This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
While data warehouses are still in use, they are limited in use-cases as they only support structureddata. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
Summary Working with unstructured data has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. CDP DataLake cluster versions – CM 7.4.0,
Before going into further details on Delta Lake, we need to remember the concept of DataLake, so let’s travel through some history. In theory, was just throwing everything inside Hadoop and later on writing jobs to process the data into the expected results, getting rid of complex data warehousing systems.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
A Better Way Forward: Cloudera’s Open Data Lakehouse Cloudera offers a solution to these challenges with its open data lakehouse, which combines the flexibility and scalability of datalake storage with data warehouse functionality to unify and simplify the management of cyber log data.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
This week, we got to think about our data ingestion design. We looked at the following: How do we ingest – ETL vs ELT Where do we store the data – Datalake vs data warehouse Which tool to we use to ingest – cronjob vs workflow engine NOTE : This weeks task requires good internet speed and good compute.
Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse? Let’s explore that last point a little more closely… Data versioning Raw vault stores the business process output in its applied state as raw hub, link, and satellite tables. Enter Snowpark !
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a datalake used to host large amounts of raw data.
You can leverage AWS Glue to discover, transform, and prepare your data for analytics. In addition to databases running on AWS, Glue can automatically find structured and semi-structureddata kept in your datalake on Amazon S3, data warehouse on Amazon Redshift, and other storage locations.
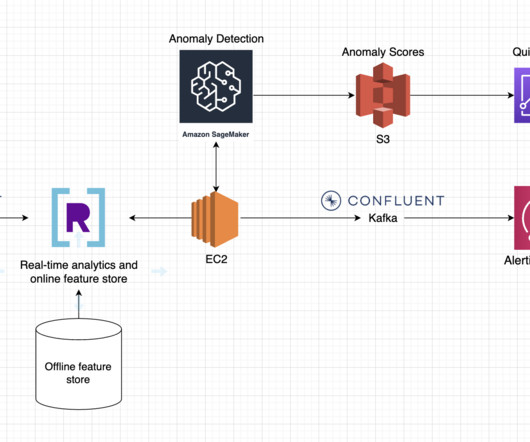
Offline feature store : Detecting anomalies requires historical data in order to have a baseline for comparisons. This data tends to be slow changing and is stored in an offline feature store. This could be a cloud data warehouse, a datalake, or a database. The database has two primary jobs.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. AWS Glue has a central metadata repository called the Glue catalog.
Data Architecture Data architecture is a composition of models, rules, and standards for all data systems and interactions between them. Data Catalog An organized inventory of data assets relying on metadata to help with data management. Database A collection of structureddata.
a runtime environment (sandbox) for classic business intelligence (BI), advanced analysis of large volumes of data, predictive maintenance , and data discovery and exploration; a store for raw data; a tool for large-scale data integration ; and. a suitable technology to implement datalake architecture.
From the perspective of data science, all miscellaneous forms of data fall into three large groups: structured, semi-structured, and unstructured. Key differences between structured, semi-structured, and unstructured data. Note, though, that not any type of web scraping is legal.
Built around a cloud data warehouse, datalake, or data lakehouse. Modern data stack tools are designed to integrate seamlessly with cloud data warehouses such as Redshift, Bigquery, and Snowflake, as well as datalakes or even the child of the first two — a data lakehouse.
In the last few decades, we’ve seen a lot of architectural approaches to building data pipelines , changing one another and promising better and easier ways of deriving insights from information. There have been relational databases, data warehouses, datalakes, and even a combination of the latter two.
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Think of an automatically updating encyclopedia for your data platform.
Today’s data landscape is characterized by exponentially increasing volumes of data, comprising a variety of structured, unstructured, and semi-structureddata types originating from an expanding number of disparate data sources located on-premises, in the cloud, and at the edge.
That’s because you don’t know how many target environments can be used to ingest data from your operational systems. Maybe, you first load data into a data warehouse and later go on to load data into a datalake. Cover schemas in data contracts. temperature).
With SQL, machine learning, real-time data streaming, graph processing, and other features, this leads to incredibly rapid big data processing. DataFrames are used by Spark SQL to accommodate structured and semi-structureddata. Calcite has chosen to stay out of the data storage and processing business.
Processing files in a Python UDF and Stored Procedure has piqued the interest of our data scientists and paves the way for automation of new, complex data pipelines.” Mike Tuck, Air Pollution Specialist Why unstructured data? Using a Python UDF, we were able to accomplish this task.
It also offers a unique architecture that allows users to quickly build tables and begin querying data without administrative or DBA involvement. Snowflake is a cloud-based data platform that provides excellent manageability regarding data warehousing, datalakes, data analytics, etc. What Does Snowflake Do?
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack. The three most popular solutions for data storage and compute include the data warehouse, datalake, and data lakehouse.
Aside from video data from each camera-equipped store, Standard deals with other data sets such as transactional data, store inventory data that arrive in different formats from different retailers, and metadata derived from the extensive video captured by their cameras.
They are applied to retrieve data from the source systems, perform transformations when necessary, and load it into a target system ( data mart , data warehouse, or datalake). So, why is data integration such a big deal? Connections to both data warehouses and datalakes are possible in any case.
Content-based systems largely depend on the metadata of items. The choice of storage depends on the type of data you’re going to use for recommendations in the first place. Or you may use a mix of different data repositories depending on the purposes. Users get limited to items similar to those they have previously consumed.
Data Variety Hadoop stores structured, semi-structured and unstructured data. RDBMS stores structureddata. Data storage Hadoop stores large data sets. RDBMS stores the average amount of data. Works with only structureddata. Hardware Hadoop uses commodity hardware.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content