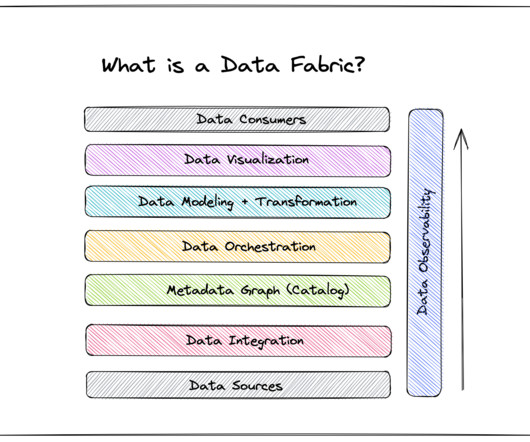
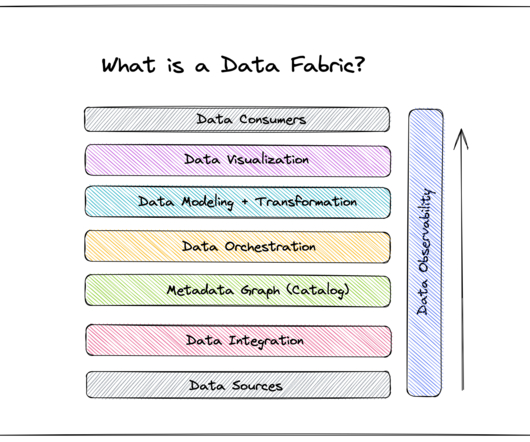
These include: Seamless integration A data fabric’s ability to integrate seamlessly with various APIs and software-delivery kits (SDKs) truly differentiates this framework from another type of data management: the ubiquitous datalake. Frequent customer communication and personalization are key to Domino’s success.
These include: Seamless integration A data fabric’s ability to integrate seamlessly with various APIs and software-delivery kits (SDKs) truly differentiates this framework from another type of data management: the ubiquitous datalake. Frequent customer communication and personalization are key to Domino’s success.
Every predetermined time period, the agents would scan the applications for newly-entered or uploaded data -- everything from highly-compressed herd genetic data, to dimensional models. When a change is detected, the data is ingested into a datalake hosted on Amazon S3.
Also, where the data relates to living individuals within the European Union, the General Data Protection Regulations (GDPR) requires similar assurance, and non-compliance carries severe financial penalties and potential prosecution.
Background: McDonald's Corporation, a global fast-food giant, has embraced digital transformation to redefine its operations and enhance customer experiences. AWS DataLake Integration: To effectively manage and analyze large volumes of data, Yulu utilized AWS datalake capabilities, providing a scalable and secure infrastructure.
The welcome happy hour in the exhibitor hall was packed with thousands of data leaders enjoying drinks, Chinese food, and vendor elevator pitches. It’s essentially the early days of the Apple app store but for data applications, and that model seemed to work out OK for Apple.
They can keep their nutritionist updated with their daily weight, their exercise regimen and their food macros; they can also use a wearable device to track their heart rate during an exercise session.
For Freshly, food isn’t the only thing that needs to be delivered fresh and fast; our data also needs to be reliable, timely, and most importantly, accurate. We are also using Fivetran to parse and load data from dozens of Google Sheets into Snowflake. Editor’s Note: Nestle acquired Freshly in October 2020.
After knowing that consumers were increasingly concerned about the freshness of food, Walmart trained personnel to evaluate the quality of produce and showed food items to the customers before packing them. Walmart repurposed 200 of its existing outlets to provide grocery pickup in 30 cities.
Food Panda, a food delivery app, is another famous example that implements this. AWS S3 allows you to store the dataset (CSV file) in S3 buckets for further processing, and CloudWatch keeps track of your data's log files and lets you analyze them as needed. Source Code- AWS Athena Big Data Project for Querying COVID-19 Data 25.
4 Catch Your Data Easily and Quickly with MongoDB Atlas DataLake Check out the power of MongoDB queries on massive-scale data in your datalake with real-world use cases from a self-proclaimed bald nerd. Understanding how the optimizer is powered is a key start to avoiding sluggish query performance.
GoDaddy, layered architecture for a datalake — Naming conventions ideas and 5 data layers: source, raw, clean, enterprise and analytical. A few food for thought articles about data concepts and roles.
Food for thoughts Docker for data products. Why Agile and Product Management fail with Data & AI? Lightdash raises $11m — I really like Lightdash, it's a promising great mix between a BI tool, a semantic layer, as code. Who’s really responsible for team failures?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content