This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how datamanagement is done. Pandera, a datavalidation library for dataframes, now supports Polars. This is Croissant.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
However, they require a strong data foundation to be effective. With the rise of cloud-based datamanagement, many organizations face the challenge of accessing both on-premises and cloud-based data. Without a unified, clean data structure, leveraging these diverse data sources is often problematic.
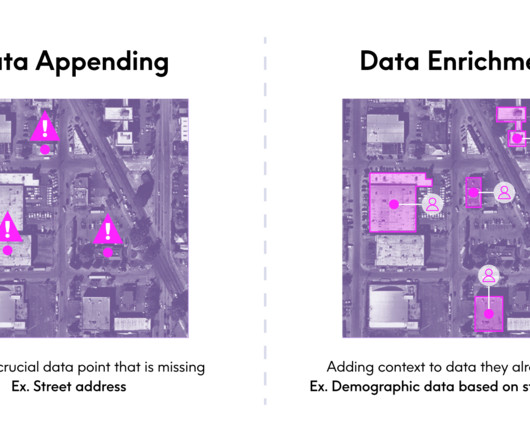
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment.
Project Idea: Start data engineering pipeline by sourcing publicly available or simulated Uber trip datasets, for example, the TLC Trip record dataset.Use Python and PySpark for data ingestion, cleaning, and transformation. This project will help analyze user data for actionable insights.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view.
However, they require a strong data foundation to be effective. With the rise of cloud-based datamanagement, many organizations face the challenge of accessing both on-premises and cloud-based data. Without a unified, clean data structure, leveraging these diverse data sources is often problematic.
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. Learn more in our detailed guide to data reliability 6 Pillars of Data Quality 1.
Security at the row level (RLS) By limiting access to particular data rows according to user roles, RLS improves data security without creating duplicate datasets. After that, we’ll examine Microsoft Fabric Architecture: Integration Templates.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex. Can you start by sharing some of your experiences with data migration projects? Closing Announcements Thank you for listening! Don't forget to check out our other shows.
Both assist in saving on expenses spent on storing such large datasets and offer functionalities that assist in effectively analyzing those datasets. Besides that, they are supported by a strongly-knit community of engineers contributing to novel advancements in managing and analyzing large datasets.
Data Redundancy Data duplication during data migration can occur when generating staging or intermediate datasets. Understanding the connections between the data fields in depth is crucial for properly identifying and managing such duplicate data. For transferring data from one flat file (.csv,txt),
Successful candidates demonstrate their ability to process data and follow the best security practices incrementally. The exam evaluates skills in modeling datamanagement solutions and implementing best practices for code management, testing, and deployment.
Databand — Data pipeline performance monitoring and observability for data engineering teams. . Soda Data Monitoring — Soda tells you which data is worth fixing. Soda doesn’t just monitor datasets and send meaningful alerts to the relevant teams. Observe, optimize, and scale enterprise data pipelines. .
.” – Reynold Xin Simplifying complex data becomes easier with these best practices. These practices are not just guidelines; they are the secret to transforming messy datasets into streamlined workflows. So, get ready to explore the key practices shaping the future of data engineering.
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
Larger companies require more time for transferring data using storage migration. Storage migration also involves datavalidation, duplication, cleaning, etc. Application Migration When investing in one, an organization must transfer all data into a new software system. Gain a Clear Understanding of the Data.
Define Big Data and Explain the Seven Vs of Big Data. Big Data is a collection of large and complex semi-structured and unstructured data sets that have the potential to deliver actionable insights using traditional datamanagement tools. MapReduce is a Hadoop framework used for processing large datasets.
The concurrent queries will not see the effect of the data loads until the data load is complete, creating 10s of minutes of data lags. OLTP databases aren’t built to ingest massive volumes of data streams and perform stream processing on incoming datasets. So they are not suitable for real-time analytics.
Thus, Data Wrangling is essential for businesses as it ensures that the data is accurate, consistent, and usable for analysis. In simple terms, Data Wrangling is standardizing, cleaning, and transforming raw datasets into a more understandable format so that data scientists can analyze them properly.
Data Profiling 2. Data Cleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Use of Data Quality Tools Refresh your intrinsic data quality with data observability 1. Data Profiling Data profiling is getting to know your data, warts and quirks and secrets and all.
Table of Contents What Does an AI Data Quality Analyst Do? Essential Skills for an AI Data Quality Analyst There are several important skills an AI Data Quality Analyst needs to know in order to successfully ensure and maintain accurate, reliable AI models. Machine Learning Basics : Understanding how data impacts model training.
As organizations seek to leverage data more effectively, the focus has shifted from temporary datasets to well-defined, reusable data assets. Data products transform raw data into actionable insights, integrating metadata and business logic to meet specific needs and drive strategic decision-making.
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools.
This includes defining roles and responsibilities related to managingdatasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Additionally, high-quality data reduces costly errors stemming from inaccurate information.
High-quality data, free from errors, inconsistencies, or biases, forms the foundation for accurate analysis and reliable insights. Data products should incorporate mechanisms for datavalidation, cleansing, and ongoing monitoring to maintain data integrity.
Learning SQL can help data engineers work more effectively with data analysts and data scientists as they share a common language for querying and analysing data. Data processing tasks containing SQL-based data transformations can be conducted utilizing Hadoop or Spark executors by ETL solutions.
By routinely conducting data integrity tests, organizations can detect and resolve potential issues before they escalate, ensuring that their data remains reliable and trustworthy. Data integrity monitoring can include periodic data audits, automated data integrity checks, and real-time datavalidation.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
To maximize your investments in AI, you need to prioritize data governance, quality, and observability. Solving the Challenge of Untrustworthy AI Results AI has the potential to revolutionize industries by analyzing vast datasets and streamlining complex processes – but only when the tools are trained on high-quality data.
In this article, we’ll recap the key takeaways from the summit and the groundbreaking advancements in data pipeline automation that we’re working on at Ascend. Link data products within and across data clouds , allowing users to access and analyze data in a unified, consistent manner.
Their efforts make ensuring that data is accurate, dependable, and consistent, laying the groundwork for data analysis and decision-making. What does a Data Processing Analysts do ? A data processing analyst’s job description includes a variety of duties that are essential to efficient datamanagement.
There is no mention of datamanagement in general, but mainly of usage and operational factors. Nothing groundbreaking will happen on datamanagement in 2023, but I expect a little momentum behind datamanagement towards the end.
The value of that trust is why more and more companies are introducing Chief Data Officers – with the number doubling among the top publicly traded companies between 2019 and 2021, according to PwC. In this article: Why is data reliability important? Note that datavalidity is sometimes considered a part of data reliability.
Constant Data And Tool Errors In Production Teams cannot see across all tools, pipelines, jobs, processes, datasets, and people. No Time For DataValidation Testing Teams must learn what, where, and how to check raw, integrated, or ‘data in use’ to ensure the correct outputs.
High-quality data, free from errors, inconsistencies, or biases, forms the foundation for accurate analysis and reliable insights. Data products should incorporate mechanisms for datavalidation, cleansing, and ongoing monitoring to maintain data integrity.
High-quality data, free from errors, inconsistencies, or biases, forms the foundation for accurate analysis and reliable insights. Data products should incorporate mechanisms for datavalidation, cleansing, and ongoing monitoring to maintain data integrity.
Another way data ingestion enhances data quality is by enabling data transformation. During this phase, data is standardized, normalized, and enriched. Data enrichment involves adding new, relevant information to the existing dataset, which provides more context and improves the depth and value of the data.
The key features of the Data Load Accelerator include: Minimal and reusable coding: The model used is configuration-based and all data load requirements will be managed with one code base. Snowflake allows the loading of both structured and semi-structured datasets from cloud storage.
Equipped with built-in connectors, robust error-handling mechanisms, and capabilities to process data in near real-time, automated ETL pipelines not only enhance the speed of data integration but also ensure a higher degree of accuracy and reliability. A more agile, responsive, and error-resistant datamanagement process.
As a result, data virtualization enabled the company to conduct advanced analytics and data science, contributing to the growth of the business. Global investment bank: Cost reduction with more scalable and effective datamanagement. How to get started with data virtualization. Know your data sources.
But in reality, a data warehouse migration to cloud solutions like Snowflake and Redshift requires a tremendous amount of preparation to be successful—from schema changes and datavalidation to a carefully executed QA process. What’s more, issues in the source data could even be amplified by a new, sophisticated system.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content