This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
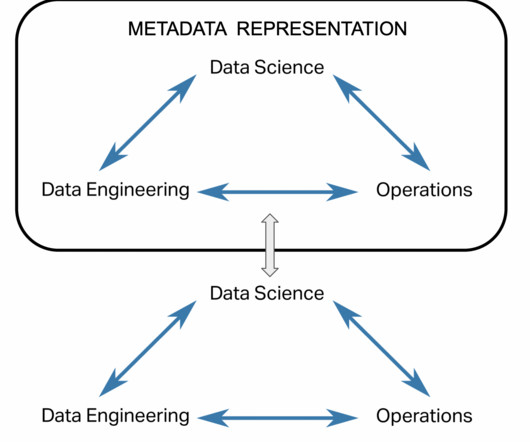
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Upgraded Data Governance service Artificial intelligence (AI) advancements Expanded data integration capabilities Enhanced Data Catalog functionality Together, these advancements enable your organization to better integrate, govern, and improve the readiness of your data for trusted analytics, reliable AI insights , and faster time to value.
Summary The information about how data is acquired and processed is often as important as the data itself. For this reason metadatamanagement systems are built to track the journey of your business data to aid in analysis, presentation, and compliance. What is involved in deploying your metadata collection agents?
Key Takeaways: Data mesh is a decentralized approach to datamanagement, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to datamanagement, creating a consistent way to manage, access, and share data across distributed environments.
Summary In order to scale the use of data across an organization there are a number of challenges related to discovery, governance, and integration that need to be solved. The key to those solutions is a robust and flexible metadatamanagement system. If you hand a book to a new data engineer, what wisdom would you add to it?
Data powers Uber’s global marketplace, enabling more reliable and seamless user experiences across our products for riders, … The post Databook: Turning Big Data into Knowledge with Metadata at Uber appeared first on Uber Engineering Blog.
Summary A significant source of friction and wasted effort in building and integrating datamanagement systems is the fragmentation of metadata across various tools. What are the common challenges faced by engineers and data practitioners in organizing the metadata for their systems?
In this episode Crux CTO Mark Etherington discusses the different costs involved in managing external data, how to think about the total return on investment for your data, and how the Crux platform is architected to reduce the toil involved in managing third party data.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadatamanagement to attribute better Snowflake cost. Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how datamanagement is done.
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. In a good data governance strategy, it is important to define roles that allow the business to limit the level of access that users can have to their strategic data assets.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
However, they require a strong data foundation to be effective. With the rise of cloud-based datamanagement, many organizations face the challenge of accessing both on-premises and cloud-based data. Without a unified, clean data structure, leveraging these diverse data sources is often problematic.
In this episode Shinji Kim discusses the challenges of data discovery and how to collect and preserve additional context about each piece of information so that you can find what you need when you don’t even know what you’re looking for yet. What do you have planned for the future of SelectStar?
This new convergence helps Meta and the larger community build datamanagement systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how datamanagement systems are designed.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's data architecture?
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managingdata without metadata feels like.
Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today? Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today? What do you have planned for the future of the podcast?
This ecosystem includes: Catalogs: Services that managemetadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managingmetadata.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
Monitor and Adapt: Continuously assess the impact of GenAI on data governance practices and be prepared to adapt policies as technologies evolve. Data governance is the only way to ensure those requirements are met. Chief Technology Officer, Finance Industry For all the quotes, download the Trendbook today!
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Hey there podcast listener, are you tired of dealing with the headache that is the 'Modern Data Stack'? It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table.
Further Exloration: What is data automation? Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to datamanagement. It aims to streamline and automate data workflows, enhance collaboration and improve the agility of data teams.
In this episode Isaac Brodsky explains how the Unfolded platform is architected, their experience joining the team at Foursquare, and how you can start using it for analyzing your spatial data today. Atlan is the metadata hub for your data ecosystem. What are some of the core challenges of working with spatial data?
In this episode Amir Orad discusses the Sisense platform and how it facilitates the embedding of analytics and data insights in every aspect of organizational and end-user experiences. Atlan is the metadata hub for your data ecosystem. What is your view on the role of business intelligence in a data driven organization?
He also describes the considerations involved in bringing behavioral data into your systems, and the ways that he and the rest of the Snowplow team are working to make that an easy addition to your platforms. Atlan is the metadata hub for your data ecosystem. What are some of the unique characteristics of that information?
In this episode Abe Gong brings his experiences with the Great Expectations project and community to discuss the technical and organizational considerations involved in implementing these constraints to your data workflows. Atlan is the metadata hub for your data ecosystem. Missing data? Struggling with broken pipelines?
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. In a good data governance strategy, it is important to define roles that allow the business to limit the level of access that users can have to their strategic data assets.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless data access, sharing, and management across an organization. Datamanagement recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
He explains the constraints that he and his team are faced with and the various challenges that they have overcome to build useful data products on top of a legacy platform where they don’t control the end-to-end systems. Atlan is the metadata hub for your data ecosystem. Closing Announcements Thank you for listening!
In this episode Shane Gibson shares practical advice and insights from his years of experience as a consultant and engineer working in data about how to adopt agile principles in your data work so that you can move faster and provide more value to the business, while building systems that are maintainable and adaptable.
In this episode she shares the strategic and tactical elements of how to make more effective use of the technical and organizational resources that are available to you for getting work done with data. Atlan is the metadata hub for your data ecosystem. Missing data? Struggling with broken pipelines? Stale dashboards?
First of all, in data science, data discovery means finding patterns in data using database query languages to test hypotheses. This kind of data discovery can be subdivided into several steps, as e.g. suggested by Piethein Strengholt in DataManagement at Scale.
Linked data technologies provide a means of tightly coupling metadata with raw information. In this episode Brian Platz explains how JSON-LD can be used as a shared representation of linked data for building semantic data products. What is the overlap between knowledge graphs and "linked data products"?
However, they require a strong data foundation to be effective. With the rise of cloud-based datamanagement, many organizations face the challenge of accessing both on-premises and cloud-based data. Without a unified, clean data structure, leveraging these diverse data sources is often problematic.
Summary Data governance is a practice that requires a high degree of flexibility and collaboration at the organizational and technical levels. The growing prominence of cloud and hybrid environments in datamanagement adds additional stress to an already complex endeavor. What do you have planned for the future of Privacera?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Are you tired of dealing with the headache that is the 'Modern Data Stack'? It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. We feel your pain.
Catalog/MetadataManagement , which is responsible for storing and serving table metadata, including ownership, schemas, SLAs, etc., and also providing runtime metadata about the platform Security and Auditability , which ensures GDPR compliance, advanced levels of auditability, security, AAA, etc.
Further Exloration: What is data automation? Deploy DataOps DataOps , or Data Operations, is an approach that applies the principles of DevOps to datamanagement. It aims to streamline and automate data workflows, enhance collaboration and improve the agility of data teams.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content