This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary A data lakehouse is intended to combine the benefits of datalakes (cost effective, scalable storage and compute) and data warehouses (user friendly SQL interface). Datalakes are notoriously complex. Visit [dataengineeringpodcast.com/data-council]([link] and use code *depod20* to register today!
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
If you are migrating to a modern data stack, Datafold can also help you automate data and code validation to speed up the migration. Learn more about Datafold by visiting dataengineeringpodcast.com/datafold Datalakes are notoriously complex. webapps vs. data pipelines vs. exploratory analysis, etc.)
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. This is a task best left to expert Java programming minds.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. runs natively on datalakes and warehouses and in AWS, Google Cloud and Microsoft Azure.
We publish a curated data set containing dependency data from the SBOM for every application we deploy, based on its Container image. The data set is available in our datalake and thus can be easily queried and visualized by any engineer. Another insight from analyzing the SBOM data was our usage of the AWS SDK.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake.
Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management. Data Storage Solutions As we all know, data can be stored in a variety of ways.
Summary The "data lakehouse" architecture balances the scalability and flexibility of datalakes with the ease of use and transaction support of data warehouses. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
We use a homegrown data collector to grab our customers’ SQL logs from their data warehouse or lake, stream the data to different components of our data pipelines. The back-end architecture of our field-level SQL lineage solution looks something like this: Easy?
The Rise of the Data Engineer The Downfall of the Data Engineer Functional Data Engineering — a modern paradigm for batch data processing There is a global consensus stating that you need to master a programming language (Python or Java based) and SQL in order to be self-sufficient.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
It can aggregate and summarize access patterns from multiple datalakes. From the profiled data summaries of access patterns, one can put in place security policies using Apache Ranger to detect and handle any problematic access. Sensitive data identification. HBase Thrift gateway support impersonation out of the box.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
DuckDB is an in-process database engine optimized for OLAP applications to speed up your analytical queries that meets you where you are, whether that’s Python, R, Java, even the web. Sometimes what you really need is an embedded database that is blazing fast for single user workloads.
In the typical manufacturing enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This data engineering skill set typically consists of Java or Scala programming skills mated with deep DevOps acumen. A rare breed. Available Solutions .
First-generation – expensive, proprietary enterprise data warehouse and business intelligence platforms maintained by a specialized team drowning in technical debt. Second-generation – gigantic, complex datalake maintained by a specialized team drowning in technical debt. Data professionals are not perfectly interchangeable.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
Snowplow takes care of everything from installing your pipeline in a couple of hours to upgrading and autoscaling so you can focus on your exciting data projects. Your team will get the most complete, accurate and ready-to-use behavioral web and mobile data, delivered into your data warehouse, datalake and real-time streams.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Can you describe how Whylogs is implemented?
The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability. Ascend users love its declarative pipelines, powerful SDK, elegant UI, and extensible plug-in architecture, as well as its support for Python, SQL, Scala, and Java.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or datalake. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or datalake. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. RudderStack helps you build a customer data platform on your warehouse or datalake.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. RudderStack helps you build a customer data platform on your warehouse or datalake.
Data Engineering Podcast listeners can sign up for a free 2-week sandbox account, go to dataengineeringpodcast.com/tonic today to give it a try! RudderStack helps you build a customer data platform on your warehouse or datalake. RudderStack helps you build a customer data platform on your warehouse or datalake.
RudderStack helps you build a customer data platform on your warehouse or datalake. Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control.
Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or datalake. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
Mention the podcast to get a free "In Data We Trust World Tour" t-shirt. RudderStack helps you build a customer data platform on your warehouse or datalake. The Ascend Data Automation Cloud provides a unified platform for data ingestion, transformation, orchestration, and observability.
There are different ways how data can be stored: a data warehouse, numerous datalakes and data hubs , etc. Data engineers control how data is stored and structured within those locations. Providing data access tools. An overview of data engineer skills. Statistics and maths.
In the early days, many companies simply used Apache Kafka ® for data ingestion into Hadoop or another datalake. Some Kafka and Rockset users have also built real-time e-commerce applications , for example, using Rockset’s Java, Node.js However, Apache Kafka is more than just messaging.
Laila wants to use CSP but doesn’t have time to brush up on her Java or learn Scala, but she knows SQL really well. . SSB provides a comprehensive interactive user interface for developers, data analysts, and data scientists to write streaming applications with industry standard SQL. Without context, streaming data is useless.”
The alleviation of infrastructure and computational constraints associated with solely on-premises data platforms; Data Products can now use different deployment models (e.g., Deep Java Learning, Apache Spark 3.x, data warehousing). hybrid or public, multi-cloud) and advanced analytical frameworks (e.g.,
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of raw data.
The Apache Iceberg project also develops an implementation of the specification in the form of a Java library. Thus simplifying data exploration, ETL and deriving analytical insights on any enterprise data across the DataLake. This library is integrated by execution engines such as Impala, Hive and Spark.
A big challenge is to support and manage multiple semantically enriched data models for the same underlying data, e.g., into a graph data model to trace value flow or into a MapReduce-compatible data model of the UTXO-based Bitcoin blockchain.
To provide end users with a variety of ready-made models, Azure Data engineers collaborate with Azure AI services built on top of Azure Cognitive Services APIs. The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












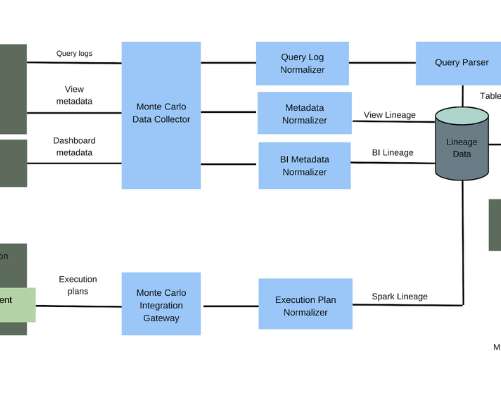

































Let's personalize your content