This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Working with unstructureddata has typically been a motivation for a data lake. Kirk Marple has spent years working with data systems and the media industry, which inspired him to build a platform for automatically organizing your unstructured assets to make them more valuable.
In this episode Isaac Brodsky explains how the Unfolded platform is architected, their experience joining the team at Foursquare, and how you can start using it for analyzing your spatial data today. Atlan is the metadata hub for your data ecosystem. Unstruk is the DataOps platform for your unstructureddata.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode.
In this episode she explains the difficulties that everyone faces as they scale beyond a single operating environment, and how the Komprise platform reduces the burden of managing large and heterogeneous collections of unstructured files. You can observe your pipelines with built in metadata search and column level lineage.
This ecosystem includes: Catalogs: Services that managemetadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managingmetadata.
Track data files within the table along with their column statistics. Open table formats enable efficient datamanagement and retrieval by storing these files chronologically, with a history of DDL and DML actions and an index of data file locations. It can also be integrated into major data platforms like Snowflake.
Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems. Data governance is the only way to ensure those requirements are met.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
In this episode she shares her thoughts and insights on how to be intentional about establishing your own data team. Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities.
Over the years, the technology landscape for datamanagement has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. In keeping up with ever-evolving datamanagement needs, we’re announcing new capabilities that support customers across all of these patterns.
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Ingest data more efficiently and manage costs For datamanaged by Snowflake, we are introducing features that help you access data easily and cost-effectively.
In this episode Ernie Ostic shares the approach that he and his team at Manta are taking to build a complete view of data lineage across the various data systems in your organization and the useful applications of that information in the work of every data stakeholder. Atlan is the metadata hub for your data ecosystem.
Also, the associated business metadata for omics, which make it findable for later use, are dynamic and complex and need to be captured separately. Additionally, the fact that they need to be standardized makes the data discovery effort challenging for downstream analysis. The principles emphasize machine-actionability (i.e.,
The Modern Story: Navigating Complexity and Rethinking Data in The Business Landscape Enterprises face a data landscape marked by the proliferation of IoT-generated data, an influx of unstructureddata, and a pervasive need for comprehensive data analytics.
In the past decade, the amount of structured data created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructureddata, cloud data, and machine data – another 50 ZB.
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e., need to integrate multiple “point solutions” used in a data ecosystem) and organization reasons (e.g., difficulty to achieve cross-organizational governance model).
This recognition underscores Cloudera’s commitment to continuous customer innovation and validates our ability to foresee future data and AI trends, and our strategy in shaping the future of datamanagement. Cloudera, a leader in big data analytics, provides a unified Data Platform for datamanagement, AI, and analytics.
The Modern Story: Navigating Complexity and Rethinking Data in The Business Landscape Enterprises face a data landscape marked by the proliferation of IoT-generated data, an influx of unstructureddata, and a pervasive need for comprehensive data analytics.
In this episode Wes McKinney shares the ways that Arrow and its related projects are improving the efficiency of data systems and driving their next stage of evolution. Atlan is the metadata hub for your data ecosystem. Missing data? Can you describe what you are building at Voltron Data and the story behind it?
In this episode Dale Kim shares how Hazelcast is implemented, the use cases that it enables, and how it complements on-disk datamanagement systems. If you hand a book to a new data engineer, what wisdom would you add to it? Tree Schema is a data catalog that is making metadatamanagement accessible to everyone.
Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested. Imagine independently discovering rich new business insights from both structured and unstructureddata working together, without having to beg for data sets to be made available.
Maintaining communication with your staff, which necessitates correct employee data , is one approach to improve it. . What Is Employee DataManagement? . Employee database management is a self-service system that allows employees to enter, update and assess their data. Improved Data Security and Sharing.
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. Then, Glue writes the job's metadata into the embedded AWS Glue Data Catalog. being data exactly matches the classifier, and 0.0 Why Use AWS Glue?
While Cloudera CDH was already a success story at HBL, in 2022, HBL identified the need to move its customer data centre environment from Cloudera’s CDH to Cloudera Data Platform (CDP) Private Cloud to accommodate growing volumes of data. Smooth, hassle-free deployment in just six weeks.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. Bad datamanagement be like, Source: Makeameme Data architects are sometimes confused with other roles inside the data science team.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1. Metadata layer 4. Ingestion layer 2. API layer 5.
This architecture format consists of several key layers that are essential to helping an organization run fast analytics on structured and unstructureddata. Table of Contents What is data lakehouse architecture? The 5 key layers of data lakehouse architecture 1. Metadata layer 4. Ingestion layer 2. API layer 5.
A HDFS Master Node, called a NameNode , keeps metadata with critical information about system files (like their names, locations, number of data blocks in the file, etc.) and keeps track of storage capacity, a volume of data being transferred, etc. Datamanagement and monitoring options. Issues with small files.
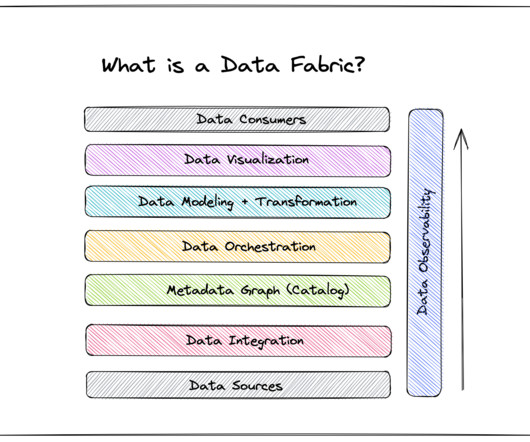
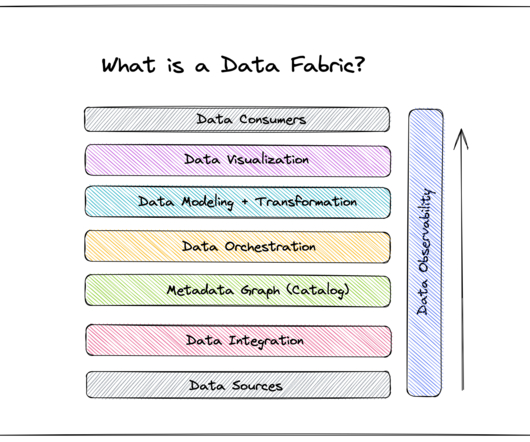
Enter data fabric: a datamanagement architecture designed to serve the needs of the business, not just those of data engineers. A data fabric is an architecture and associated data products that provide consistent capabilities across a variety of endpoints spanning multiple cloud environments.
Enter data fabric: a datamanagement architecture designed to serve the needs of the business, not just those of data engineers. A data fabric is an architecture and associated data products that provide consistent capabilities across a variety of endpoints spanning multiple cloud environments.
In the realm of big data and AI, managing and securing data assets efficiently is crucial. Databricks addresses this challenge with Unity Catalog, a comprehensive governance solution designed to streamline and secure datamanagement across Databricks workspaces. Advantages of the Unity Catalog 1.
Integrated data catalog for metadata support As you build out your IT ecosystem, it’s important to leverage tools that have the capabilities to support forward-looking use cases. A notable capability that achieves this is the data catalog. If so, how do you combine that metadata with other data across the enterprise? #4.
One advantage of data warehouses is their integrated nature. As fully managed solutions, data warehouses are designed to offer ease of construction and operation. A warehouse can be a one-stop solution, where metadata, storage, and compute components come from the same place and are under the orchestration of a single vendor.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structured data.
Depending on the quantity of data flowing through an organization’s pipeline — or the format the data typically takes — the right modern table format can help to make workflows more efficient, increase access, extend functionality, and even offer new opportunities to activate your unstructureddata.
As a result, data virtualization enabled the company to conduct advanced analytics and data science, contributing to the growth of the business. Global investment bank: Cost reduction with more scalable and effective datamanagement. Data virtualization architecture example. Connection layer.
Some would say that it’s not a big deal, however, these mixed environments have resulted in the complexities of managing disjointed data and business processes. With these challenges in enterprise datamanagement, there has to be an approach to overcoming them, right? The solution is called a data fabric.
This feature is critical in today’s data-driven business environment, where data may originate from a variety of sources and undergo numerous transformations before reaching its final destination. MetadataManagementMetadata, or ‘data about data’, is a crucial component of datamanagement.
A data hub, in turn, is rather a terminal or distribution station: It collects information only to harmonize it, and sends it to the required end-point systems. Data lake vs data hub. A data lake is quite opposite of a DW, as it stores large amounts of both structured and unstructureddata.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. AWS is one of the most popular data lake vendors.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the datamanagement phase begins with: Data ingestion: Data is acquired, cleansed, and curated before it is transformed. Data governance As a datamanagement framework, feature stores must consider data privacy and data governance.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Well, there’s a new phenomenon in datamanagement that received the name of a data lakehouse. The pun being obvious, there’s more to that than just a new term: Data lakehouses combine the best features of both data lakes and data warehouses and this post will explain this all. Data warehouse.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructureddata. What is a Data Lake? Want to learn more about data governance?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content