This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! What are the capabilities that a centralized and holistic view of a platform’s metadata can enable?
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. What are the other systems that feed into and rely on the Trino/Iceberg service?
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. That leaves DataOps reactive to data quality issues and can make your consumers lose confidence in your data. lets you identify data quality issues and their root causes from a single dashboard.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
Data stewards can also set up Request for Access (private preview) by setting a new visibility property on objects along with contact details so the right person can easily be reached to grant access. Support for auto-refresh and Iceberg metadata generation is coming soon to Delta Lake Direct.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in datalakes and lakehouses.
Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used. Can you describe what Iceberg is and its position in the datalake/lakehouse ecosystem? Acryl]([link] The modern data stack needs a reimagined metadata management platform.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. What you have to code is this workflow !
Datalakes are notoriously complex. For data engineers who battle to build and scale high quality data workflows on the datalake, Starburst powers petabyte-scale SQL analytics fast, at a fraction of the cost of traditional methods, so that you can meet all your data needs ranging from AI to data applications to complete analytics.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Stop struggling to speed up your datalake.
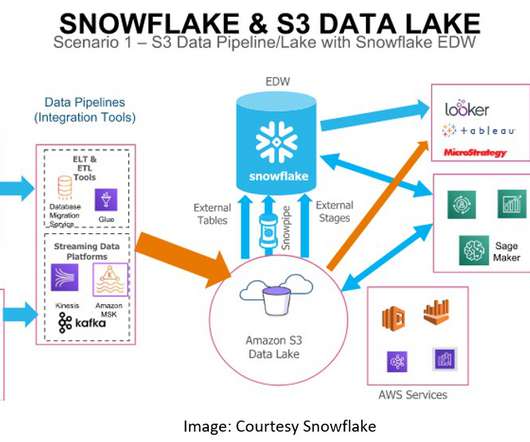
Read Time: 4 Minute, 23 Second During this post we will discuss how AWS S3 service and Snowflake integration can be used as DataLake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake DataLake capabilities.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Fluss uses Lakehouse as a tiered storage, and data will be converted and tiered into datalakes periodically; Fluss only retains a small portion of recent data. So you only need to store one copy of data for your streaming and Lakehouse. The TabletServer stores data and provides I/O services directly to users.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management RudderStack helps you build a customer data platform on your warehouse or datalake. What are the most interesting, innovative, or unexpected ways that you have seen column-aware data modeling used?
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
With this public preview, those external catalog options are either “GLUE”, where Snowflake can retrieve table metadata snapshots from AWS Glue Data Catalog, or “OBJECT_STORE”, where Snowflake retrieves metadata snapshots directly from the specified cloud storage location. With these three options, which one should you use?
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies.
Change Data Capture (CDC) has emerged as an ideal solution for near real-time movement of data from relational databases (like SQL Server or Oracle) to data warehouses, datalakes or other databases. Data can be extracted using database queries (batch-based) or Change Data Capture (near-real-time).
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. Is your datalake a good fit for Iceberg? I think it’s safe to say it’s getting pretty cold in here.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake.
Datafold integrates with all major data warehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. RudderStack helps you build a customer data platform on your warehouse or datalake. What is the workflow for someone getting Sifflet integrated into their data stack?
Chief Technology Officer, Information Technology Industry Organizations have spent the past decade accumulating, maintaining, and securing datalakes/warehouses/fabrics that will now be expected to drive AI/LLM use cases. The technology for metadata management, data quality management, etc., No problem!
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
The Hive format is also built with the assumptions of a local filesystem which results in painful edge cases when leveraging cloud object storage for a datalake. One of the complicated problems in data modeling is managing table partitions. What are the unique challenges posed by using S3 as the basis for a datalake?
These formats are changing the way data is stored and metadata accessed. Apache Iceberg is a high-performance open table format developed for modern datalakes. Iceberg Data Catalog - an open-source metadata management system that tracks the schema, partition, and versions of Iceberg tables.
Learn More → Notion: Building and scaling Notion’s datalake Notion writes about scaling the datalake by bringing critical data ingestion operations in-house. Hudi seems to be a de facto choice for CDC datalake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
Apache Ozone is one of the major innovations introduced in CDP, which provides the next generation storage architecture for Big Data applications, where data blocks are organized in storage containers for larger scale and to handle small objects. Collects and aggregates metadata from components and present cluster state.
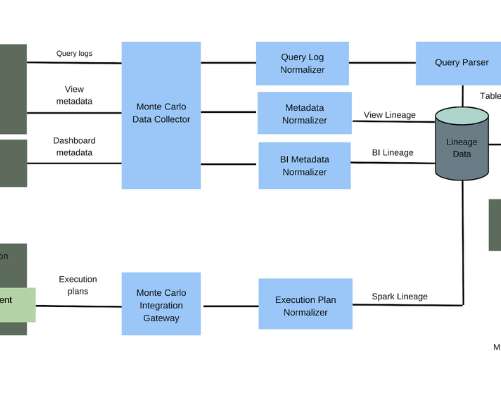
Metadata from the data warehouse/lake and from the BI tool of record can then be used to map the dependencies between the tables and dashboards. Integrating with it is the holy grail of Spark lineage because it contains all the information needed for how data moves through the datalake and how everything is connected.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Again, be prepared to have metadata challenges especially. Struggling with broken pipelines? Stale dashboards?
Catalog Integration: Our newly developed Catalog Integration feature allows you to seamlessly plug Snowflake into other Iceberg catalogs tracking table metadata. Since 2021, Snowflake has had External Tables for the purpose of read-only querying external datalakes.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or datalake.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content