This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction A datalake is a centralized and scalable repository storing structured and unstructureddata. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
The demand for higher data velocity, faster access and analysis of data as its created and modified without waiting for slow, time-consuming bulk movement, became critical to business agility. Which turned into datalakes and data lakehouses Poor data quality turned Hadoop into a data swamp, and what sounds better than a data swamp?
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
While data warehouses are still in use, they are limited in use-cases as they only support structured data. Datalakes add support for semi-structured and unstructureddata, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
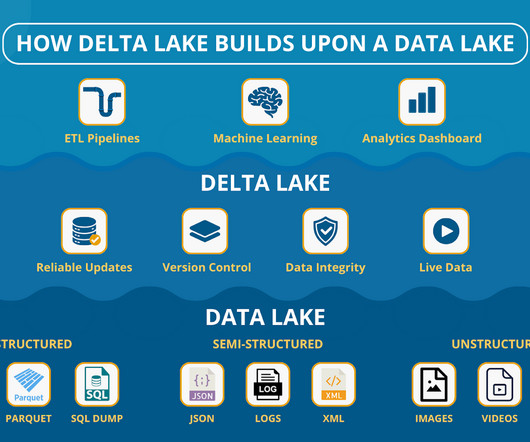
Datalakes turned into swamps , pipelines burst, and just when you thought youd earned a degree in hydrology, someone leaned in and whispered: Delta Lake. Are we building data dams next? Lets break it down and see when a plain datalake works and when youll want the extra reliability of Delta Lake.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuring data refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataLake? .
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
Learn how we build datalake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, rawdata was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
VDK helps you easily perform complex operations, such as data ingestion and processing from different sources, using SQL or Python. You can use VDK to build datalakes and ingest rawdata extracted from different sources, including structured, semi-structured, and unstructureddata.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake? What is a Datalake?
Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making. These data sources serve as the starting point for the pipeline, providing the rawdata that will be ingested, processed, and analyzed.
Data Store Another significant change from 2021 to 2024 lies in the shift from “Data Warehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of DataLakes.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructuredrawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
They make data workflows more resilient and easier to manage when things inevitably go sideways. This guide tackles the big decisions every data engineer faces: Should you clean your data before or after loading it? Datalake or warehouse? DataLakes vs. Data Warehouses: Where Should Your Data Live?
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse?
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Mark: While most discussions of modern data platforms focus on comparing the key components, it is important to understand how they all fit together. The collection of source data shown on your left is composed of both structured and unstructureddata from the organization’s internal and external sources.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Datalakes offer a scalable and cost-effective solution.
Secondly , the rise of datalakes that catalyzed the transition from ELT to ELT and paved the way for niche paradigms such as Reverse ETL and Zero-ETL. Still, these methods have been overshadowed by EtLT — the predominant approach reshaping today’s data landscape.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
To help organizations realize the full potential of their datalake and lakehouse investments, Monte Carlo, the data observability leader, is proud to announce integrations with Delta Lake and Databricks’ Unity Catalog for full data observability coverage. billion in 2020 to 17.60 billion in 2020 to 17.60
In broader terms, two types of data -- structured and unstructureddata -- flow through a data pipeline. The structured data comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
Power BI is a technology-driven business intelligence tool or an array of software services, apps, and connectors to convert unrelated and rawdata into visually immersive, coherent, actionable, and interactive insights and information. Microsoft developed it and combines business analytics, data visualization, and best practices.
It is a data integration process with which you first extract raw information (in its original formats) from various sources and load it straight into a central repository such as a cloud data warehouse , a datalake , or a data lakehouse where you transform it into suitable formats for further analysis and reporting.
The difference here is that warehoused data is in its raw form, with the transformation only performed on-demand following information access. Another benefit is that this approach supports optimizing the data transforming processes all analytical processing evolves. featured image via unsplash
The modern data stack era , roughly 2017 to present data, saw the widespread adoption of cloud computing and modern data repositories that decoupled storage from compute such as data warehouses, datalakes, and data lakehouses. Zero ETL is a bit of a misnomer.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a datalake used to host large amounts of rawdata.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
Variety One of the biggest advancements in recent years in regards to data platforms is the ability to extract data from storage silos and into a datalake. This obviously introduces a number of problems for businesses who want to make sense of this data because it’s now arriving in a variety of formats and speeds.
With companies moving their data platforms to the cloud, the emergence of cloud-native solutions ( data warehouse vs datalake or even a data lakehouse ) have taken over the market, offering more accessible and affordable options for storing data relative to many on-premises solutions.
Often, the extraction process includes checks and balances to verify the accuracy and completeness of the extracted data. The Load Phase After the data is extracted, it’s loaded into a data storage system in the load phase. The data is loaded as-is, without any transformation.
Data pipelines can handle both batch and streaming data, and at a high-level, the methods for measuring data quality for either type of asset are much the same. In many ways, the cloud makes data easier to manage, more accessible to a wider variety of users, and far faster to process.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content