This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadatamanagement to attribute better Snowflake cost. Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how datamanagement is done.
Over the years, the technology landscape for datamanagement has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. Customers that require a hybrid of these to support many different tools and languages have built a data lakehouse.
Summary A significant source of friction and wasted effort in building and integrating datamanagement systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
In this episode Crux CTO Mark Etherington discusses the different costs involved in managing external data, how to think about the total return on investment for your data, and how the Crux platform is architected to reduce the toil involved in managing third party data. Tired of deploying bad data?
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern datamanagement.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today? Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses.
Snowflake was founded in 2012 around its datawarehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Summary Cloud datawarehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used.
In this episode Shinji Kim discusses the challenges of data discovery and how to collect and preserve additional context about each piece of information so that you can find what you need when you don’t even know what you’re looking for yet. What do you have planned for the future of SelectStar?
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your data workflows. Atlan is the metadata hub for your data ecosystem. Missing data? Struggling with broken pipelines?
In this episode she shares the strategic and tactical elements of how to make more effective use of the technical and organizational resources that are available to you for getting work done with data. Atlan is the metadata hub for your data ecosystem. Missing data? Struggling with broken pipelines? Stale dashboards?
This ecosystem includes: Catalogs: Services that managemetadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managingmetadata.
This new convergence helps Meta and the larger community build datamanagement systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how datamanagement systems are designed.
Track data files within the table along with their column statistics. Open table formats enable efficient datamanagement and retrieval by storing these files chronologically, with a history of DDL and DML actions and an index of data file locations. It can also be integrated into major data platforms like Snowflake.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
In this episode Isaac Brodsky explains how the Unfolded platform is architected, their experience joining the team at Foursquare, and how you can start using it for analyzing your spatial data today. Atlan is the metadata hub for your data ecosystem. Unstruk is the DataOps platform for your unstructured data.
He explains the constraints that he and his team are faced with and the various challenges that they have overcome to build useful data products on top of a legacy platform where they don’t control the end-to-end systems. Atlan is the metadata hub for your data ecosystem. Closing Announcements Thank you for listening!
Summary Building a well manageddata ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
In this episode he shares the goals of the Unstruk DataWarehouse, how it is architected to extract asset metadata and build a searchable knowledge graph from the information, and the myriad ways that the system can be used. Hightouch is the easiest way to sync data into the platforms that your business teams rely on.
Summary Data governance is a practice that requires a high degree of flexibility and collaboration at the organizational and technical levels. The growing prominence of cloud and hybrid environments in datamanagement adds additional stress to an already complex endeavor. What do you have planned for the future of Privacera?
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
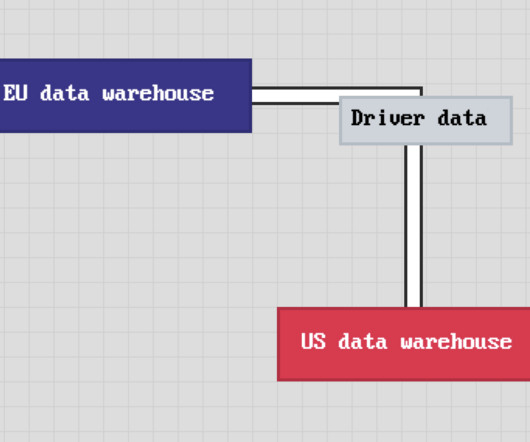
This truth was hammered home recently when ride-hailing giant Uber found itself on the receiving end of a staggering €290 million ($324 million) fine from the Dutch Data Protection Authority. Poor datawarehouse governance practices that led to the improper handling of sensitive European driver data. The reason?
In this episode Satish Jayanthi explores the benefits of incorporating column-aware tooling in the data modeling process. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement RudderStack helps you build a customer data platform on your warehouse or data lake.
Data volume and velocity, governance, structure, and regulatory requirements have all evolved and continue to. Despite these limitations, datawarehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications.
The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform. The metadata repository serves as a data catalog and a means of reporting on the health and status of your datasets when it is properly integrated into the rest of your tools.
Our investments in a lakeless datawarehouse, modern analytics platform, and strong master data practices have made data a core strategic capability. The Turning Point: Year3 At Picnic we had a DataWarehouse from the start, from the very first order. The challenges were multi-dimensional (pun intended).
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Datamanagement recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle. There are two main options available, a data lake and a datawarehouse. What is a DataWarehouse? What is a Data Lake?
She also discusses her views on the role of the data lakehouse as a building block for these architectures and the ongoing influence that it will have as the technology matures. Atlan is the metadata hub for your data ecosystem. Modern data teams are dealing with a lot of complexity in their data pipelines and analytical code.
This includes modeling the lifecycle of your information as a pipeline from the raw, messy, loosely structured records in your data lake, through a series of transformations and ultimately to your datawarehouse. How do you define data curation?
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or datawarehouse table that you are working with. Atlan is the metadata hub for your data ecosystem. Can you describe what Manta is and the story behind it?
In order to condense that acquired knowledge into a format that is useful to everyone Scott Hirleman turns the tables in this episode and asks Tobias about the tactical and strategic aspects of his experiences applying those lessons to the work of building a data platform from scratch. Atlan is the metadata hub for your data ecosystem.
In this episode Wes McKinney shares the ways that Arrow and its related projects are improving the efficiency of data systems and driving their next stage of evolution. Atlan is the metadata hub for your data ecosystem. Missing data? Can you describe what you are building at Voltron Data and the story behind it?
In this episode Raghu Murthy, founder and CEO of Datacoral, does a deep dive on how he and his team manage change data capture pipelines in production. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows.
In this episode CEO and founder Salma Bakouk shares her views on the causes and impacts of "data entropy" and how you can tame it before it leads to failures. Datafold shows how a change in SQL code affects your data, both on a statistical level and down to individual rows and values before it gets merged to production.
His key takeaways from the conversation were that “ data leaders are under tremendous pressure to collaborate within the C-Suite on projects that deliver true business value. Explore the key topics and insights from this event below, and get inspired to apply these takeaways for success in your own data-driven journey.
They also discuss how they have established a guild system for training and supporting data professionals in the organization. Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
He discusses the factors that influenced his decision to start with the datawarehouse, the potential shortcomings of that approach, and where he plans to go from there. This is a great exploration of what it means to treat your data platform as a living system and apply state of the art engineering to it.
In this episode she shares her thoughts and insights on how to be intentional about establishing your own data team. Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content