This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Deploying upstream data profiling, validation, and cleansing rules was required to ensure garbage wasnt coming in, and suddenly organizations were discussing their plans for big data governance when they had yet to figure out how to implement little data governance. A datalake!
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
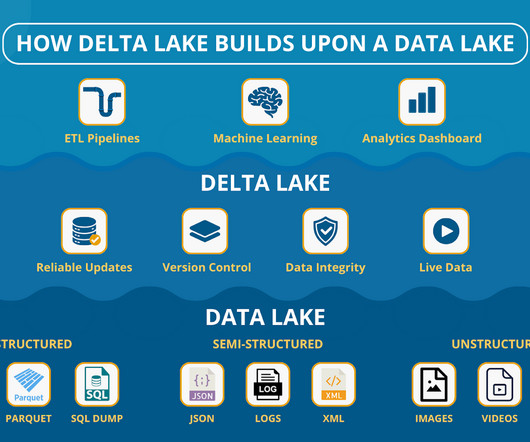
Datalakes turned into swamps , pipelines burst, and just when you thought youd earned a degree in hydrology, someone leaned in and whispered: Delta Lake. Are we building data dams next? Lets break it down and see when a plain datalake works and when youll want the extra reliability of Delta Lake.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
A datalake is essentially a vast digital dumping ground where companies toss all their rawdata, structured or not. An example of a data pipeline structure. But behind the scenes, Uber is also a leader in using data for business decisions, thanks to its optimized datalake.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? . Athena on AWS. .
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, rawdata was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
Summary Do you wish that you could track the changes in your data the same way that you track the changes in your code? Pachyderm is a platform for building a datalake with a versioned file system. Interview with Daniel Whitenack Introduction How did you get started in the data engineering space?
Data Lakehouse Pattern Data lakehouses are the sporks of architectural patterns – combining the best parts of data warehouses with datalakes. You get the structure and performance of a warehouse with the flexibility and scalability of a lake. The data lakehouse has got you covered!
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
One such tool is the Versatile Data Kit (VDK), which offers a comprehensive solution for controlling your data versioning needs. VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. Use VDK to build a datalake and merge multiple sources.
In this piece, we break down popular Iceberg use cases, advantages and disadvantages, and its impact on data quality so you can make the table format decision that’s right for your team. Is your datalake a good fit for Iceberg? Let’s dive in.
Figure 3 shows an example processing architecture with data flowing in from internal and external sources. Each data source is updated on its own schedule, for example, daily, weekly or monthly. The data scientists and analysts have what they need to build analytics for the user. Each of the mastered data sets could be a domain.
Data Ingestion. The rawdata is in a series of CSV files. We will firstly convert this to parquet format as most datalakes exist as object stores full of parquet files. RAPIDS is only supported on Pascal or newer NVIDIA GPUs. For AWS this means at least P3 instances. P2 GPU instances are not supported.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
And even when we manage to streamline the data workflow, those insights aren’t always accessible to users unfamiliar with antiquated business intelligence tools. That’s why ThoughtSpot and Fivetran are joining forces to decrease the amount of time, steps, and effort required to go from rawdata to AI-powered insights.
After evaluating numerous data solution providers, Databricks stood out due to its seamless performance and lakehouse capabilities, which offer the best of both datalakes and data warehouses. This vital information then streams to the XRPL Data Extractor App. Why Databricks Emerged as the Top Contender 1.
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
Extract and Load This phase includes VDK jobs calling the Europeana REST API to extract rawdata. You have just learned how to implement batch data processing in VDK! It only requires ingesting rawdata, manipulating it, and, finally, using it for your purposes! link] Summary Congratulations!
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken data pipelines. Start trusting your data with Monte Carlo today! constraints on data manipulation, security, privacy concerns, etc.)
The rise of distributed data architectures like Data Mesh will combine with DataOps automation to give rise to Hub-Spoke architectures that deftly blend the benefits of centralization and decentralization. For example, a Hub-Spoke architecture could integrate data from a multitude of sources into a datalake.
Data Store Another significant change from 2021 to 2024 lies in the shift from “Data Warehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of DataLakes.
Of high value to existing customers, Cloudera’s Data Warehouse service has a unique, separated architecture. . Cloudera’s Data Warehouse service allows rawdata to be stored in the cloud storage of your choice (S3, ADLSg2). When your IT admin registers an environment in CDP, a DataLake is automatically deployed.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse?
They make data workflows more resilient and easier to manage when things inevitably go sideways. This guide tackles the big decisions every data engineer faces: Should you clean your data before or after loading it? Datalake or warehouse? DataLakes vs. Data Warehouses: Where Should Your Data Live?
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses. How Does AWS Glue Work?
Summary The most complicated part of data engineering is the effort involved in making the rawdata fit into the narrative of the business. Data Engineering Podcast listeners can sign up for a free 2-week sandbox account, go to dataengineeringpodcast.com/tonic today to give it a try!
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
Mark: The first element in the process is the link between the source data and the entry point into the data platform. At Ramsey International (RI), we refer to that layer in the architecture as the foundation, but others call it a staging area, raw zone, or even a source datalake.
Resolution In order to meet the business requirements for a job market analysis platform & dashboard, WeCloudData helped the client leverage a suite of cloud platforms & tools to enable a data pipeline in multiple stages: Ingest job data from multiple sources and store the rawdata in a cloud datalake Process the rawdata with Python & (..)
Resolution In order to meet the business requirements for a job market analysis platform & dashboard, WeCloudData helped the client leverage a suite of cloud platforms & tools to enable a data pipeline in multiple stages: Ingest job data from multiple sources and store the rawdata in a cloud datalake Process the rawdata with Python & (..)
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content