This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Managing and utilizing data effectively is crucial for organizational success in today's fast-paced technological landscape. The vast amounts of data generated daily require advanced tools for efficient management and analysis. A path forward Agentic AI represents a change in thinking in enterprise datamanagement.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Dagster offers a new approach to building and running data platforms and data pipelines. Can you describe the operational/architectural aspects of building a full data engine on top of the FDAP stack?
Data teams are expected to juggle a combination of ad-hoc requests, big bet projects, migrations, etc. All while keeping up with the latest changes in technology.
This blog explores how new technologies such as Databricks Data Intelligence Platform can pave the way for more effective and efficient multi-omics datamanagement.
In this engaging and witty talk, industry expert Conrado Morlan will explore how artificial intelligence can transform the daily tasks of product managers into streamlined, efficient processes. The Future of Product Management 🔮 How to continuously integrate AI into your work to stay ahead of emerging trends and technologies.
Disclaimer: Throughout this post, I discuss a variety of complex technologies but avoid trying to explain how these technologies work. The goal of this post is to understand how data integrity best practices have been embraced time and time again, no matter the technology underpinning. Then came Big Data and Hadoop!
When most people think of master datamanagement, they first think of customers and products. But master data encompasses so much more than data about customers and products. Challenges of Master DataManagement A decade ago, master datamanagement (MDM) was a much simpler proposition than it is today.
The best part to jump on the bandwagon of information technology or IT is, there is an enormous possibility for an individual if he or she starts studying for a diploma or a degree, does either a master's degree or a research course. He or she can get a full-fledged engineering degree. You can learn CCNA, CCNP and more from CISCO academy.
In this episode Crux CTO Mark Etherington discusses the different costs involved in managing external data, how to think about the total return on investment for your data, and how the Crux platform is architected to reduce the toil involved in managing third party data. When is Crux the wrong choice?
Big data in information technology is used to improve operations, provide better customer service, develop customized marketing campaigns, and take other actions to increase revenue and profits. In the world of technology, things are always changing. It is especially true in the world of big data.
In this episode DeVaris Brown discusses the types of applications that are possible when teams don't have to manage the complex infrastructure necessary to support continuous data flows. Can you describe what Meroxa is and the story behind it? How have the focus and goals of the platform and company evolved over the past 2 years?
IBM and Cloudera’s common goal is to accelerate data-driven decision making for enterprise customers, working on defining and executing the best solution for each customer. You can now elevate your data potential and activate AI’s capabilities through the synergic integration between IBM watsonx and Cloudera.
Integrate data governance and data quality practices to create a seamless user experience and build trust in your data. When planning your data governance approach, start small, iterate purposefully, and foster data literacy to drive meaningful business outcomes.
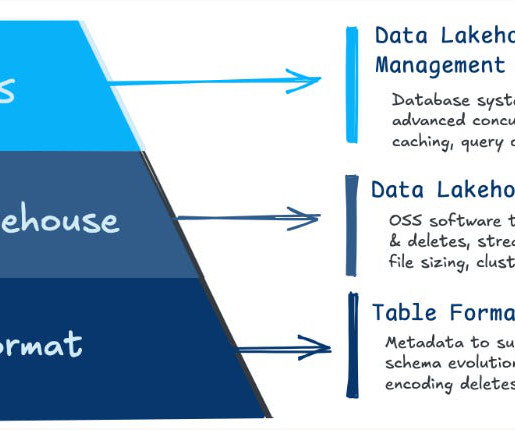
In this episode Dain Sundstrom, CTO of Starburst, explains how the combination of the Trino query engine and the Iceberg table format offer the ease of use and execution speed of data warehouses with the infinite storage and scalability of data lakes. What do you have planned for the future of Trino/Starburst?
Data quality and data governance are the top data integrity challenges, and priorities. A long-term approach to your data strategy is key to success as business environments and technologies continue to evolve. However, they require a strong data foundation to be effective. Take a proactive approach.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. Can you describe your experiences with Kafka?
Key Takeaways: Data mesh is a decentralized approach to datamanagement, designed to shift creation and ownership of data products to domain-specific teams. Data fabric is a unified approach to datamanagement, creating a consistent way to manage, access, and share data across distributed environments.
Summary Data systems are inherently complex and often require integration of multiple technologies. This offers a single location for managing visibility and error handling so that data platform engineers can manage complexity. container orchestration, generalized workflow orchestration, etc.)
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement RudderStack helps you build a customer data platform on your warehouse or data lake. Can you describe what SQLMesh is and the story behind it? DataOps is a term that has been co-opted and overloaded.
With its rise in popularity generative AI has emerged as a top CEO priority, and the importance of performant, seamless, and secure datamanagement and analytics solutions to power those AI applications is essential. This means you can expect simpler datamanagement and drastically improved productivity for your business users.
Nicola Askham found her way into data governance by accident, and stayed because of the benefit that she was able to provide by serving as a bridge between the technology and business. In this episode she shares the practical steps to implementing a data governance practice in your organization, and the pitfalls to avoid.
Together, we discussed how Hudi drives innovation, the state of open standards, and what lies ahead for data lakehouses in 2025 and beyond. This foundational concept addresses a key challenge for enterprises: building scalable, high-performing data platforms that can support the complexity of modern data ecosystems.
AI News 🤖 Mira Murati answers the Wall Street Journal about OpenAI Sora — OpenAI CTO has been asked a few questions about the underlying technology in Sora. The technology under this, is, Cityvision. Pandera, a data validation library for dataframes, now supports Polars. She revealed a few insights.
This blog will explore the significant advancements, challenges, and opportunities impacting data engineering in 2025, highlighting the increasing importance for companies to stay updated. Key Trends in Data Engineering for 2025 In the fast-paced world of technology, data engineering services keep companies that focus on data running.
Summary Generative AI has rapidly transformed everything in the technology sector. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Dagster offers a new approach to building and running data platforms and data pipelines.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex. Data lakes in various forms have been gaining significant popularity as a unified interface to an organization's analytics. Closing Announcements Thank you for listening!
Quotes It's extremely important because many of the Gen AI and LLM applications take an unstructured data approach, meaning many of the tools require you to give the tools full access to your data in an unrestricted way and let it crawl and parse it completely. Data governance is the only way to ensure those requirements are met.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. Can you describe what role Trino and Iceberg play in Stripe's data architecture?
Internally, banks are using AI to reduce the burden of datamanagement, including data lineage and data quality controls, or drive efficiencies with business intelligence particularly in call centers. Those requirements can be fulfilled by leveraging cloud infrastructure and services.
Our leadership combines decades of experience in product safety and quality management with cutting-edge expertise in AI, data science and regulatory insights. We are inspired by the transformative potential of technology to solve persistent challenges in product quality and compliance that we experienced firsthand.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement This episode is supported by Code Comments, an original podcast from Red Hat. Data observability has been gaining adoption for a number of years now, with a large focus on data warehouses.
In this episode David Yaffe and Johnny Graettinger share the story behind the business and technology and how you can start using it today to build a real-time data lake without all of the headache. Stream processing technologies have been around for around a decade. Can you describe what Estuary is and the story behind it?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles. RudderStack Profiles takes the SaaS guesswork and SQL grunt work out of building complete customer profiles so you can quickly ship actionable, enriched data to every downstream team.
In this episode Tanya Bragin shares her experiences as a product manager for two major vendors and the lessons that she has learned about how teams should approach the process of tool selection. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagement Introducing RudderStack Profiles.
Summary A significant amount of time in data engineering is dedicated to building connections and semantic meaning around pieces of information. Linked datatechnologies provide a means of tightly coupling metadata with raw information. What is the overlap between knowledge graphs and "linked data products"?
For successful personalization, you need to unify your communication technology. This involves integrating customer data across various channels – like your CRM systems, data warehouses, and more – so that the most relevant and up-to-date information is used consistently in your customer interactions. Focus on high-quality data.
In this episode Pete Hunt, CEO of Dagster labs, outlines these new capabilities, how they reduce the burden on data teams, and the increased collaboration that they enable across teams and business units. Can you describe what the focus of Dagster+ is and the story behind it? What problems are you trying to solve with Dagster+?
In this episode Yingjun Wu explains how it is architected to power analytical workflows on continuous data flows, and the challenges of making it responsive and scalable. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex.
Data quality and data governance are the top data integrity challenges, and priorities. A long-term approach to your data strategy is key to success as business environments and technologies continue to evolve. However, they require a strong data foundation to be effective. Take a proactive approach.
He highlights the role of data teams in modern organizations and how Synq is empowering them to achieve this. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern datamanagementData lakes are notoriously complex. Can you describe what Synq is and the story behind it?
Different roles and tasks in the business need their own ways to access and analyze the data in the organization. In order to enable this use case, while maintaining a single point of access, the semantic layer has evolved as a technological solution to the problem. What do you have planned for the future of Cube?
Summary This podcast started almost exactly six years ago, and the technology landscape was much different than it is now. In that time there have been a number of generational shifts in how data engineering is done. Parting Question From your perspective, what is the biggest gap in the tooling or technology for datamanagement today?
Summary Artificial intelligence technologies promise to revolutionize business and produce new sources of value. Colleen Tartow has worked across all stages of the data lifecycle, and in this episode she shares her hard-earned wisdom about how to conduct an AI program for your organization.
Summary Data processing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up. What do you have planned for the future of your academic research?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content