This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
In this episode field CTO Manjot Singh shares his experiences as an early user of MySQL and MariaDB and explains how the suite of products being built on top of the open source foundation address the growing needs for advanced storage and analytical capabilities. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Summary The "data lakehouse" architecture balances the scalability and flexibility of datalakes with the ease of use and transaction support of data warehouses. Mention the podcast to get a free "In Data We Trust World Tour" t-shirt.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. Sifflet also offers a 2-week free trial.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. Sifflet also offers a 2-week free trial.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
It offers a simple and efficient solution for data processing in organizations. It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, data warehouses, etc., where it can be used to facilitate business decisions.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. Sifflet also offers a 2-week free trial.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Read More: Data Automation Engineer: Skills, Workflow, and Business Impact Python for Data Engineering Versus SQL, Java, and Scala When diving into the domain of data engineering, understanding the strengths and weaknesses of your chosen programming language is essential.
He currently runs a YouTube channel, E-Learning Bridge , focused on video tutorials for aspiring data professionals and regularly shares advice on data engineering, developer life, careers, motivations, and interviewing on LinkedIn.
Spark Architecture has three major components: API, Data Storage, and Management Framework. Spark provides APIs for the programming languages Java, Scala, and Python. Data Storage: Spark stores data using the HDFS file system. Any Hadoop-compatible data source, such as HDFS, HBase, and Cassandra , etc.,
It plays a key role in streaming in the form of Spark Streaming libraries, interactive analytics in the form of SparkSQL and also provides libraries for machine learning that can be imported using Python or Scala. Objective and Summary of the project: With so much use of online applications the inflow of data has increased exponentially.
Non-relational databases are ideal if you need flexibility for storing the data since you cannot create documents without having a fixed schema. E.g. PostgreSQL, MySQL, Oracle, Microsoft SQL Server. E.g. Redis, MongoDB, Cassandra, HBase , Neo4j, CouchDB What is data modeling? A data warehouse can contain unstructured data too.
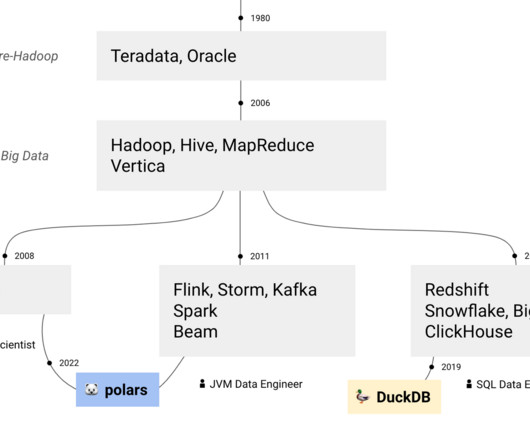
JVM vs. SQL data engineer — There's a big discussion in the community about what real data engineering is. Is it Java/Scala or Python? Is it lake or warehouse? It's a sterile debate: both are useful and can serve different organisations with different service level for data users and stakeholders.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content