This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary Working with unstructureddata has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
Beyond working with well-structured data in a data warehouse, modern AI systems can use deep learning and natural language processing to work effectively with unstructured and semi-structured data in datalakes and lakehouses.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Data stewards can also set up Request for Access (private preview) by setting a new visibility property on objects along with contact details so the right person can easily be reached to grant access.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructureddata, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. The technology for metadata management, data quality management, etc., No problem! is fairly advanced.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a DataLake? Consistency of data throughout the datalake.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Missing data? Atlan is the metadata hub for your data ecosystem. Struggling with broken pipelines?
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
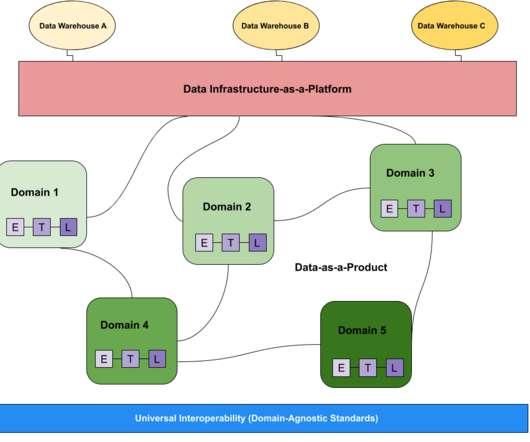
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
It offers a simple and efficient solution for data processing in organizations. It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, data warehouses, etc., being data exactly matches the classifier, and 0.0
The Solution: CDP Private Cloud brings a next-generation hybrid architecture with cloud-native benefits to HBL’s data platform. HBL started their data journey in 2019 when datalake initiative was started to consolidate complex data sources and enable the bank to use single version of truth for decision making.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Grab’s Metasense , Uber’s DataK9 , and Meta’s classification systems use AI to automatically categorize vast data sets, reducing manual efforts and improving accuracy. Beyond classification, organizations now use AI for automated metadata generation and data lineage tracking, creating more intelligent data infrastructures.
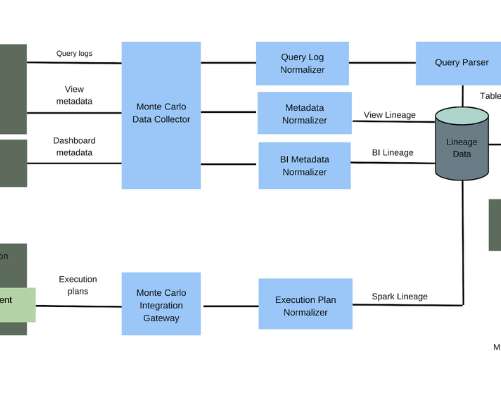
Metadata from the data warehouse/lake and from the BI tool of record can then be used to map the dependencies between the tables and dashboards. Integrating with it is the holy grail of Spark lineage because it contains all the information needed for how data moves through the datalake and how everything is connected.
Data Store Another significant change from 2021 to 2024 lies in the shift from “Data Warehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of DataLakes. This metadata is then utilized to manage, monitor, and foster the growth of the platform.
Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested. Imagine independently discovering rich new business insights from both structured and unstructureddata working together, without having to beg for data sets to be made available.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structured data and files/unstructureddata to the CDP cloud of their choice easily. CDP DataLake cluster versions – CM 7.4.0,
“California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files. Previously, working with these large and complex files would require a unique set of tools, creating data silos. ” U.S.
When implementing a data lakehouse, the table format is a critical piece because it acts as an abstraction layer, making it easy to access all the structured, unstructureddata in the lakehouse by any engine or tool, concurrently. Some of the popular table formats are Apache Iceberg, Delta Lake, Hudi, and Hive ACID.
Data lakehouse architecture combines the benefits of data warehouses and datalakes, bringing together the structure and performance of a data warehouse with the flexibility of a datalake. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1.
Data lakehouse architecture combines the benefits of data warehouses and datalakes, bringing together the structure and performance of a data warehouse with the flexibility of a datalake. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1.
Depending on the quantity of data flowing through an organization’s pipeline — or the format the data typically takes — the right modern table format can help to make workflows more efficient, increase access, extend functionality, and even offer new opportunities to activate your unstructureddata.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The collection of source data shown on your left is composed of both structured and unstructureddata from the organization’s internal and external sources.
If the transformation step comes after loading (for example, when data is consolidated in a datalake or a data lakehouse ), the process is known as ELT. You can learn more about how such data pipelines are built in our video about data engineering.
To help organizations realize the full potential of their datalake and lakehouse investments, Monte Carlo, the data observability leader, is proud to announce integrations with Delta Lake and Databricks’ Unity Catalog for full data observability coverage. billion in 2020 to 17.60 billion in 2020 to 17.60
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
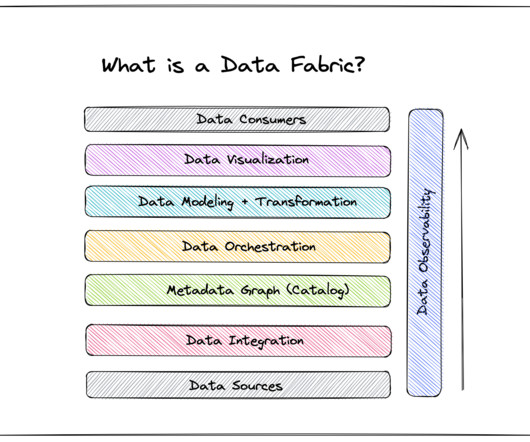
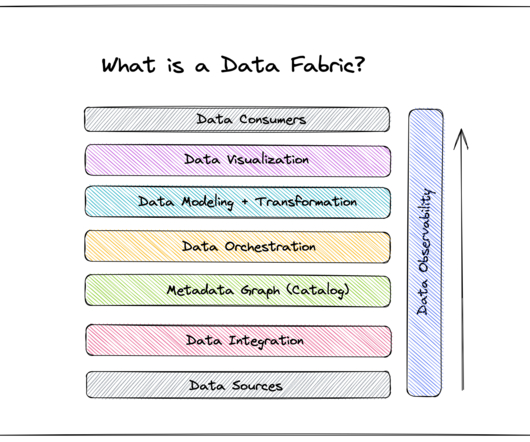
A data fabric is an architecture design presented as an integration and orchestration layer built on top of multiple disjointed data sources like relational databases , data warehouses , datalakes, data marts , IoT , legacy systems, etc., to provide a unified view of all enterprise data.
In this post, we’ll discuss what, exactly, a data fabric is, how other companies have used it, and how you can build one at your company. Table of Contents What is a data fabric? As your team builds your data fabric, make sure you have a designated way to collect the various metadata associated with your data inputs.
In this post, we’ll discuss what, exactly, a data fabric is, how other companies have used it, and how you can build one at your company. Table of Contents What is a data fabric? As your team builds your data fabric, make sure you have a designated way to collect the various metadata associated with your data inputs.
Over the past decade, Databricks and Apache Spark™ not only revolutionized how organizations store and process their data, but they also expanded what’s possible for data teams by operationalizing datalakes at an unprecedented scale across nearly infinite use cases. billion in 2020 to $17.6
Open source frameworks such as Apache Impala, Apache Hive and Apache Spark offer a highly scalable programming model that is capable of processing massive volumes of structured and unstructureddata by means of parallel execution on a large number of commodity computing nodes. . CRM platforms).
Unstructureddata not ready for analysis: Even when defenders finally collect log data, it’s rarely in a format that’s ready for analysis. Cyber logs are often unstructured or semi-structured, making it difficult to derive insights from them.
It serves as a foundation for the entire data management strategy and consists of multiple components including data pipelines; , on-premises and cloud storage facilities – datalakes , data warehouses , data hubs ;, data streaming and Big Data analytics solutions ( Hadoop , Spark , Kafka , etc.);
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
Perhaps one of the most significant contributions in data technology advancement has been the advent of “Big Data” platforms. Historically these highly specialized platforms were deployed on-prem in private data centers to ensure greater control , security, and compliance. OpEx savings and probable ROI once migrated.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content