This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this episode Crux CTO Mark Etherington discusses the different costs involved in managing external data, how to think about the total return on investment for your data, and how the Crux platform is architected to reduce the toil involved in managing third party data.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's data architecture?
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to datamanagement. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
Linked data technologies provide a means of tightly coupling metadata with raw information. In this episode Brian Platz explains how JSON-LD can be used as a shared representation of linked data for building semantic data products. What is the overlap between knowledge graphs and "linked data products"?
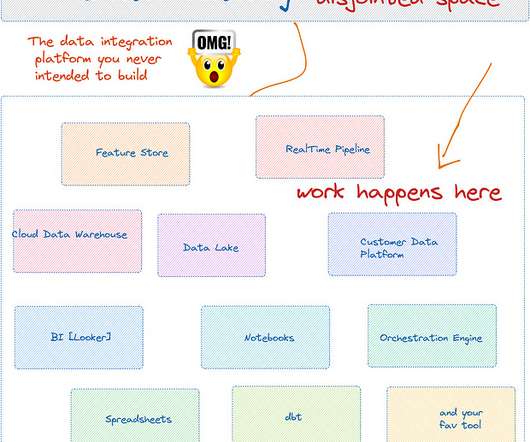
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managingdata without metadata feels like.
Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to datamanagement. It aims to streamline and automate dataworkflows, enhance collaboration and improve the agility of data teams. How effective are your current dataworkflows?
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your dataworkflows. Atlan is the metadata hub for your data ecosystem. Missing data? Stale dashboards?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
In this episode Tobias Macey shares his thoughts on the challenges that he is facing as he prepares to build the next set of architectural layers for his data platform to enable a larger audience to start accessing the data being managed by his team. Data lakes are notoriously complex. Data lakes are notoriously complex.
In this episode Ernie Ostic shares the approach that he and his team at Manta are taking to build a complete view of data lineage across the various data systems in your organization and the useful applications of that information in the work of every data stakeholder. Atlan is the metadata hub for your data ecosystem.
In this episode he discusses the challenge of maintaining shared visibility and understanding of data work across the various stakeholders and his efforts to make it a seamless experience. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Announcements Welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Summary The life sciences as an industry has seen incredible growth in scale and sophistication, along with the advances in data technology that make it possible to analyze massive amounts of genomic information. You can observe your pipelines with built in metadata search and column level lineage.
He recently wrote a book on effective patterns for Pandas code, and in this episode he shares advice on how to write efficient data processing routines that will scale with your data volumes, while being understandable and maintainable. You can observe your pipelines with built in metadata search and column level lineage.
She explains how the design of the platform is informed by the needs of managingdata projects for large and small teams across her previous roles, how it integrates with your existing systems, and how it can work to bring everyone onto the same page. What portions of the dataworkflow is Atlan responsible for?
Summary The Data industry is changing rapidly, and one of the most active areas of growth is automation of dataworkflows. Taking cues from the DevOps movement of the past decade data professionals are orienting around the concept of DataOps. How does this differ from "business as usual" in the data industry?
The January 2019 “Magic Quadrant for DataManagement Solutions for Analytics” provides valuable insights into the status, direction, and players in the DMSA market. All this while the platform serves as the core foundation providing metadata and governance capabilities across these workloads.
Data Catalog as a passive web portal to display metadata requires significant rethinking to adopt modern dataworkflow, not just adding “modern” in its prefix. I know that is an expensive statement to make😊 To be fair, I’m a big fan of data catalogs, or metadatamanagement , to be precise.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Datamanagement and monitoring options. Apache Hadoop ecosystem.
In the realm of big data and AI, managing and securing data assets efficiently is crucial. Databricks addresses this challenge with Unity Catalog, a comprehensive governance solution designed to streamline and secure datamanagement across Databricks workspaces. Advantages of the Unity Catalog 1.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides data pipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. 2023 predictions from the panel are; Unified metadata becomes kingmaker.
At its core, a table format is a sophisticated metadata layer that defines, organizes, and interprets multiple underlying data files. Table formats incorporate aspects like columns, rows, data types, and relationships, but can also include information about the structure of the data itself.
Editor’s Note: The current state of the Data Catalog The results are out for our poll on the current state of the Data Catalogs. The highlights are that 59% of folks think data catalogs are sometimes helpful. We saw in the Data Catalog poll how far it has to go to be helpful and active within a dataworkflow.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of data processes across an organization. These tools help organizations implement DataOps practices by providing a unified platform for data teams to collaborate, share, and manage their data assets.
DataOps is a collaborative approach to datamanagement that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
Data orchestration is the process of efficiently coordinating the movement and processing of data across multiple, disparate systems and services within a company. So, why is data orchestration a big deal? It automates and optimizes data processes, reducing manual effort and the likelihood of errors.
Integrating these principles with data operation-specific requirements creates a more agile atmosphere that supports faster development cycles while maintaining high quality standards. Technical Challenges Choosing appropriate tools and technologies is critical for streamlining dataworkflows across the organization.
This development has paved the way for a suite of cloud-native data tools that are user-friendly, scalable, and affordable. Known as the Modern Data Stack (MDS) , this suite of tools and technologies has transformed how businesses approach datamanagement and analysis.
He believes in making data do the work through proper datamanagement based on strategic rationale and business alignment. On LinkedIn, he posts frequently about big data, master data, data science, datamanagement, and data storytelling.
Why Should You Get an Azure Data Engineer Certification? Becoming an Azure data engineer allows you to seamlessly blend the roles of a data analyst and a data scientist. One of the pivotal responsibilities is managingdataworkflows and pipelines, a core aspect of a data engineer's role.
The Elastic Stacks Elasticsearch is integral within analytics stacks, collaborating seamlessly with other tools developed by Elastic to manage the entire dataworkflow — from ingestion to visualization. Each document has unique metadata fields like index , type , and id that help identify its storage location and nature.
This democratization, facilitated by powerful and intuitive IDEs, will empower "Citizen Data Engineers"—individuals with domain expertise who may not be traditional programmers but can now build and managedataworkflows. In 2025 , Prompt Wrangling will become the most important skill for data engineers.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content