This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What makes the Azure SQL database so popular for OLTP applications? What features of Microsoft Azure SQL database give it an edge over its competitors? To get answers to all these questions, read our ultimate guide on Azure SQL Database! Table of Contents What is Azure SQL Database? How To Connect To Azure SQL Database?
The vast amounts of data generated daily require advanced tools for efficient management and analysis. Enter agentic AI, a type of artificial intelligence set to transform enterprise datamanagement. Many enterprises face overwhelming data sources, from structured databases to unstructured social media feeds.
Summary Databases are the core of most applications, whether transactional or analytical. In recent years the selection of database products has exploded, making the critical decision of which engine(s) to use even more difficult. What are the aspects of the database market that keep you interested as a VP of product?
This week, we delve into the vital world of Databases, SQL, DataManagement, and Statistical Concepts in Data Science. Welcome back to Week 2 of KDnuggets’ "Back to Basics" series.
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Datafold has recently launched data replication testing, providing ongoing validation for source-to-target replication.
Summary A significant portion of data workflows involve storing and processing information in database engines. In this episode Gleb Mezhanskiy, founder and CEO of Datafold, discusses the different error conditions and solutions that you need to know about to ensure the accuracy of your data.
Imagine solving a complex puzzle where each piece represents a unique data point, and their connections form a vast network. Traditional databases often need help to capture these intricate relationships, leaving you with a fragmented view of your data. Table of Contents What is a Graph Database? Why Graph Databases?
Summary Building a database engine requires a substantial amount of engineering effort and time investment. In this episode he explains how he used the combination of Apache Arrow, Flight, Datafusion, and Parquet to lay the foundation of the newest version of his time-series database. Closing Announcements Thank you for listening!
Explore the world of data analytics with the top AWS databases! Check out this blog to discover your ideal database and uncover the power of scalable and efficient solutions for all your data analytical requirements. Let’s understand more about AWS Databases in the following section.
Are you ready to join the database revolution? Data is the new oil" has become the mantra of the digital age, and in this era of rapidly increasing data volumes, the need for robust and scalable databasemanagement solutions has never been more critical. FAQs on Microsoft Azure Cosmos DB What is Azure Cosmos DB?
” This blog will align with that vision by exploring what Pinecone Vector Database is, how to use Pinecone Vector Database, and explore a comprehensive Pinecone Vector Database tutorial with a simple example. Table of Contents What is a Pinecone Vector Database? Pinecone is helpful in this situation.
Summary Data persistence is one of the most challenging aspects of computer systems. In the era of the cloud most developers rely on hosted services to manage their databases, but what if you are a cloud service? It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products.
It's the magic of vector databases! To unlock the power of complex data formats such as audio files, images, etc., researchers have developed vector databases that allow users to utilize similarity search through vectors. Table of Contents Introduction to Vector Databases How Vector Databases Work?
Say goodbye to database downtime, and hello to Amazon Aurora! Explore the advanced features of this powerful cloud-based solution and take your datamanagement to the next level with this comprehensive guide. It offers various cloud database services, with Amazon Aurora being one of the most popular services.
NoSQL databases are the new-age solutions to distributed unstructured data storage and processing. The speed, scalability, and fail-over safety offered by NoSQL databases are needed in the current times in the wake of Big Data Analytics and Data Science technologies.
Ever wished for a database that's as easy to use as your favorite app? Say hello to AWS DocumentDB - your passport to unlocking the simplicity of datamanagement. It's like a magic tool that makes handling data super simple. DocumentDB is everyone's favorite from startups to established enterprises alike.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your datamanagement to the next level. This is particularly useful for companies that need to process data in near-real-time. Q) What ETL does Amazon use?
In recent years, Meta’s datamanagement systems have evolved into a composable architecture that creates interoperability, promotes reusability, and improves engineering efficiency. Data is at the core of every product and service at Meta. Data is at the core of every product and service at Meta.
When most people think of master datamanagement, they first think of customers and products. But master data encompasses so much more than data about customers and products. Challenges of Master DataManagement A decade ago, master datamanagement (MDM) was a much simpler proposition than it is today.
Table of Contents MongoDB NoSQL Database Certification- Hottest IT Certifications of 2025 MongoDB-NoSQL Database of the Developers and for the Developers MongoDB Certification Roles and Levels Why MongoDB Certification? One third of Fortune 100 companies are employing MongoDB NoSQL database for mission critical big data applications.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team.
This will allow companies to speed up AI development and simplify datamanagement with a secure, compliant database solution ready for enterprises across industries, including Fortune 500 financial institutions, high-scale SaaS companies and federal agencies.
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structured datamanagement that really hit its stride in the early 1990s.
In this episode Nick Schrock, creator of Dagster, shares his perspective on the state of data orchestration technology and its application to help inform its implementation in your environment. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles.
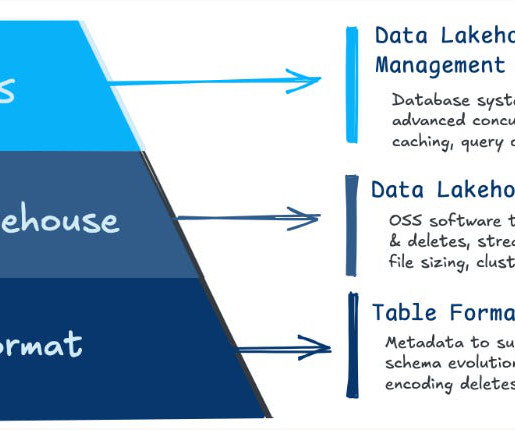
What if your data lake could do more than just store information—what if it could think like a database? As data lakehouses evolve, they transform how enterprises manage, store, and analyze their data. Hudi, with its robust community and technical innovation, is well-positioned to lead this charge.
In this episode Brian Platz explains how JSON-LD can be used as a shared representation of linked data for building semantic data products. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data.
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how datamanagement is done. Pandera, a data validation library for dataframes, now supports Polars. Arroyo, a stream-processing platform, rebuilt their engine using DataFusion.
All this by making it easier for customers to connect their workloads with Snowflake, Cloudera, and unique AWS services such as Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS) , Amazon Relational Database Service (Amazon RDS), Amazon Elastic Compute Cloud (Amazon EC2), Amazon EMR and Amazon Athena.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team.
RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Closing Announcements Thank you for listening!
Unify transactional and analytical workloads in Snowflake for greater simplicity Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads.
This serverless data integration service can automatically and quickly discover structured or unstructured enterprise data when stored in data lakes in Amazon S3, data warehouses in Amazon Redshift, and other databases that are a component of the Amazon Relational Database Service.
Rich set of SQL (query, DDL, DML) commands: Create or manipulate database objects, run queries, load and modify data, perform time travel operations, and convert Hive external tables to Iceberg tables using SQL commands. Create Database and Tables: Open HUE and execute the following to create a database and tables.
In this episode Adrian Brudaru explains how it works, the benefits that it provides over other data integration solutions, and how you can start building pipelines today. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles.
Summary Databases are the core of most applications, but they are often treated as inscrutable black boxes. When an application is slow, there is a good probability that the database needs some attention. It’s the only true SQL streaming database built from the ground up to meet the needs of modern data products.
According to the DataManagement Body of Knowledge, a Data Architect "provides a standard common business vocabulary, expresses strategic requirements, outlines high-level integrated designs to meet those requirements, and aligns with enterprise strategy and related business architecture."
In this episode Ranjith Raghunath shares his thoughts on how to build a strategy for the development, delivery, and evolution of data products. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. With Materialize, you can!
In this episode he shares his journey of data collection and analysis and the challenges of automating an intentionally manual industry. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. With Materialize, you can!
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team.
This article will explore the top seven data warehousing tools that simplify the complexities of data storage, making it more efficient and accessible. So, read on to discover these essential tools for your datamanagement needs. Table of Contents What are Data Warehousing Tools? Why Choose a Data Warehousing Tool?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement This episode is supported by Code Comments, an original podcast from Red Hat. Data observability has been gaining adoption for a number of years now, with a large focus on data warehouses.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many datamanagement and analytic systems. EHR data allows practitioners and researchers to improve patient outcomes and health-related decision-making.
In this episode Tobias Macey shares his thoughts on the challenges that he is facing as he prepares to build the next set of architectural layers for his data platform to enable a larger audience to start accessing the data being managed by his team. With Materialize, you can! Closing Announcements Thank you for listening!
In this episode Louis Brandy discusses the applications for vector search capabilities both in and outside of AI, as well as the challenges of maintaining real-time indexes of vector data. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content