This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The same study also stated that having stronger online data security, being able to conduct more banking transactions online and having more real-time problem resolution were the top priorities of consumers. . Financial institutions need a datamanagement platform that can keep pace with their digital transformation efforts.
Proactive dataquality measures are critical, especially in AI applications. Using AI systems to analyze and improve dataquality both benefits and contributes to the generation of high-qualitydata. Bias is a very critical topic in AI,” notes Bapat.
It enhances dataquality, governance, and automation, transforming rawdata into valuable insights. This is what managingdata without metadata feels like. This helps in identifying and rectifying errors, leading to high-qualitydata. Chaos, right?
L1 is usually the raw, unprocessed data ingested directly from various sources; L2 is an intermediate layer featuring data that has undergone some form of transformation or cleaning; and L3 contains highly processed, optimized, and typically ready for analytics and decision-making processes. What is Data in Use?
Visual representation of Conway’s Law ( source ) Read More: The Chief AI Officer: Avoid The Trap of Conway’s Law Process: Ensuring Data Readiness The backbone of successful AI implementation is robust datamanagement processes. AI models are only as good as the data they consume, making continuous data readiness crucial.
Azure Databricks Delta Live Table s: These provide a more straightforward way to build and manageData Pipelines for the latest, high-qualitydata in Delta Lake. It provides data prep, management, and enterprise data warehousing tools. It does the job.
They employ a wide array of tools and techniques, including statistical methods and machine learning, coupled with their unique human understanding, to navigate the complex world of data. A significant part of their role revolves around collecting, cleaning, and manipulating data, as rawdata is seldom pristine.
The specific methods and steps for data cleaning may vary depending on the dataset, but its importance remains constant in the data science workflow. Why Is Data Cleaning So Important? These issues can stem from various sources such as human error, data scraping, or the integration of data from multiple sources.
Observability platforms not only supply rawdata but also offer actionable insights through visualizations, dashboards, and alerts. Databand allows data engineering and data science teams to define dataquality rules, monitor data consistency, and identify data drift or anomalies.
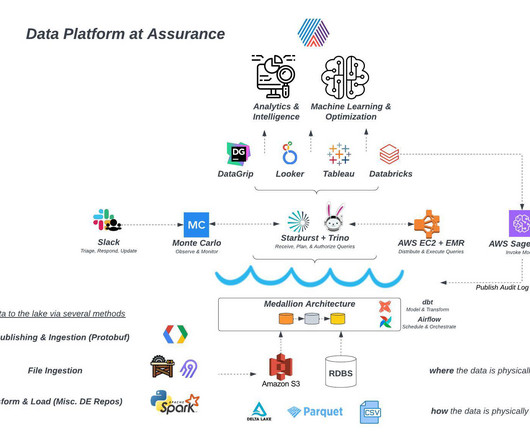
As the company scales, various teams within Assurance—including data engineering, machine learning engineering, data science, business intelligence, and analytics engineering—leverage the platform to create new data assets. Requirements for such a tool included: 1.
Whether the end result is a weekly report, dashboard, or embedded in a customer facing application, data products require a level of polish and data curation that is antithetical to unorganized sprawl. Your ability to pipe data is virtually limitless, but you are constrained by the capacity of humans to make it sustainably meaningful.
Not long after data warehouses moved to the cloud, so too did data lakes (a place to transform and store unstructured data), giving data teams even greater flexibility when it comes to managing their data assets. That is the question – at least if you ask a data engineer.
The `dbt run` command will compile and execute your models, thus transforming your rawdata into analysis-ready tables. Once the models are created and data transformed, `dbt test` should be executed. This command runs all tests defined in your dbt project against the transformed data.
Data Teams and Their Types of Data Journeys In the rapidly evolving landscape of datamanagement and analytics, data teams face various challenges ranging from data ingestion to end-to-end observability. The Hub Data Journey provides the rawdata and adds value through a ‘contract.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content