This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structureddata management that really hit its stride in the early 1990s.
Introduction A datalake is a centralized and scalable repository storing structured and unstructureddata. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
The trend to centralize data will accelerate, making sure that data is high-quality, accurate and well managed. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
Summary Working with unstructureddata has typically been a motivation for a datalake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Data Storage Solutions As we all know, data can be stored in a variety of ways.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
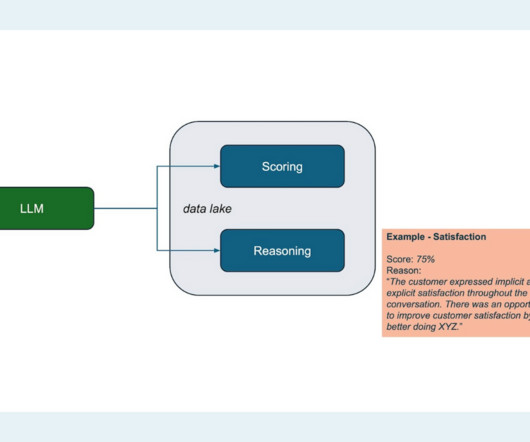
We recently spoke with Killian Farrell , Principal Data Scientist at insurance startup AssuranceIQ to learn how his team built an LLM-based product to structureunstructureddata and score customer conversations for developing sales and customer support teams. Read on to find out what they did, and what they learned!
While data warehouses are still in use, they are limited in use-cases as they only support structureddata. Datalakes add support for semi-structured and unstructureddata, and data lakehouses add further flexibility with better governance in a true hybrid solution built from the ground-up.
[link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI. It brings challenges in data processing and quality, but what data quality means in unstructureddata is a top question for every organization.
The terms “ Data Warehouse ” and “ DataLake ” may have confused you, and you have some questions. Structuringdata refers to converting unstructureddata into tables and defining data types and relationships based on a schema. What is DataLake? .
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a datalake and a data warehouse. What is a Data Warehouse? What is a DataLake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Data discovery tools and platforms can help.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a DataLake? Consistency of data throughout the datalake.
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Without meeting GxP compliance, the Merck KGaA team could not run the enterprise datalake needed to store, curate, or process the data required to inform business decisions. It established a data governance framework within its enterprise datalake. Driving innovation with secure and governed data .
“California Air Resources Board has been exploring processing atmospheric data delivered from four different remote locations via instruments that produce netCDF files. Previously, working with these large and complex files would require a unique set of tools, creating data silos. ” U.S.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making.
What is a datalake, and how does it differ from a data warehouse? Datalakes contain raw, unstructureddata of an organization, which can be stored indefinitely – either immediately or in the future.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructureddata to the CDP cloud of their choice easily. CDP DataLake cluster versions – CM 7.4.0,
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
Datalakes, data warehouses, data hubs, data lakehouses, and data operating systems are data management and storage solutions designed to meet different needs in data analytics, integration, and processing. This feature allows for a more flexible exploration of data.
A common pitfall in the development of data platforms is that they are built around the boundaries of point solutions and are constrained by the technological limitations (e.g., a technology choice such as Spark Streaming is overly focused on throughput at the expense of latency) or data formats (e.g., data warehousing).
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
In our previous post, The Pros and Cons of Leading Data Management and Storage Solutions , we untangled the differences among datalakes, data warehouses, data lakehouses, data hubs, and data operating systems. Consider whether you need a solution that supports one or multiple data formats.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Here are a couple of resources to learn more: Data Talks Club Data Ingestion Week Coder2J Airflow Tutorial Data Storage In the context of data engineering, data storage refers to the systems and technologies that are used to store and manage data within an organization.
In this blog post, we’ll look at six innovations that are shaping the future of the data warehousing, as well as challenges and considerations that organizations should keep in mind. Datalake and data warehouse convergence 2. Easier to stream real-time data 3. Zero-copy data sharing 4.
Since data marts provide analytical capabilities for a restricted area of a data warehouse, they offer isolated security and isolated performance. Data mart vs data warehouse vs datalake vs OLAP cube. Datalakes, data warehouses, and data marts are all data repositories of different sizes.
One of the innovative ways to address this problem is to build a data hub — a platform that unites all your information sources under a single umbrella. This article explains the main concepts of a data hub, its architecture, and how it differs from data warehouses and datalakes. What is Data Hub?
From the perspective of data science, all miscellaneous forms of data fall into three large groups: structured, semi-structured, and unstructured. Key differences between structured, semi-structured, and unstructureddata.
Based on Tecton blog So is this similar to data engineering pipelines into a datalake/warehouse? Schema drift on a wide table structure needs an ALTER TABLE statement, whereas the tall table structure does not. These methods can be applied to structured and semi-structureddata as well.
Organizations can harness the power of the cloud, easily scaling resources up or down to meet their evolving data processing demands. Supports Structured and UnstructuredData: One of Azure Synapse's standout features is its versatility in handling a wide array of data types.
Unstructureddata not ready for analysis: Even when defenders finally collect log data, it’s rarely in a format that’s ready for analysis. Cyber logs are often unstructured or semi-structured, making it difficult to derive insights from them.
The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both datalakes and data warehouses and this post will explain this all. What is a data lakehouse? Data warehouse vs datalake vs data lakehouse: What’s the difference.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structureddata, and a datalake used to host large amounts of raw data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content