This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Summary Datapipelines are complicated and business critical pieces of technical infrastructure. What are some of the types of checks and assertions that can be made about a pipeline using Great Expectations? What are some of the types of checks and assertions that can be made about a pipeline using Great Expectations?
Streamline DataPipelines: How to Use WhyLogs with PySpark for Effective Data Profiling and Validation Photo by Evan Dennis on Unsplash Datapipelines, made by data engineers or machine learning engineers, do more than just prepare data for reports or training models. So let’s dive in!
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. Pandera, a datavalidation library for dataframes, now supports Polars. It's inspirational.
Read Time: 2 Minute, 34 Second Introduction In modern datapipelines, especially in cloud data platforms like Snowflake, data ingestion from external systems such as AWS S3 is common. In this blog, we introduce a Snowpark-powered DataValidation Framework that: Dynamically reads data files (CSV) from an S3 stage.
The Definitive Guide to DataValidation Testing Datavalidation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. It’s also important to understand the limitations of datavalidation testing.
It is important to note that normalization often overlaps with the data cleaning process, as it helps to ensure consistency in data formats, particularly when dealing with different sources or inconsistent units. DataValidationDatavalidation ensures that the data meets specific criteria before processing.
How Organizations Can Overcome Data Quality and Availability Challenges Many businesses are shifting toward real-time datapipelines to ensure their AI and analytics strategies are built on reliable information. Enabling AI & ML with Adaptive DataPipelines AI models require ongoing updates to stay relevant.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
[link] Atlassian: Lithium - elevating ETL with ephemeral and self-hosted pipelines The article introduces Lithium, an ETL++ platform developed by Atlassian for dynamic and ephemeral datapipelines, addressing unique needs like user-initiated migrations and scheduled backups. million entities per second in production.
Data Quality and Governance In 2025, there will also be more attention paid to data quality and control. Companies now know that bad data quality leads to bad analytics and, ultimately, bad business strategies. Companies all over the world will keep checking that they are following global data security rules like GDPR.
Going into the DataPipeline Automation Summit 2023, we were thrilled to connect with our customers and partners and share the innovations we’ve been working on at Ascend. The summit explored the future of datapipeline automation and the endless possibilities it presents.
.” homegenius’ data challenges homegenius’ data engineering team had three big data challenges it needed to solve, according to Goodrich. The data science team needed data transformations to happen quicker, the quality of datavalidations to be better, and the turnaround time for pipeline testing to be faster.
I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current datapipeline architecture and ask why data quality is expensive. Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the datapipeline.
To achieve accurate and reliable results, businesses need to ensure their data is clean, consistent, and relevant. This proves especially difficult when dealing with large volumes of high-velocity data from various sources. Sherlock monitors your data streams to identify sensitive information.
Airflow — An open-source platform to programmatically author, schedule, and monitor datapipelines. DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. Soda Data Monitoring — Soda tells you which data is worth fixing.
Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
Bad data can infiltrate at any point in the data lifecycle, so this end-to-end monitoring helps ensure there are no coverage gaps and even accelerates incident resolution. Data and datapipelines are constantly evolving and so data quality monitoring must as well,” said Lior.
Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc., Hevo Data is a highly reliable and intuitive datapipeline platform used by data engineers from 40+ countries to set up and run low-latency ELT pipelines with zero maintenance.
These strategies can prevent delayed discovery of quality issues during data observability monitoring in production. Below is a summary of recommendations for proactively identifying and fixing flaws before they impact production data. Saves time by automating routine validation tasks and preventing costly downstream errors.
Each type of tool plays a specific role in the DataOps process, helping organizations manage and optimize their datapipelines more effectively. Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. In this article: Why Are DataOps Tools Important?
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools. This is part of a series of articles about data quality.
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools. This is part of a series of articles about data quality.
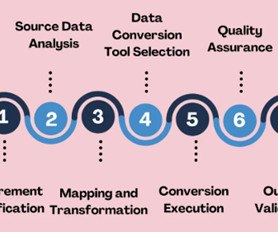
Selecting the strategies and tools for validatingdata transformations and data conversions in your datapipelines. Introduction Data transformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make collecting data from every application, website, and SaaS platform easy, then activating it in your warehouse and business tools. Sign up free to test out the tool today.
How dbt Core aids data teams test, validate, and monitor complex data transformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based data transformations, has become a must-have tool for modern data teams as the complexity of datapipelines grows.
The blog further emphasizes its increased investment in Data Mesh and clean data. link] Databricks: PySpark in 2023 - A Year in Review Can we safely say PySpark killed Scala-based datapipelines? The Netflix blog emphasizes the importance of finding the zombie data and the system design around deleting unused data.
Proper Planning and Designing of the DataPipeline The first step towards successful ELT implementation is proper planning and design of the datapipeline. This involves understanding the business requirements, the source and type of data, the desired output, and the resources required for the ELT process.
It emphasizes the importance of collaboration between different teams, such as data engineers, data scientists, and business analysts, to ensure that everyone has access to the right data at the right time. This includes data ingestion, processing, storage, and analysis.
In this article, we assess: The role of the data warehouse on one hand, and the data lake on the other; The features of ETL and ELT in these two architectures; The evolution to EtLT; The emerging role of datapipelines. Let’s take a closer look. Enterprises have an opportunity to undergo a metamorphosis.
Alteryx is a visual data transformation platform with a user-friendly interface and drag-and-drop tools. Nonetheless, Alteryx may have difficulties to cope with the complexity increase within an organization’s datapipeline, and it can become a suboptimal tool when companies start dealing with large and complex data transformations.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into datavalidation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
In this article, we present six intrinsic data quality techniques that serve as both compass and map in the quest to refine the inner beauty of your data. Data Profiling 2. Data Cleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Table of Contents 1.
Accurate data ensures that these decisions and strategies are based on a solid foundation, minimizing the risk of negative consequences resulting from poor data quality. There are various ways to ensure data accuracy. Data cleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Themes I was drawn to the articles that speak to a theme in the data world that I am passionate about: how datapipelines and data team practices are evolving to be more like traditional product development. 7 Be Intentional About the Batching Model in Your DataPipelines Different batching models.
GPT-Based Data Engineering Accelerators: Given below is the list of some of the GPT-based data engineering accelerators. 1. DataGPT OpenAI developed DataGpt for performing data engineering tasks. Datagpt creates code for datapipelines and transformations.
A shorter time-to-value indicates that your organization is efficient at processing and analyzing data for decision-making purposes. Monitoring this metric helps identify bottlenecks in the datapipeline and ensures timely insights are available for business users.
It plays a critical role in ensuring that users of the data can trust the information they are accessing. There are several ways to ensure data consistency, including implementing datavalidation rules, using data standardization techniques, and employing data synchronization processes.
Despite these challenges, proper data acquisition is essential to ensure the data’s integrity and usefulness. DataValidation In this phase, the data that has been acquired is checked for accuracy and consistency.
Validity rules & dimension drift Writing rules for accepted values for low cardinality fields and datavalidity can be tedious. Coverage for ‘unknown unknown’ issues are some of the most important monitors for data teams to create—and they’re also the checks that most often get missed. No rules required.
My next gig was in consulting where I bootstrapped my way into data engineering and had to learn the whole gamut below. But in practice, I was babysitting brittle datapipelines. To enable dozens of people was mind-numbing, much less hundreds of data analysts to all work elegantly together. 5x data engineer.
Use modular design: Divide the pipeline into small individual parts that can be independently tested and adjusted. Datavalidation: Datavalidation as it goes through the pipeline to ensure it meets the necessary quality standards and is appropriate for the final goal.
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content