This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a datawarehouse The datawarehouse (DW) was an approach to data architecture and structured datamanagement that really hit its stride in the early 1990s.
In this episode Priyendra Deshwal explains how NetSpring is designed to empower your product and data teams to build and explore insights around your products in a streamlined and maintainable workflow. Contact Info LinkedIn Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today?
A few months ago, I uploaded a video where I discussed datawarehouses, data lakes, and transactional databases. However, the world of datamanagement is evolving rapidly, especially with the resurgence of AI and machine learning.
Summary There is a lot of attention on the database market and cloud datawarehouses. While they provide a measure of convenience, they also require you to sacrifice a certain amount of control over your data. Firebolt is the fastest cloud datawarehouse. Visit dataengineeringpodcast.com/firebolt to get started.
Over the years, the technology landscape for datamanagement has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Customers that require a hybrid of these to support many different tools and languages have built a data lakehouse.
In this episode Emily Riederer shares her work to create a controlled vocabulary for managing the semantic elements of the datamanaged by her team and encoding it in the schema definitions in her datawarehouse. star/snowflake schema, data vault, etc.) What do you have planned for the future of dbtplyr?
Summary The datawarehouse has become the focal point of the modern data platform. With increased usage of data across businesses, and a diversity of locations and environments where data needs to be managed, the warehouse engine needs to be fast and easy to manage.
In this episode DeVaris Brown discusses the types of applications that are possible when teams don't have to manage the complex infrastructure necessary to support continuous data flows. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). To start, can you share your definition of what constitutes a "Data Lakehouse"? Closing Announcements Thank you for listening!
When most people think of master datamanagement, they first think of customers and products. But master data encompasses so much more than data about customers and products. Challenges of Master DataManagement A decade ago, master datamanagement (MDM) was a much simpler proposition than it is today.
In this episode Crux CTO Mark Etherington discusses the different costs involved in managing external data, how to think about the total return on investment for your data, and how the Crux platform is architected to reduce the toil involved in managing third party data. Tired of deploying bad data?
He describes how the platform is architected, the challenges related to selling cloud technologies into enterprise organizations, and how you can adopt Matillion for your own workflows to reduce the maintenance burden of data integration workflows. No more shipping and praying, you can now know exactly what will change in your database!
In recent years, Meta’s datamanagement systems have evolved into a composable architecture that creates interoperability, promotes reusability, and improves engineering efficiency. Data is at the core of every product and service at Meta. Data is at the core of every product and service at Meta.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement RudderStack helps you build a customer data platform on your warehouse or data lake. Can you describe what SQLMesh is and the story behind it? DataOps is a term that has been co-opted and overloaded.
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how datamanagement is done. Pandera, a data validation library for dataframes, now supports Polars.
This new convergence helps Meta and the larger community build datamanagement systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how datamanagement systems are designed.
When it was difficult to wire together the event collection, data modeling, reporting, and activation it made sense to buy monolithic products that handled every stage of the customer data lifecycle. Now that the datawarehouse has taken center stage a new approach of composable customer data platforms is emerging.
Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today? Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
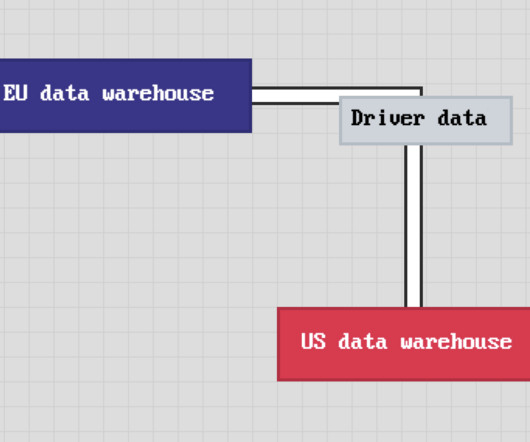
This truth was hammered home recently when ride-hailing giant Uber found itself on the receiving end of a staggering €290 million ($324 million) fine from the Dutch Data Protection Authority. Poor datawarehouse governance practices that led to the improper handling of sensitive European driver data. The reason?
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Summary Cloud datawarehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used.
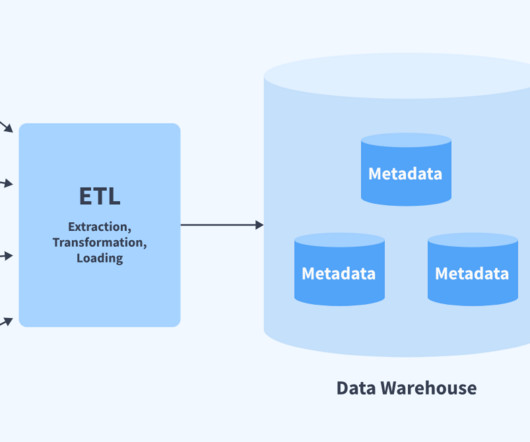
Over the past decade, we have gained a deeper understanding of our data, by embedding privacy considerations into every stage of product development, ensuring a more secure and responsible approach to datamanagement. Consider the data flow from online systems to the datawarehouse, as shown in the diagram below.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement RudderStack helps you build a customer data platform on your warehouse or data lake. Can you describe what Agile Data Engine is and the story behind it? RudderStack also supports real-time use cases.
Ghalib Suleiman has been on both sides of this equation and joins the show to share his hard-won wisdom about how to start and grow a data team in the early days of company growth. Can you start by sharing your conception of the responsibilities of a data team? When is it more practical to outsource the data work?
In this episode Tasso Argyros, CEO of ActionIQ, gives a summary of the major epochs in database technologies and how he is applying the capabilities of cloud datawarehouses to the challenge of building more comprehensive experiences for end-users through a modern customer data platform (CDP).
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. Databricks is focusing on simplification (serverless, auto BI 2 , improved PySpark) while evolving into a datawarehouse.
Nowadays, when it comes to datamanagement, every business has to make one critical decision: whether to use a Data Mesh or a DataWarehouse. Both are strong datamanagement architectures, but they are designed to support different needs and various organizational structures.
In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time data lake without all of the headache. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines.
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex.
In this episode Vinoth shares the history of the project, how its architecture allows for building more frequently updated analytical queries, and the work being done to add a more polished experience to the data lake paradigm. RudderStack’s smart customer data pipeline is warehouse-first.
In this episode the host Tobias Macey shares his reflections on recent experiences where the abstractions leaked and some observances on how to deal with that situation in a data platform architecture. What do you have planned for the future of your data platform? What do you have planned for the future of your data platform?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement This episode is supported by Code Comments, an original podcast from Red Hat. Data observability has been gaining adoption for a number of years now, with a large focus on datawarehouses.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
In this episode he shares his thoughts on the strategic and tactical elements of moving your work as a data professional from being task-oriented to being product-oriented and the long term improvements in your productivity that it provides. RudderStack helps you build a customer data platform on your warehouse or data lake.
In this episode Paul Blankley and Ryan Janssen explore the power of natural language driven data exploration combined with semantic modeling that enables an intuitive way for everyone in the business to access the data that they need to succeed in their work. Can you describe what Zenlytic is and the story behind it?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData and analytics leaders, 2023 is your year to sharpen your leadership skills, refine your strategies and lead with purpose. Missing data? Can you describe what the SQLake product is and the story behind it?
In this episode Srujan Akula explains how the system is implemented and how you can start using it today with your existing data systems. Trusted by the data teams at Fox, JetBlue, and PagerDuty, Monte Carlo solves the costly problem of broken data pipelines. Your flagship (only?) What is the scope and goal of that platform?
This is not surprising when you consider all the benefits, such as reducing complexity [and] costs and enabling zero-copy data access (ideal for centralizing data governance). Commercially, we heard AI use cases around treasury services, fraud detection and risk analytics.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Datamanagement recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you're ready to build your next pipeline, or want to test out the projects you hear about on the show, you'll need somewhere to deploy it, so check out our friends at Linode. or any other destination you choose.
As a result, lakehouses support more dynamic and flexible data architectures, catering to a broader range of analytics and operational workloads. For instance, in a fast-paced retail environment, lakehouses can ensure that inventory data remains up-to-date and accurate in the datawarehouse, optimizing supply chain efficiency.
Summary Cloud datawarehouses and the introduction of the ELT paradigm has led to the creation of multiple options for flexible data integration, with a roughly equal distribution of commercial and open source options. The challenge is that most of those options are complex to operate and exist in their own silo.
In this episode Mark Grover explains what he is building at Stemma, how it expands on the success of the Amundsen project, and why trust is the most important asset for data teams. RudderStack’s smart customer data pipeline is warehouse-first. RudderStack’s smart customer data pipeline is warehouse-first.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content