This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Dataprocessing technologies have dramatically improved in their sophistication and raw throughput. Unfortunately, the volumes of data that are being generated continue to double, requiring further advancements in the platform capabilities to keep up.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructured dataprocessing—a field that powers modern artificial intelligence (AI) systems. Develop modular, reusable components for end-to-end AI pipelines.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. How effective are your current dataworkflows?
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. How effective are your current dataworkflows?
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a datapipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
AI-powered data engineering solutions make it easier to streamline the data management process, which helps businesses find useful insights with little to no manual work. Real-time dataprocessing has emerged The demand for real-time data handling is expected to increase significantly in the coming years.
When implemented effectively, smart datapipelines seamlessly integrate data from diverse sources, enabling swift analysis and actionable insights. They empower data analysts and business users alike by providing critical information while protecting sensitive production systems. What is a Smart DataPipeline?
Summary Streaming dataprocessing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Data lakes are notoriously complex. Data lakes are notoriously complex.
Faster, easier AI/ML and data engineering workflows Explore, analyze and visualize data using Python and SQL. Discover valuable business insights through exploratory data analysis. Develop scalable datapipelines and transformations for data engineering.
I finally found a good critique that discusses its flaws, such as multi-hop architecture, inefficiencies, high costs, and difficulties maintaining data quality and reusability. The article advocates for a "shift left" approach to dataprocessing, improving data accessibility, quality, and efficiency for operational and analytical use cases.
Just as a watchmaker meticulously adjusts every tiny gear and spring in harmonious synchrony for flawless performance, modern datapipeline optimization requires a similar level of finesse and attention to detail. Learn how cost, processing speed, resilience, and data quality all contribute to effective datapipeline optimization.
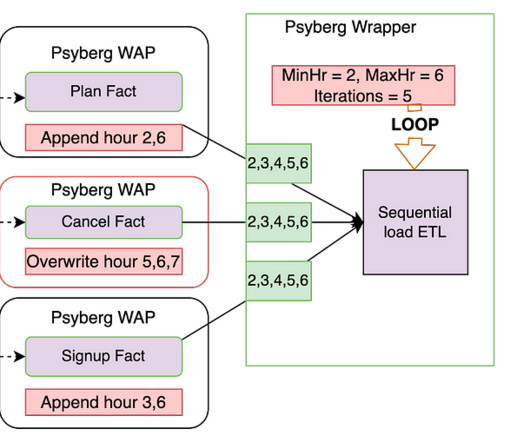
In the previous installments of this series, we introduced Psyberg and delved into its core operational modes: Stateless and Stateful DataProcessing. Now, let’s explore the state of our pipelines after incorporating Psyberg. This ensures that the next instance of the workflow will pick up newer updates.
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
These engineering functions are almost exclusively concerned with datapipelines, spanning ingestion, transformation, orchestration, and observation — all the way to data product delivery to the business tools and downstream applications. Pipelines need to grow faster than the cost to run them.
This not only jeopardizes the integrity and robustness of production environments but also compounds challenges for both data scientists and engineers. This article delves into the reasons behind our assertion: data science notebooks are not your best choice for production datapipelines. What Are Jupyter Notebooks?
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. Data Ingestion Data ingestion is the first step of both ETL and datapipelines.
Matt Harrison is a Python expert with a long history of working with data who now spends his time on consulting and training. Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud. The only thing worse than having bad data is not knowing that you have it.
In this post, we will help you quickly level up your overall knowledge of datapipeline architecture by reviewing: Table of Contents What is datapipeline architecture? Why is datapipeline architecture important? What is datapipeline architecture? Why is datapipeline architecture important?
For each data logs table, we initiate a new worker task that fetches the relevant metadata describing how to correctly query the data. Once we know what to query for a specific table, we create a task for each partition that executes a job in Dataswarm (our datapipeline system).
Airflow — An open-source platform to programmatically author, schedule, and monitor datapipelines. Apache Oozie — An open-source workflow scheduler system to manage Apache Hadoop jobs. DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively.
Since all of Fabric’s tools run natively on OneLake, real-time performance without data duplication is possible in Direct Lake mode. Because of the architecture’s ability to abstract infrastructure complexity, users can focus solely on dataworkflows.
Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder. The only thing worse than having bad data is not knowing that you have it. Bigeye let’s data teams measure, improve, and communicate the quality of your data to company stakeholders.
This methodology emphasizes automation, collaboration, and continuous improvement, ensuring faster, more reliable dataworkflows. With dataworkflows growing in scale and complexity, data teams often struggle to keep up with the increasing volume, variety, and velocity of data. Let’s dive in!
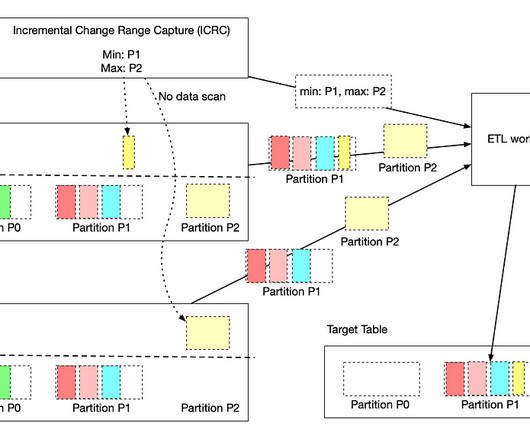
IPS provides the incremental processing support with data accuracy, data freshness, and backfill for users and addresses many of the challenges in workflows. IPS enables users to continue to use the dataprocessing patterns with minimal changes. Note that the backfill support is skipped in this blog.
DataOps improves the robustness, transparency and efficiency of dataworkflows through automation. For example, DataOps can be used to automate data integration. Previously, the consulting team had been using a patchwork of ETL to consolidate data from disparate sources into a data lake.
Start small, then scale With dataworkflows growing in scale and complexity, data teams often struggle to keep up with the increasing volume, variety, and velocity of data. This is where DataOps comes ina methodology designed to streamline and automate dataworkflows, ensuring faster and more reliable data delivery.
DataOps , short for data operations, is an emerging discipline that focuses on improving the collaboration, integration, and automation of dataprocesses across an organization. Each type of tool plays a specific role in the DataOps process, helping organizations manage and optimize their datapipelines more effectively.
Managing and orchestrating dataworkflows efficiently is crucial in today’s data-driven world. As the amount of data constantly increases with each passing day, so does the complexity of the pipelines handling such dataprocesses.
AI-driven data quality workflows deploy machine learning to automate data cleansing, detect anomalies, and validate data. Integrating AI into dataworkflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
From there, you can address more complex use cases, such as creating a 360-degree view of customers by integrating systems across CRM, ERP, marketing applications, social media handles and other data sources. This smoothes out workflows and helps teams swiftly mitigate potential issues.
Here’s the deal: for data to truly drive your business forward, you need a reliable and scalable system to keep it moving without hiccups. In other words, you need data orchestration. In this article, we’ll break down what data orchestration is, its significance, and how it differs from datapipeline orchestration.
DataOps is a collaborative approach to data management that combines the agility of DevOps with the power of data analytics. It aims to streamline data ingestion, processing, and analytics by automating and integrating various dataworkflows.
Read Time: 1 Minute, 48 Second RETRY LAST: In modern dataworkflows, tasks are often interdependent, forming complex task chains. Ensuring the reliability and resilience of these workflows is critical, especially when dealing with production datapipelines.
Overcoming Challenges to Achieve Data Timeliness Despite the clear benefits of timely data, organizations often encounter several hurdles: Complex DataPipelines: Intricate datapipelines that involve multiple stages and dependencies can hinder smooth data flow.
In the same way, a DataOps engineer designs the data assembly line that enables data scientists to derive insights from data analytics faster and with fewer errors. DataOps engineers improve the speed and quality of the data development process by applying DevOps principles to dataworkflow, known as DataOps.
It emphasizes the importance of collaboration between different teams, such as data engineers, data scientists, and business analysts, to ensure that everyone has access to the right data at the right time. This includes data ingestion, processing, storage, and analysis.
That’s what we call a datapipeline. It could just as well be ‘ELT for Snowflake’ The key takeaway is that these terms are representative of the actual activity being undertaken: the construction and management of datapipelines within the Snowflake environment.
It enhances data quality, governance, and optimization, making data retrieval more efficient and enabling powerful automation in data engineering processes. As practitioners using metadata to fuel data teams, we at Ascend understand the critical role it plays in organizing, managing, and optimizing dataworkflows.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, dataworkflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? They are also accountable for communicating data trends.
At Ascend, we recognize the immense potential in integrating these advanced AI capabilities into our platform, enabling smarter applications and more efficient dataworkflows. Snowflake’s investment in expanding data engineering capabilities is a game-changer. Curious to see Cortex in Action?
DuckDB’s parallel execution capabilities can help DBAs improve the performance of dataprocessing tasks. Researchers : Academics and researchers working with large volumes of data use DuckDB to process and analyze their data more efficiently. What makes DuckDB different?
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining datapipelines, data storage solutions, dataprocessing, and data integration to enable data-driven decision-making inside a company.
and we have now migrated the data from our transactional database to the Snowflake data warehouse. Now we can easily create data streams and create a CDC mechanism in Snowflake. The success is true so let’s now verify this change in our snowflake table.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content