This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We created data logs as a solution to provide users who want more granular information with access to data stored in Hive. In this context, an individual data log entry is a formatted version of a single row of data from Hive that has been processed to make the underlying datatransparent and easy to understand.
This robust environment makes it possible to scale to any level and support any complex data type, so companies can focus on analyzing information instead of manually integrating data. Gluent provides functionality to move data from proprietary relational database systems to Cloudera and then query that datatransparently.
While both data provenance vs. data lineage are mechanisms for understanding data at early stages, they differ in use cases. Data provenance is useful for validating and auditing data. Data lineage is useful for optimizing and troubleshooting datapipelines.
While both data provenance vs. data lineage are mechanisms for understanding data at early stages, they differ in use cases. Data provenance is useful for validating and auditing data. Data lineage is useful for optimizing and troubleshooting datapipelines.
Thus, data engineering can be regarded as the primary step for data analysis. These engineers work in tandem with data scientists to improve datatransparency and assist in effective decision-making. Datapipelining, implementing and maintaining databases are some of the main roles of a data engineer.
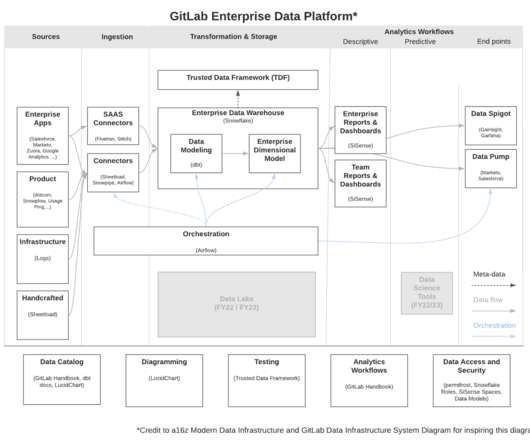
It takes work to create and maintain—and at GitLab, radical transparency means sharing almost everything. Internally and externally, from organizational structures to first drafts to self-serve data, transparency is the name of the game. For a long time, GitLab used a homegrown system in an attempt to handle data reliability.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content