This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. In the beginning, there was a data warehouse The data warehouse (DW) was an approach to data architecture and structureddatamanagement that really hit its stride in the early 1990s.
Summary The process of exposing your data through a SQL interface has many possible pathways, each with their own complications and tradeoffs. One of the recent options is Rockset, a serverless platform for fast SQL analytics on semi-structured and structureddata. Closing Announcements Thank you for listening!
In our previous post, The Pros and Cons of Leading DataManagement and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a datamanagement ecosystem?
In our previous post, The Pros and Cons of Leading DataManagement and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a datamanagement ecosystem?
In our previous post, The Pros and Cons of Leading DataManagement and Storage Solutions , we untangled the differences among data lakes, data warehouses, data lakehouses, data hubs, and data operating systems. What factors are most important when building a datamanagement ecosystem?
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). While functional, our current setup for managing tables is fragmented.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing. However, data warehouses can experience limitations and scalability challenges.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing. However, data warehouses can experience limitations and scalability challenges.
Data lakes, data warehouses, data hubs, data lakehouses, and data operating systems are datamanagement and storage solutions designed to meet different needs in data analytics, integration, and processing. However, data warehouses can experience limitations and scalability challenges.
Over the years, the technology landscape for datamanagement has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. In keeping up with ever-evolving datamanagement needs, we’re announcing new capabilities that support customers across all of these patterns.
While the Iceberg itself simplifies some aspects of datamanagement, the surrounding ecosystem introduces new challenges: Small File Problem (Revisited): Like Hadoop, Iceberg can suffer from small file problems. Data ingestion tools often create numerous small files, which can degrade performance during query execution.
With so much riding on the efficiency of ETL processes for data engineering teams, it is essential to take a deep dive into the complex world of ETL on AWS to take your datamanagement to the next level. Data integration with ETL has changed in the last three decades.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement What are the pieces of advice that you wish you had received early in your career of data engineering? If you hand a book to a new data engineer, what wisdom would you add to it?
To attain that level of data quality, a majority of business and IT leaders have opted to take a hybrid approach to datamanagement, moving data between cloud, on-premises -or a combination of the two – to where they can best use it for analytics or feeding AI models. What do we mean by ‘true’ hybrid?
Cheryl Martin, Chief Data Scientist for Alegion, discusses the importance of properly labeled information for machine learning and artificial intelligence projects, the systems that they have built to scale the process of incorporating human intelligence in the data preparation process, and the challenges inherent to such an endeavor.
If you are evaluating your options for building or migrating a data platform, then this is definitely worth a listen. You listen to this show to learn and stay up to date with what’s happening in databases, streaming platforms, big data, and everything else you need to know about modern datamanagement.
3EJHjvm Once a business need is defined and a minimal viable product ( MVP ) is scoped, the datamanagement phase begins with: Data ingestion: Data is acquired, cleansed, and curated before it is transformed. Feature engineering: Data is transformed to support ML model training. ML workflow, ubr.to/3EJHjvm
Proficiency in Programming Languages Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike. In addition, AI data engineers should be familiar with programming languages such as Python , Java, Scala, and more for data pipeline, data lineage, and AI model development.
If you are wondering how to deal with all of the information that doesn’t fit in your databases or data warehouses, then this episode is for you. Can you describe what Unstruk Data is and the story behind it? What would you classify as "unstructured data"? What would you classify as "unstructured data"?
In this episode Eric Kansa describes how they process, clean, and normalize the data that they host, the challenges that they face with scaling ETL processes which require domain specific knowledge, and how the information contained in connections that they expose is being used for interesting projects.
If you’re struggling with unwieldy dimensional models, slow moving projects, or challenges integrating new data sources then listen in on this conversation and then give data vault a try for yourself. We have partnered with organizations such as O’Reilly Media, Corinium Global Intelligence, ODSC, and Data Council.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
While AI-powered, self-service BI platforms like ThoughtSpot can fully operationalize insights at scale by delivering visual data exploration and discovery, it still requires robust underlying datamanagement. Snowflake's new dynamic tables feature redefines how BI and analytics teams approach data transformation pipelines.
Summary Data is one of the core ingredients for machine learning, but the format in which it is understandable to humans is not a useful representation for models. Embedding vectors are a way to structuredata in a way that is native to how models interpret and manipulate information. images, audio, video, etc.)
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e., need to integrate multiple “point solutions” used in a data ecosystem) and organization reasons (e.g., difficulty to achieve cross-organizational governance model).
Unlike previous solutions, it forms the core of Microsoft’s modern data strategy—more than just a standalone tool. Meanwhile, the visualization tool offers wide-ranging data connectors—from Azure SQL and SharePoint to Salesforce and Google Analytics—enabling quick access to structured and semi-structureddata.
Powered and supported by Cloudera, this framework brings together disparate data sources, combining internal data with public data, and structureddata with unstructured data. It can also prevent unauthorized data access, decrease operational costs, and greatly increase business agility for multiple users.
link] LinkedIn: LakeChime - A Data Trigger Service for Modern Data Lakes LinkedIn points out two critical flaws in a partitioned approach to datamanagement. The granularity of partition creation constrained data consumption. However, the Map and Array comes with its cost.
“Enterprises are more mature in managing the quality of structureddata than newer data types.” Organizations are adept at managing the quality of structureddata, but management of unstructured and semi-structureddata is less mature. • Adopt process automation platforms.
In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses. This method is advantageous when dealing with structureddata that requires pre-processing before storage.
This recognition underscores Cloudera’s commitment to continuous customer innovation and validates our ability to foresee future data and AI trends, and our strategy in shaping the future of datamanagement. Cloudera, a leader in big data analytics, provides a unified Data Platform for datamanagement, AI, and analytics.
Despite these limitations, data warehouses, introduced in the late 1980s based on ideas developed even earlier, remain in widespread use today for certain business intelligence and data analysis applications. While data warehouses are still in use, they are limited in use-cases as they only support structureddata.
MongoDB Atlas excels at storing and processing unstructured and semi-structureddata, while PostgreSQL offers scalability and advanced analytics. MongoDB Atlas to PostgreSQL integration forms a robust ecosystem that addresses the technical challenges associated with datamanagement and analysis.
Main users of Hive are data analysts who work with structureddata stored in the HDFS or HBase. Datamanagement and monitoring options. Among solutions facilitation datamanagement are. It allows data scientists to conveniently query structureddata in Spark programs.
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. On the other hand, a data warehouse contains historical data that has been cleaned and arranged. . What is Data Warehouse? . Data Warehouse in DBMS: .
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
First, organizations have a tough time getting their arms around their data. More data is generated in ever wider varieties and in ever more locations. Organizations don’t know what they have anymore and so can’t fully capitalize on it — the majority of data generated goes unused in decision making. Better together.
Disruptive Database Technologies All existing and upcoming businesses are adopting innovative ways of handling data. With these technologies, businesses and organizations enhance their datamanagement procedures, upgrade their knowledge, and make better decisions using data. Disruptive database technologies are on them.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many datamanagement and analytic systems. However, the vast volume of data will overwhelm you if you start looking at historical trends.
You can use data warehouses or data lakes as a repository for datamanagement and analytics tasks. A data warehouse is the best if your organization works only with structureddata. Data lake is a suitable choice if your work is based entirely on raw or […]
You can use data warehouses or data lakes as a repository for datamanagement and analytics tasks. A data warehouse is the best if your organization works only with structureddata. Data lake is a suitable choice if your work is based entirely on raw or […]
Goal To extract and transform data from its raw form into a structured format for analysis. To uncover hidden knowledge and meaningful patterns in data for decision-making. Data Source Typically starts with unprocessed or poorly structureddata sources. Analyzing and deriving valuable insights from data.
Big Data vs Small Data: Function Variety Big Data encompasses diverse data types, including structured, unstructured, and semi-structureddata. It involves handling data from various sources such as text documents, images, videos, social media posts, and more.
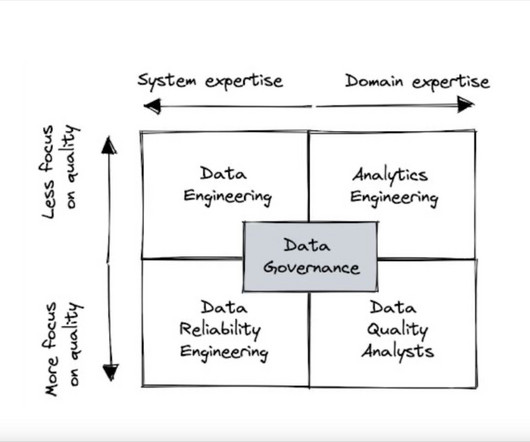
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Having the data engineering team lead the response to data quality is by far the most common pattern. It is deployed by about half of all organizations that use a modern data stack.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content