This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, rawdata was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. Is your datalake a good fit for Iceberg? I think it’s safe to say it’s getting pretty cold in here.
Data Ingestion. The rawdata is in a series of CSV files. We will firstly convert this to parquet format as most datalakes exist as object stores full of parquet files. Parquet also stores type metadata which makes reading back and processing the files later slightly easier.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. How Does AWS Glue Work?
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Data Store Another significant change from 2021 to 2024 lies in the shift from “Data Warehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of DataLakes. This metadata is then utilized to manage, monitor, and foster the growth of the platform.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance. Architecture overview. Separate storage. Separate compute.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse?
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
To help organizations realize the full potential of their datalake and lakehouse investments, Monte Carlo, the data observability leader, is proud to announce integrations with Delta Lake and Databricks’ Unity Catalog for full data observability coverage. billion in 2020 to 17.60 billion in 2020 to 17.60
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
This week, we got to think about our data ingestion design. We looked at the following: How do we ingest – ETL vs ELT Where do we store the data – Datalake vs data warehouse Which tool to we use to ingest – cronjob vs workflow engine NOTE : This weeks task requires good internet speed and good compute.
It’s designed to improve upon the performance and usability challenges of older data storage formats such as Apache Hive and Apache Parquet. For example, Monte Carlo can monitor Apache Iceberg tables for data quality incidents, where other data observability platforms may be more limited.
In this very simplified example, we can see an ELT: Some pipeline tasks, probably running by Airflow , are scraping external data sources and collecting data from there. Those tasks are saving the extracted data in the datalake (or warehouse or lakehouse). This technique focuses directly on the data (vs.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
ETL Architecture on AWS: Examining the Scalable Architecture for Data Transformation ETL Architecture on AWS typically consists of three components - Source Data Store A Data Transformation Layer Target Data Store Source Data Store The source data store is where rawdata is stored before being transformed and loaded into the target data store.
SiliconANGLE theCUBE: Analyst Predictions 2023 - The Future of Data Management By far one of the best analyses of trends in Data Management. 2023 predictions from the panel are; Unified metadata becomes kingmaker. The names hold less meaning to the outcome, but its fancy. link] All rights reserved ProtoGrowth Inc, India.
It is a data integration process with which you first extract raw information (in its original formats) from various sources and load it straight into a central repository such as a cloud data warehouse , a datalake , or a data lakehouse where you transform it into suitable formats for further analysis and reporting.
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for rawdata; a tool for large-scale data integration ; and. a suitable technology to implement datalake architecture.
In a DataOps architecture, it’s crucial to have an efficient and scalable data ingestion process that can handle data from diverse sources and formats. This requires implementing robust data integration tools and practices, such as data validation, data cleansing, and metadata management.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Zero ETL is a bit of a misnomer.
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. However, this approach quickly shows its limitations as data volume escalates.
Aside from video data from each camera-equipped store, Standard deals with other data sets such as transactional data, store inventory data that arrive in different formats from different retailers, and metadata derived from the extensive video captured by their cameras.
Now that we have understood how much significant role data plays, it opens the way to a set of more questions like How do we acquire or extract rawdata from the source? How do we transform this data to get valuable insights from it? Where do we finally store or load the transformed data?
It also offers a unique architecture that allows users to quickly build tables and begin querying data without administrative or DBA involvement. Snowflake is a cloud-based data platform that provides excellent manageability regarding data warehousing, datalakes, data analytics, etc. What Does Snowflake Do?
The rawdata is right there, ready to be reprocessed. All this rawdata goes into your persistent stage. Then, if you later refine your definition of what constitutes an “engaged” customer, having the rawdata in persistent staging allows for easy reprocessing of historical data with the new logic.
Big data operations require specialized tools and techniques since a relational database cannot manage such a large amount of data. Big data enables businesses to gain a deeper understanding of their industry and helps them extract valuable information from the unstructured and rawdata that is regularly collected.
Data Pipelines Datalakes continue to get new names in the same year, and it becomes imperative for data engineers to supplement their skills with data pipelines that help them work comprehensively with real-time streams, daily occurrence rawdata, and data warehouse queries.
Field and column names, data types, and variations in delimiters that designate fields. It should detect “schema drift,” and may involve operations that validate datasets against source system metadata, for example. For starters, we must acknowledge that to make your data usable, you have to process it. In the correct storage.
Within no time, most of them are either data scientists already or have set a clear goal to become one. Nevertheless, that is not the only job in the data world. And, out of these professions, this blog will discuss the data engineering job role. Upload it to Azure Datalake storage manually.
Data that can be stored in traditional database systems in the form of rows and columns, for example, the online purchase transactions can be referred to as Structured Data. Data that can be stored only partially in traditional database systems, for example, data in XML records can be referred to as semi-structured data.
Photo by Ian Taylor on Unsplash This tutorial guides you through an analytics use case, analyzing semi-structured data with Spark SQL. We’ll start with the data engineering process, pulling data from an API and finally loading the transformed data into a datalake (represented by MinIO ).
Unstructured data , on the other hand, is unpredictable and has no fixed schema, making it more challenging to analyze. Without a fixed schema, the data can vary in structure and organization. There are several widely used unstructured data storage solutions such as datalakes (e.g., Invest in data governance.
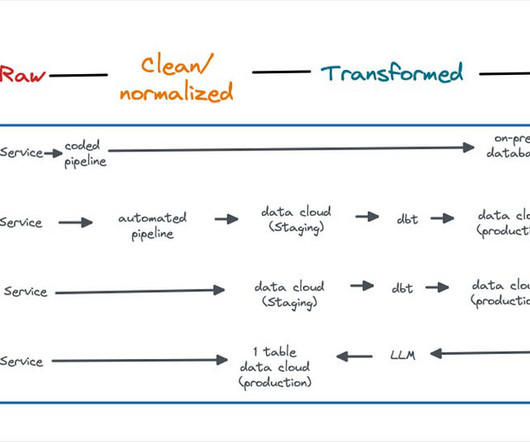
Zero-ETL What it is : A misnomer for one thing; the data pipeline still exists. Today, data is often generated by a service and written into a transactional database. An automatic pipeline is deployed which not only moves the rawdata to the analytical data warehouse, but modifies it slightly along the way.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content