This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the primary focuses of a Data Engineer's work is on the Hadoop data lakes. NoSQL databases are often implemented as a component of datapipelines. Data engineers may choose from a variety of career paths, including those of Database Developer, Data Engineer, etc.
They should know SQL queries, SQL Server Reporting Services (SSRS), and SQL Server Integration Services (SSIS) and a background in DataMining and Data Warehouse Design. Data Architects, or Big Data Engineers, ensure the data availability and quality for Data Scientists and Data Analysts.
They also look into implementing methods that improve data readability and quality, along with developing and testing architectures that enable data extraction and transformation. Skills along the lines of DataMining, Data Warehousing, Math and statistics, and Data Visualization tools that enable storytelling.
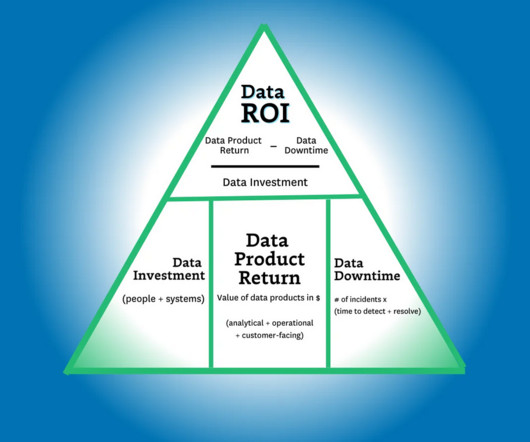
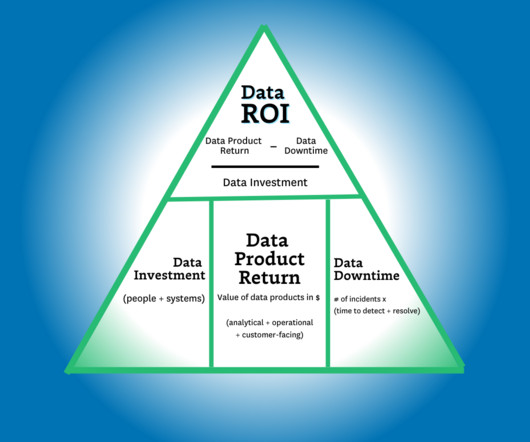
Time to build and maintain — The time it takes to build and maintain your key data assets, including data products and machine learning capabilities, is a key lever that measures your data team’s productivity. Time to insight (or action) — This lever is focused on the time it takes your data consumers to realize value.
Let us take a look at the top technical skills that are required by a data engineer first: A. Technical Data Engineer Skills 1.Python Python is ubiquitous, which you can use in the backends, streamline data processing, learn how to build effective data architectures, and maintain large data systems.
They deploy and maintain database architectures, research new data acquisition opportunities, and maintain development standards. Average Annual Salary of Data Architect On average, a data architect makes $165,583 annually. They manage data storage and the ETL process. It may go as high as $211,000!
Therefore, you can rest confident that our recommended software is reliable and potent enough to help you extract value from your data, whether you have your datapipeline and warehouse or are employing big data analytics providers. Importance of Big Data Analytics Tools Using Big Data Analytics has a lot of benefits.
Data analytics, datamining, artificial intelligence, machine learning, deep learning, and other related matters are all included under the collective term "data science" When it comes to data science, it is one of the industries with the fastest growth in terms of income potential and career opportunities.
Certified Azure Data Engineers are frequently hired by businesses to convert unstructured data into useful, structured data that data analysts and data scientists can use. Emerging Jobs Report, data engineer roles are growing at a 35 percent annual rate. What does an Azure Data Engineer Do?
The biggest challenge is broken datapipelines due to highly manual processes. Figure 1 shows a manually executed data analytics pipeline. The data engineer then emails the BI Team, who refreshes a Tableau dashboard. Figure 1: Example datapipeline with manual processes.
Trend analysis in data science is a technical analysis technique that attempts to forecast future stock price movements using recently observed trend data. Scalability in Artificial Intelligence Today's businesses have a confluence of statistics, systems architecture, machine learning deployments, and datamining.
The job of an Azure Data Engineer is really needed in the world of handling and studying data. As Azure Data Engineers, they'll be responsible for creating and looking after solutions that use data to help the company. In the United States, the average Microsoft-certified Azure Data Engineer associate salary is $130,982.
Apache Kafka is the most widely used open-source stream-processing solution for gathering, processing, storing, and analyzing large amounts of data. The platform has many benefits, including building datapipelines , using real-time data streams, supporting operational analytics, and integrating data from various sources.
Data Engineering Data engineering is a process by which data engineers make data useful. Data engineers design, build, and maintain datapipelines that transform data from a raw state to a useful one, ready for analysis or data science modeling.
Mining of Massive Datasets By Jure Leskovec, Anand Rajaraman, Jeff Ullma This book will provide a comprehensive understanding of large-scale datamining and network analysis. Web Scraping Web scraping knowledge is one of the basic requirements to become a data scientist or analyst to develop completely automated systems.
Identify source systems and potential problems such as data quality, data volume, or compatibility issues. Step 2: Extract data: extracts the necessary data from the source system. This API may include using SQL queries or other datamining tools. It can handle huge data and is highly scalable.
KNIME: KNIME is another widely used open-source and free data science tool that helps in data reporting, data analysis, and datamining. With this tool, data science professionals can quickly extract and transform data.
Big Data Engineers are professionals who handle large volumes of structured and unstructured data effectively. They are responsible for changing the design, development, and management of datapipelines while also managing the data sources for effective data collection.
Companies frequently hire certified Azure Data Engineers to convert unstructured data into useful, structured data that data analysts and data scientists can use. Data infrastructure, data warehousing, datamining, data modeling, etc.,
Qubole Using ad-hoc analysis in machine learning, it fetches data from a value chain using open-source technology for big data analytics. Qubole provides end-to-end services in moving datapipelines with reduced time and effort. Multi-source data can be migrated to one location through this tool.
He has also completed courses in data analysis, applied data science, data visualization, datamining, and machine learning. Eric is active on GitHub and LinkedIn, where he posts about data analytics, data science, and Python.
Online FM Music 100 nodes, 8 TB storage Calculation of charts and data testing 16 IMVU Social Games Clusters up to 4 m1.large Hadoop is used at eBay for Search Optimization and Research. 12 Cognizant IT Consulting Per client requirements Client projects in finance, telecom and retail.
In this article, we will understand the promising data engineer career outlook and what it takes to succeed in this role. What is Data Engineering? Data engineering is the method to collect, process, validate and store data. It involves building and maintaining datapipelines, databases, and data warehouses.
However, through data extraction, this hypothetical mortgage company can extract additional value from an existing business process by creating a lead list, thereby increasing their chances of converting more leads into clients. Transformation: Once the data has been successfully extracted, it enters the refinement phase.
Upskill yourself for your dream job with industry-level big data projects with source code. Business Intelligence Engineer Skills Business intelligence engineers employ their technical expertise to create and implement data warehouses, ETL procedures, and datamining models.
Real-time Data ingestion performs the utilization of data from various origins, does the data cleaning, validation, and preprocessing operations and at the end store it in the required format, either structured or unstructured. As real-time insights gain popularity, real-time data ingestion remains vital for companies worldwide.
Time to build and maintain — The time it takes to build and maintain your key data assets, including data products and machine learning capabilities, is a key lever that measures your data team’s productivity. Time to insight (or action) — This lever is focused on the time it takes your data consumers to realize value.
Engineering' relates to building and designing pipelines that help acquire, process, and transform the collected data into a usable form. Data Engineering involves designing and building datapipelines that extract, analyze, and convert data into a valuable and meaningful format for predictive and prescriptive modeling.
Role Level Mid to Senior Level Responsibilities Designing and implementing datapipelines for MongoDB databases. Extracting, transforming, and loading data from various sources into MongoDB. Create applications, databases, or datapipelines that show that you can work with MongoDB well.
As far as modeling techniques are concerned, the course covers the concept of Machine Learning, Deep Learning, Econometrics, Advanced Data Science , Basic and Advanced Statistics along with modules on DataMining Strategies.
Business Analytics For those interested in leveraging data science for business objectives, these courses teach skills like statistical analysis, datamining, optimization and data visualization to derive actionable insights. Capstone projects involve analyzing company data to drive business strategy and decisions.
Data Migration Service (DMS): It makes it simple and secure to move databases to the cloud. Analytics Amazon EMR: Web indexing, datamining, and log file analysis are examples of big data operations that may be carried out with the aid of Amazon EMR or Amazon Elastic MapReduce.
Automation and DataOps for Improved Data Analytics Automation and DataOps (Data Operations) are emerging technologies that improve data analytics by streamlining and automating various tasks involved in the datapipeline. Consequently, automation tools reduce manual effort and increase efficiency.
What is Data Engineering? Data engineering is all about building, designing, and optimizing systems for acquiring, storing, accessing, and analyzing data at scale. Data engineering builds datapipelines for core professionals like data scientists, consumers, and data-centric applications.
mllib.fpm- Frequent Pattern Matching has been an important topic in datamining research for years now. Frequent pattern matching is often among the initial steps in analyzing a large-scale dataset, mining recurring items, itemsets, subsequences, or other components.
Statistical Knowledge : It is vital to be familiar with statistical procedures and techniques in order to assess data and form trustworthy conclusions. DataMining and ETL : For gathering, transforming, and integrating data from diverse sources, proficiency in datamining techniques and Extract, Transform, Load (ETL) processes is required.
This type of analytics, like others, involves the use of various datamining and data aggregation tools to get more transparent information for business planning. To avoid these types of errors, OLAP database are fronted by a datapipeline that cleans and validates every new record before it is inserted to the database.
Data Sourcing: Building pipelines to source data from different company data warehouses is fundamental to the responsibilities of a data engineer. So, work on projects that guide you on how to build end-to-end ETL/ELT datapipelines. It is the process in which new bitcoins are entered into rotation.
Analysis Layer: The analysis layer supports access to the integrated data to meet its business requirements. The data may be accessed to issue reports or to find any hidden patterns in the data. Datamining may be applied to data to dynamically analyze the information or simulate and analyze hypothetical business scenarios.
Centralize data resources Data Science Platforms have a unified location for all work. Handle very large amounts of structured and unstructured data They help in the smooth handling of large GBs of data 4. No code options Even people with no coding knowledge can work on these platforms with the help of no-code tools 6.
Automate DataPipelinesDatapipelines are the data engineering architecture patterns through which the information travels. It is a method using which the data gathered from different sources get ported to a data warehouse. Keep a record of everything right from the time of data sourcing.
In Big Data systems, data can be left in its raw form and subsequently filtered and structured as needed for specific analytical needs. In other circumstances, it is preprocessed using datamining methods and data preparation software to prepare it for ordinary applications. .
Some amount of experience working on Python projects can be very helpful to build up data analytics skills. 1) Market Basket Analysis Market Basket Analysis is essentially a datamining technique to better understand customers and correspondingly increase sales.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content