This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our customers rely on NiFi as well as the associated sub-projects (Apache MiNiFi and Registry) to connect to structured, unstructured, and multi-modal data from a variety of data sources – from edge devices to SaaS tools to server logs and change data capture streams. Cloudera DataFlow 2.9
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset.
The AI Data Engineer: A Role Definition AI Data Engineers play a pivotal role in bridging the gap between traditional data engineering and the specialized needs of AI workflows. Their expertise lies in enabling seamless data integration into machine learning models, ensuring AI systems perform efficiently and effectively.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and datapipelines. What are the features and focus of Pieces that might encourage someone to use it over the alternatives?
The Ten Standard Tools To Develop DataPipelines In Microsoft Azure. While working in Azure with our customers, we have noticed several standard Azure tools people use to develop datapipelines and ETL or ELT processes. We counted ten ‘standard’ ways to transform and set up batch datapipelines in Microsoft Azure.
But let’s be honest, creating effective, robust, and reliable datapipelines, the ones that feed your company’s reporting and analytics, is no walk in the park. From building the connectors to ensuring that data lands smoothly in your reporting warehouse, each step requires a nuanced understanding and strategic approach.
Tableau Prep is a fast and efficient datapreparation and integration solution (Extract, Transform, Load process) for preparingdata for analysis in other Tableau applications, such as Tableau Desktop. simultaneously making raw data efficient to form insights.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of data quality tests. They are all in the realm of software, domain-specific language to help you write data quality tests.
Even if you aren’t subject to specific rules regarding data protection it is definitely worth listening to get an overview of what you should be thinking about while building and running datapipelines. Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo!
Managing complex datapipelines is a major challenge for data-driven organizations looking to accelerate analytics initiatives. Govern self-service in ThoughtSpot by using multi-structured and transformed data hosted alongside transactional systems in Snowflake. Now, that’s changing.
They’re integral specialists in data science projects and cooperate with data scientists by backing up their algorithms with solid datapipelines. Juxtaposing data scientist vs engineer tasks. One data scientist usually needs two or three data engineers. Datapreparation and cleaning.
In this first Google Cloud release, CDP Public Cloud provides built-in Data Hub definitions (see screenshot for more details) for: Data Ingestion (Apache NiFi, Apache Kafka). DataPreparation (Apache Spark and Apache Hive) .
In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. Microsoft data integration new capabilities — Few months ago I've entered the Azure world. dbt, as of today, is the leading framework.
In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. Microsoft data integration new capabilities — Few months ago I've entered the Azure world. dbt, as of today, is the leading framework.
DataOps can and should be implemented in small steps that complement and build upon existing workflows and datapipelines. Lean DataOps relies upon the DataKitchen DataOps Platform , which attaches to your existing datapipelines and toolchains and serves as a process hub.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle.
In this episode founder Shayan Mohanty explains how he and his team are bringing software best practices and automation to the world of machine learning datapreparation and how it allows data engineers to be involved in the process. Data stacks are becoming more and more complex.
Our new Universal Data Distribution (UDD) capability, launched earlier this year, can collect data from any source and deliver it to any destination for a scalable datapipeline. UDD works on any source and destination, even outside of Cloudera, making it very easy to integrate varied data sources.
Zero-code, graphically-edited datapreparation tools and BI tools are hardly new to the marketplace, either. Have Amazon succeeded? In one sense, we’re not the best people to ask about that, because we are software engineers ourselves; we’re not the target market.
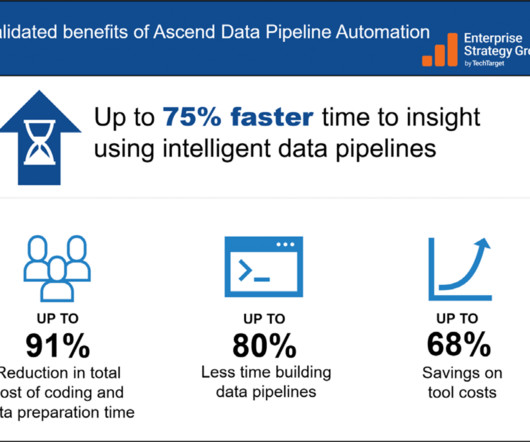
August 16, 2023 — Ascend.io , the leader in datapipeline automation, today released an economic analysis report conducted by Enterprise Strategy Group (ESG) of its DataPipeline Automation Platform.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
Being able to write and adjust any SQL queries you want on the fly on semi-structured data and across various data sources should be something every data engineer should be empowered to do. Also, data that needs to be joined typically has to be denormalized to start with. Druid supports broadcast JOINs.
Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing, and maintaining data quality. There are several types of data testing tools. This is part of a series of articles about data quality.
ChatGPT> DataOps, or data operations, is a set of practices and technologies that organizations use to improve the speed, quality, and reliability of their data analytics processes. One of the key benefits of DataOps is the ability to accelerate the development and deployment of data-driven solutions.
Picture this: your data is scattered. Datapipelines originate in multiple places and terminate in various silos across your organization. Your data is inconsistent, ungoverned, inaccessible, and difficult to use. Some of the value companies can generate from data orchestration tools include: Faster time-to-insights.
Here are some popular ETL pipeline tools: Apache Spark: The Spark ETL pipeline is a distributed computing framework that supports ETL, machine learning, and media streaming. It can handle huge data and is highly scalable. It supports various data sources and formats. However, there are some differences between the two.
Azure Data Engineers use a variety of Azure data services, such as Azure Synapse Analytics, Azure Data Factory, Azure Stream Analytics, and Azure Databricks, to design and implement data solutions that meet the needs of their organization. Gain hands-on experience using Azure data services.
Data engineering is a field that requires a range of technical skills, including database management, data modeling, and programming. Data engineering tools can help automate many of these processes, allowing data engineers to focus on higher-level tasks like extracting insights and building datapipelines.
Big Data Engineers are professionals who handle large volumes of structured and unstructured data effectively. They are responsible for changing the design, development, and management of datapipelines while also managing the data sources for effective data collection.
Pentaho published a whitepaper titled “Hadoop and the Analytic DataPipeline” that highlights the key categories which need to be focused on - Big Data Ingestion, Transformation, Analytics, Solutions. Source: [link] ) How Trifacta is helping data wranglers in Hadoop, the cloud, and beyond.Zdnet.com, November 4,2016.
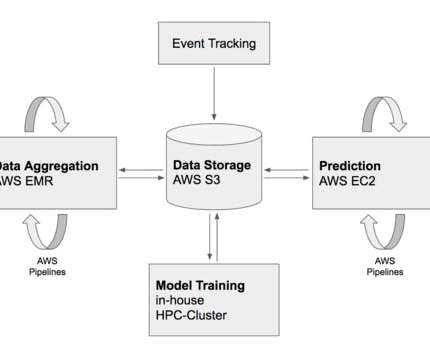
Moving deep-learning machinery into production requires regular data-aggregation-, model-training- and prediction-tasks. DataPreparation Before any machine learning is applied, data has to be gathered and organized to fit the input format of the machine learning model.
Hear me out – back in the on-premises days we had data loading processes that connect directly to our source system databases and perform huge data extract queries as the start of one long, monolithic datapipeline, resulting in our data warehouse.
Make Trusted Data Products with Reusable Modules : “Many organizations are operating monolithic data systems and processes that massively slow their data delivery time.”
Big tech companies have been able to bridge the gap between user demand and application capabilities because they have the time, money and resources to build and maintain on-premise data architectures.
Job Role 1: Azure Data Engineer Azure Data Engineers develop, deploy, and manage data solutions with Microsoft Azure data services. They use many data storage, computation, and analytics technologies to develop scalable and robust datapipelines.
You cannot expect your analysis to be accurate unless you are sure that the data on which you have performed the analysis is free from any kind of incorrectness. Data cleaning in data science plays a pivotal role in your analysis. It’s a fundamental aspect of the datapreparation stages of a machine learning cycle.
Data Engineer vs Machine Learning Engineer: Tools Data Engineer Tools: Data engineering tools are specialized programs that simplify and improve the effectiveness of designing algorithms and constructing datapipelines. It is because it can handle large data sets and distribute processing jobs over several devices.
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use.
People who are unfamiliar with unprocessed data often find it difficult to navigate data lakes. Usually, raw, unstructured data needs to be analyzed and translated by a data scientist using specialized tools. . We hope our blog will come to your rescue when choosing between a data lake and a data warehouse.
A lot of data systems that provide real-time analytics require non-trivial ETL (extract, transform, load) to get the data into the “right” shape, or may not provide the analytical functionality required by the application. Rockset’s Smart Schemas feature automatically detects and creates a schema based on the exact data present.
Big Data Engineer Big data engineers focus on the infrastructure for collecting and organizing vast amounts of data, building datapipelines, and designing data infrastructures. They manage data storage and the ETL process.
Azure data engineering professionals are required to possess the potential to overcome business challenges by combining one or more Azure Data and Azure Synapse Analytics services with datapipelines, data streams, and system integration to solve business problems. The final step is to publish your work.
It eliminates the cost and complexity around datapreparation, performance tuning and operations, helping to accelerate the movement from batch to real-time analytics. The latest Rockset release, SQL-based rollups, has made real-time analytics on streaming data a lot more affordable and accessible.
Due to the enormous amount of data being generated and used in recent years, there is a high demand for data professionals, such as data engineers, who can perform tasks such as data management, data analysis, datapreparation, etc. This exam can be taken only in the English language.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content