This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structureddata management that really hit its stride in the early 1990s.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
The alternative, however, provides more multi-cloud flexibility and strong performance on structureddata. It incorporates elements from several Microsoft products working together, like Power BI, Azure Synapse Analytics, Data Factory, and OneLake, into a single SaaS experience.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
While data warehouses are still in use, they are limited in use-cases as they only support structureddata. Datalakes add support for semi-structured and unstructured data, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
A datalake is a central storage place for an organization’s data in its original format. Unlike data warehouses, datalakes can handle all kinds of data, including unstructured and semi-structureddata like images, video, audio, and documents.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. What is DataLake? .
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
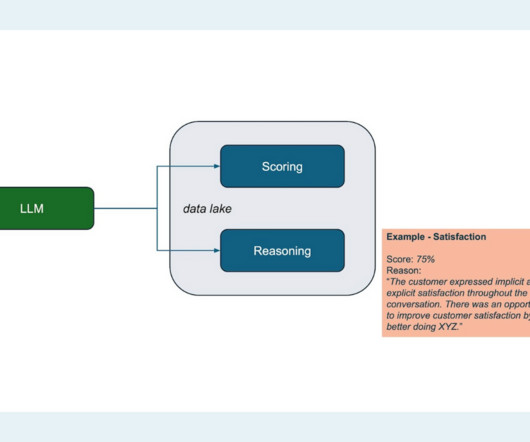
Using the LLM to create a scoring model To build the LLM-based product, the Assurance team leveraged their contextual conversation data in their S3 datalake using a combination of proprietary and open source third party models hosted in AWS Bedrock, Azure OpenAI, and more.
Your host is Tobias Macey and today I’m interviewing Eldad Farkash about Firebolt, a cloud data warehouse optimized for speed and elasticity on structured and semi-structureddata Interview Introduction How did you get involved in the area of data management?
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
What are some of the foundational skills and knowledge that are necessary for effective modeling of data warehouses? How has the era of datalakes, unstructured/semi-structureddata, and non-relational storage engines impacted the state of the art in data modeling?
Data Lakehouse Pattern Data lakehouses are the sporks of architectural patterns – combining the best parts of data warehouses with datalakes. You get the structure and performance of a warehouse with the flexibility and scalability of a lake. The data lakehouse has got you covered!
Without meeting GxP compliance, the Merck KGaA team could not run the enterprise datalake needed to store, curate, or process the data required to inform business decisions. It established a data governance framework within its enterprise datalake. Driving innovation with secure and governed data .
Intractability of Testing: Even simpler queries require a larger, complex object graph of test dataLake of reusable business logic: CTE & Views are there, but not as efficient as functions in high-level languages. [link] Fernando Borretti: Composable SQL One of the biggest challenges in SQL is the unit testing.
Proficiency in Programming Languages Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike. In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
Before going into further details on Delta Lake, we need to remember the concept of DataLake, so let’s travel through some history. In theory, was just throwing everything inside Hadoop and later on writing jobs to process the data into the expected results, getting rid of complex data warehousing systems.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. CDP DataLake cluster versions – CM 7.4.0,
Summary Working with unstructured data has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
New data formats emerged — JSON, Avro, Parquet, XML etc. Datalakes were introduced to store the new data formats. Image by the author 2010 to 2020 - The Cloud Data Warehouse Enterprises now wanted quick data analytics without yesterday’s constraints of flexibility, processing power and scale.
What is a datalake, and how does it differ from a data warehouse? Datalakes contain raw, unstructured data of an organization, which can be stored indefinitely – either immediately or in the future.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
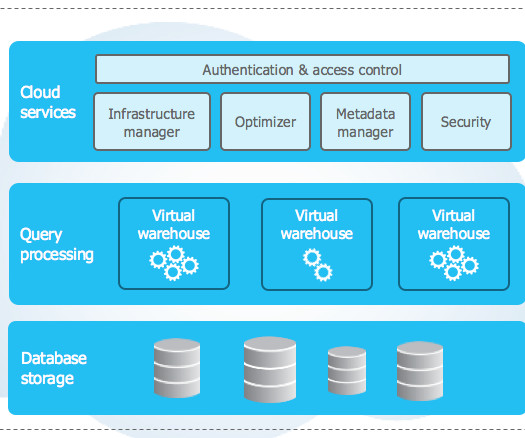
Snowflake Data Warehouse delivers essential infrastructure for handling a DataLake, and Data Warehouse needs. It can store semi-structured and structureddata in one place due to its multi-clusters architecture that allows users to independently query data using SQL.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like datalakes.
Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance. Data mart vs data warehouse vs datalake vs OLAP cube. Datalakes, data warehouses, and data marts are all data repositories of different sizes.
link] LinkedIn: LakeChime - A Data Trigger Service for Modern DataLakes LinkedIn points out two critical flaws in a partitioned approach to data management. The granularity of partition creation constrained data consumption. However, the Map and Array comes with its cost.
Key connectivity features include: Data Ingestion: Databricks supports data ingestion from a variety of sources, including datalakes, databases, streaming platforms, and cloud storage. This flexibility allows organizations to ingest data from virtually anywhere.
“Enterprises are more mature in managing the quality of structureddata than newer data types.” Organizations are adept at managing the quality of structureddata, but management of unstructured and semi-structureddata is less mature. • Invest in training and culture.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content