This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable datasystems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Supercharge your business teams with customer data using Hightouch for Reverse ETL today.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in datalakes and lakehouses.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. What are the other systems that feed into and rely on the Trino/Iceberg service?
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Summary The Presto project has become the de facto option for building scalable open source analytics in SQL for the datalake. That leaves DataOps reactive to data quality issues and can make your consumers lose confidence in your data. lets you identify data quality issues and their root causes from a single dashboard.
This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution. SnowConvert is an easy-to-use code conversion tool that accelerates legacy relational database management system (RDBMS) migrations to Snowflake.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
Summary Building a well managed data ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
Summary Data engineering systems are complex and interconnected with myriad and often opaque chains of dependencies. In order to turn this into a tractable problem one approach is to define and enforce contracts between producers and consumers of data. Atlan is the metadata hub for your data ecosystem.
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. So you only need to store one copy of data for your streaming and Lakehouse. When to use Fluss vs Apache Pinot?
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly.
WhyLogs is a powerful library for flexibly instrumenting all of your datasystems to understand the entire lifecycle of your data from source to productionized model. Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. Kudos to the Grab team for building a docs-as-code system. The Grab blog delights me since I have tried to do this many times.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Stop struggling to speed up your datalake.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines? Stale dashboards?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines? Stale dashboards?
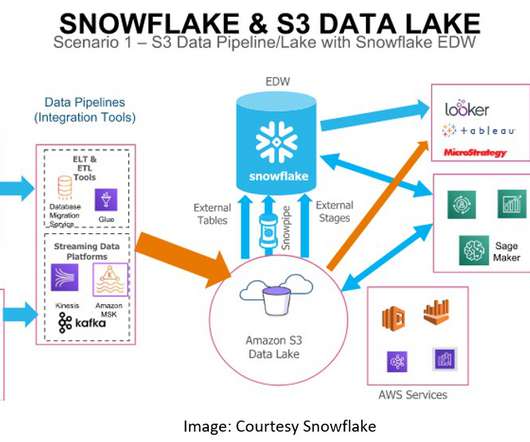
Read Time: 4 Minute, 23 Second During this post we will discuss how AWS S3 service and Snowflake integration can be used as DataLake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake DataLake capabilities. Create S3 bucket to hold the tables data.
Change Data Capture (CDC) has emerged as an ideal solution for near real-time movement of data from relational databases (like SQL Server or Oracle) to data warehouses, datalakes or other databases. Data can be extracted using database queries (batch-based) or Change Data Capture (near-real-time).
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies. I wonder if these systems expand more capabilities that eventually fall on their own weight.
In datasystems one of the core architectural exercises is data modeling, which can have significant impacts on what is and is not possible for downstream use cases. By incorporating column-level lineage in the data modeling process it encourages a more robust and well-informed design. ML, reverse ETL, etc.)
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. The technology for metadata management, data quality management, etc., No problem! is fairly advanced.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Cloudera has long had the capabilities of a data lakehouse, if not the label. 4-Ready for modern data fabric architectures. 4-Ready for modern data fabric architectures.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Can you explain how the Privacera platform is architected?
Learn More → Notion: Building and scaling Notion’s datalake Notion writes about scaling the datalake by bringing critical data ingestion operations in-house. Hudi seems to be a de facto choice for CDC datalake features. Notion migrated the insert heavy workload from Snowflake to Hudi.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
These formats are changing the way data is stored and metadata accessed. Apache Iceberg is a high-performance open table format developed for modern datalakes. Iceberg Data Catalog - an open-source metadata management system that tracks the schema, partition, and versions of Iceberg tables.
Unfortunately, with no formal specification, each project works slightly different which increases the difficulty of integration across systems. The Hive format is also built with the assumptions of a local filesystem which results in painful edge cases when leveraging cloud object storage for a datalake.
This CVD is built using Cloudera Data Platform Private Cloud Base 7.1.5 on Cisco UCS S3260 M5 Rack Server with Apache Ozone as the distributed file system for CDP. This has been a major architectural enhancement on how Apache Ozone manages data at scale in a datalake. . Data Generation at Scale.
Using the metaphor of a museum curator carefully managing the precious resources on display and in the vaults, he discusses the various layers of an enterprise data strategy. How do you define data curation? How does the size and maturity of a company affect the ways that they architect and interact with their datasystems?
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Because of its leading ecosystem of diverse adopters, contributors and commercial offerings, Iceberg helps prevent storage lock-in and eliminates the need to move or copy tables between different systems, which often translates to lower compute and storage costs for your overall data stack.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day.
This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. The Arrow project is designed to eliminate wasted effort in translating between languages, and Voltron Data was created to help grow and support its technology and community. Missing data? Stale dashboards?
Summary Working with unstructured data has typically been a motivation for a datalake. Kirk Marple has spent years working with datasystems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable. No more scripts, just SQL.
Summary Five years of hosting the Data Engineering Podcast has provided Tobias Macey with a wealth of insight into the work of building and operating datasystems at a variety of scales and for myriad purposes. Atlan is the metadata hub for your data ecosystem. Missing data? Struggling with broken pipelines?
Cloudera customers run some of the biggest datalakes on earth. These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise data warehouses. On data warehouses and datalakes.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content