This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Start Your Free Trial | Schedule a Demo
Data input and maintenance : Automation plays a key role here by streamlining how data enters your systems. With automation you become more agile, thanks to the ability to gather high-qualitydata efficiently and maintain it over time – reducing errors and manual processes. Find out more in our eBook.
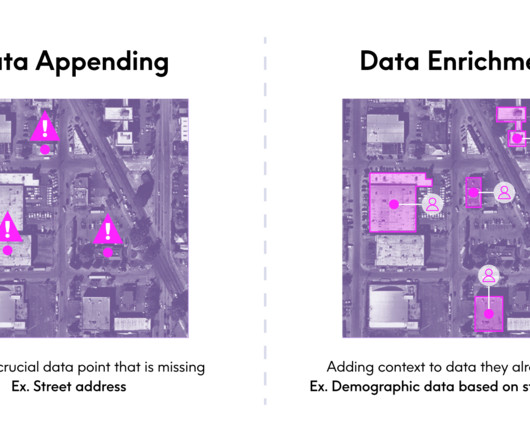
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” We often use different terms when were talking about the same thing in this case, data appending vs. data enrichment.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of dataquality tests. They are all in the realm of software, domain-specific language to help you write dataquality tests.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex. Can you start by sharing some of your experiences with data migration projects? Closing Announcements Thank you for listening! Don't forget to check out our other shows.
Key Differences Between AI Data Engineers and Traditional Data Engineers While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts. Let’s examine a few.
Dataquality refers to the degree of accuracy, consistency, completeness, reliability, and relevance of the data collected, stored, and used within an organization or a specific context. High-qualitydata is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies.
Proactive dataquality measures are critical, especially in AI applications. Using AI systems to analyze and improve dataquality both benefits and contributes to the generation of high-qualitydata. How is the transformation being understood? So how do you avoid these harmful challenges? “To
With AI, those reorders can be automated based on historical patterns and ongoing sales data; the system learns when to restock a product and what quantities to order. . Address datamanagement . No AI-first strategy can truly succeed without a well-defined datamanagement strategy.
How confident are you in the quality of your data? Across industries and business objectives, high-qualitydata is a must for innovation and data-driven decision-making that keeps you ahead of the competition. Can you trust it for fast, confident decision-making when you need it most?
A striking revelation from the 2023 Gartner IT Symposium Research Super Focus Group showed that only 4% of businesses considered their data AI-ready. This big wake-up call emphasizes the urgent need for organizations to enhance their datamanagement practices to pave the way for trusted AI applications.
To maximize your investments in AI, you need to prioritize data governance, quality, and observability. Solving the Challenge of Untrustworthy AI Results AI has the potential to revolutionize industries by analyzing vast datasets and streamlining complex processes – but only when the tools are trained on high-qualitydata.
This includes defining roles and responsibilities related to managingdatasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Additionally, high-qualitydata reduces costly errors stemming from inaccurate information.
Better data-driven decision-making, higher ROI, stronger compliance – what do all these outcomes have in common? They rely on high-qualitydata. But the truth is, it’s harder than ever for organizations to maintain that level of dataquality. With a robust approach to data integrity.
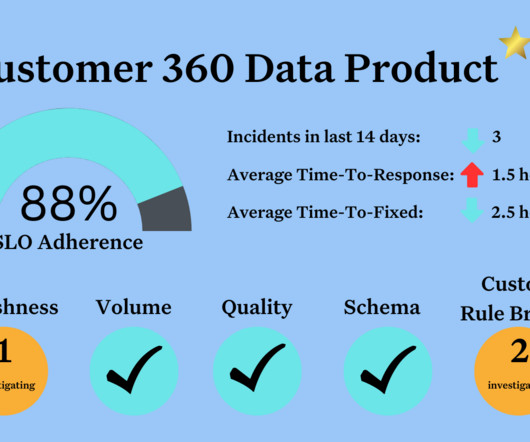
It should address specific data challenges, such as improving operational efficiency, enhancing customer experience, or driving data-driven decision-making. DataQuality and Reliability Ensuring dataquality is crucial for any data product.
As the use of AI becomes more ubiquitous across data organizations and beyond, dataquality rises in importance right alongside it. After all, you can’t have high-quality AI models without high-qualitydata feeding them. Table of Contents What Does an AI DataQuality Analyst Do?
The Five Use Cases in Data Observability: Effective Data Anomaly Monitoring (#2) Introduction Ensuring the accuracy and timeliness of data ingestion is a cornerstone for maintaining the integrity of data systems. This process is critical as it ensures dataquality from the onset.
An increasing number of GenAI tools use large language models that automate key data engineering, governance, and master datamanagement tasks. These tools can generate automated outputs including SQL and Python code, synthetic datasets, data visualizations, and predictions – significantly streamlining your data pipeline.
New technologies are making it easier for customers to process increasingly large datasets more rapidly. But early adopters realized that the expertise and hardware needed to manage these systems properly were complex and expensive. Design in the cloud, deploy anywhere – with an array of deployment options for complex data processes.
On the other hand, “Can the marketing team easily segment the customer data for targeted communications?” usability) would be about extrinsic dataquality. Use of DataQuality Tools Refresh your intrinsic dataquality with data observability 1. This is known as data governance.
The stakes are high and there isn’t a tolerance for error. The Data Integrity Capabilities You Need for ESG Reporting Now that we’ve covered why you need to have clear, accurate, and readily accessible data to show the progress of your ESG efforts, let’s walk through a snapshot of what that means for your datamanagement capabilities.
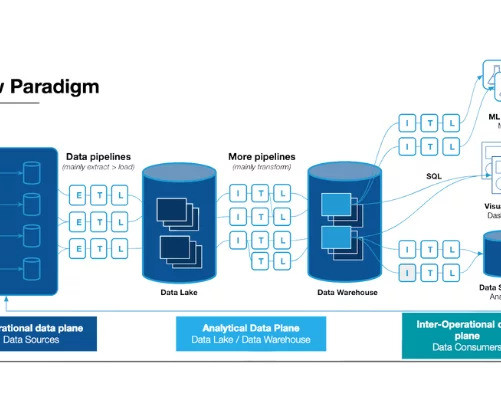
A visualization of the flow of data in data lakehouse architecture vs. data warehouse and data lake. Innovations in data lakehouse architecture have been an important step toward more flexible and powerful datamanagement systems. Image courtesy of Databricks.
A visualization of the flow of data in data lakehouse architecture vs. data warehouse and data lake. Innovations in data lakehouse architecture have been an important step toward more flexible and powerful datamanagement systems. Image courtesy of Databricks.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. link] Nvidia: What Is Sovereign AI?
DataOps , short for Data Operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of datamanagement processes. It aims to streamline the entire data lifecycle—from ingestion and preparation to analytics and reporting.
Ensure dataquality Even if there are no errors during the ETL process, you still have to make sure the data meets quality standards. High-qualitydata is crucial for accurate analysis and informed decision-making. Ready to leap to the next level of datamanagement prowess?
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
We’ll then discuss how they can be avoided with an organizational commitment to high-qualitydata. Imagine this You’re a data scientist with a swagger working on a predictive model to optimize a fast-growing company’s digital marketing spend. Model design You see the LinkedIn ad click data has.1%
It should address specific data challenges, such as improving operational efficiency, enhancing customer experience, or driving data-driven decision-making. DataQuality and Reliability Ensuring dataquality is crucial for any data product.
It should address specific data challenges, such as improving operational efficiency, enhancing customer experience, or driving data-driven decision-making. DataQuality and Reliability Ensuring dataquality is crucial for any data product.
This step is pivotal in ensuring data consistency and relevance, essential for the accuracy of subsequent predictive models. The heart of the process lies in training advanced machine learning models on this refined dataset. Take UPS, for instance.
In this article, we’ll recap the key takeaways from the summit and the groundbreaking advancements in data pipeline automation that we’re working on at Ascend. Link data products within and across data clouds , allowing users to access and analyze data in a unified, consistent manner.
The key differences are that data integrity refers to having complete and consistent data, while data validity refers to correctness and real-world meaning – validity requires integrity but integrity alone does not guarantee validity. What is Data Integrity? How Do You Maintain Data Validity?
This blog offers an exclusive glimpse into the daily rituals, challenges, and moments of triumph that punctuate the professional journey of a data scientist. The primary objective of a data scientist is to analyze complex datasets to uncover patterns, trends, and valuable information that can aid in informed decision-making.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-qualitydata. Here lies the critical role of data engineering: preparing and managingdata to feed AI models.
A passing test means you’ve improved the trustworthiness of your data. Schedule and automate You’ll need to run schema tests continuously to keep up with your ever-changing data. If your datasets are updated or refreshed daily, you’ll want to run your schema tests on a similar schedule.
Improved Collaboration Among Teams Data engineering teams frequently collaborate with other departments, such as analysts or scientists, who depend on accurate datasets for their tasks. Boosting Operational Efficiency A well-monitored data pipeline can significantly increase an organization’s operational efficiency.
DataOps is an automated, process-oriented methodology used by analytics and data teams to improve quality and reduce the cycle times of data and analytics. The goal of DataOps is to deliver value faster by creating predictable delivery and change management of data, data models, and related artifacts.”
So, just to be safe you take the extra time to recreate the dataset. Data products and trustworthiness According to Zhamak Dehgahi, data products should be discoverable, addressable, trustworthy, self-describing, interoperable and secure. In our experience, most data products only support one or two use cases.
Gartner While Gartner hasn’t produced a data observability magic quadrant or report ranking data observability vendors, they have named it one of the hottest emerging technologies and placed it on the 2023 DataManagement Hype Cycle. That means data engineers and highqualitydata are integral to the solution.
Data Teams and Their Types of Data Journeys In the rapidly evolving landscape of datamanagement and analytics, data teams face various challenges ranging from data ingestion to end-to-end observability. The Hub Data Journey provides the raw data and adds value through a ‘contract.
A data product, coined by DJ Patil, Former Chief Data Scientist of the United States, has several components, including a product management process, the domain wrapper comprising a semantic layer, business logic and metrics, and access. Simply put, a data product is much more than a dataset alone.
Technologies like data observability can bring data monitoring to scale so there doesn’t need to be a trade off between quantity and big dataquality, but the point remains data volume alone is insufficient to make a fraction of the impact of a well-maintained, highqualitydata product.
Due to the enormous amount of data being generated and used in recent years, there is a high demand for data professionals, such as data engineers, who can perform tasks such as datamanagement, data analysis, data preparation, etc. big data and ETL tools, etc.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content