This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why Future-Proofing Your DataPipelines Matters Data has become the backbone of decision-making in businesses across the globe. The ability to harness and analyze data effectively can make or break a company’s competitive edge. Resilience and adaptability are the cornerstones of a future-proof datapipeline.
Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. Pandera, a datavalidation library for dataframes, now supports Polars. This is Croissant. It's inspirational.
Streamline DataPipelines: How to Use WhyLogs with PySpark for Effective Data Profiling and Validation Photo by Evan Dennis on Unsplash Datapipelines, made by data engineers or machine learning engineers, do more than just prepare data for reports or training models. So let’s dive in!
Filling in missing values could involve leveraging other company data sources or even third-party datasets. The cleaned data would then be stored in a centralized database, ready for further analysis. This ensures that the sales data is accurate, reliable, and ready for meaningful analysis.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
Access control based on roles (RBAC) In accordance with corporate policies, RBAC enables administrators to fine-tune who has granular access to which Fabric assets (such as data lakes, reports, and pipelines). Then, using FLIP, we will discuss and conclude the Automated Migration of DataPipelines from SSIS to Microsoft Fabric.
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Heres how they are tackling these issues: 1.
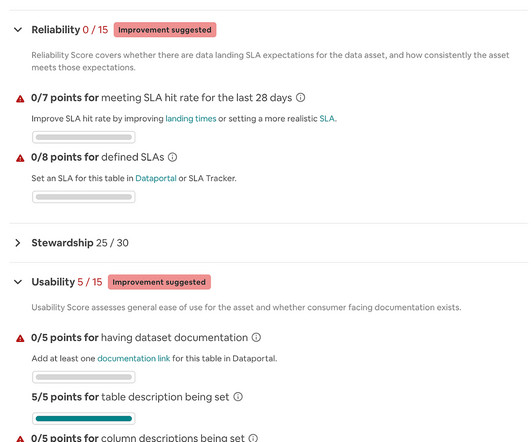
The Definitive Guide to DataValidation Testing Datavalidation testing ensures your data maintains its quality and integrity as it is transformed and moved from its source to its target destination. It’s also important to understand the limitations of datavalidation testing.
The data doesn’t accurately represent the real heights of the animals, so it lacks validity. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. Let’s dive deeper into these two crucial concepts, both essential for maintaining high-quality data. What Is DataValidity?
Going into the DataPipeline Automation Summit 2023, we were thrilled to connect with our customers and partners and share the innovations we’ve been working on at Ascend. The summit explored the future of datapipeline automation and the endless possibilities it presents.
To achieve accurate and reliable results, businesses need to ensure their data is clean, consistent, and relevant. This proves especially difficult when dealing with large volumes of high-velocity data from various sources. Sherlock monitors your data streams to identify sensitive information.
.” homegenius’ data challenges homegenius’ data engineering team had three big data challenges it needed to solve, according to Goodrich. The data science team needed data transformations to happen quicker, the quality of datavalidations to be better, and the turnaround time for pipeline testing to be faster.
Airflow — An open-source platform to programmatically author, schedule, and monitor datapipelines. DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. Soda Data Monitoring — Soda tells you which data is worth fixing.
Starburst Logo]([link] This episode is brought to you by Starburst - an end-to-end data lakehouse platform for data engineers who are battling to build and scale high quality datapipelines on the data lake.
These tools play a vital role in data preparation, which involves cleaning, transforming, and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools. This is part of a series of articles about data quality.
These tools play a vital role in data preparation, which involves cleaning, transforming and enriching raw data before it can be used for analysis or machine learning models. There are several types of data testing tools. This is part of a series of articles about data quality.
These strategies can prevent delayed discovery of quality issues during data observability monitoring in production. Below is a summary of recommendations for proactively identifying and fixing flaws before they impact production data. Saves time by automating routine validation tasks and preventing costly downstream errors.
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset.
Photo by Markus Spiske on Unsplash Introduction Senior data engineers and data scientists are increasingly incorporating artificial intelligence (AI) and machine learning (ML) into datavalidation procedures to increase the quality, efficiency, and scalability of data transformations and conversions.
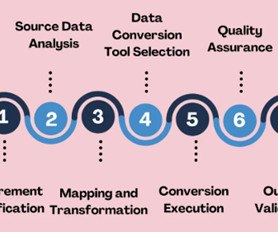
Selecting the strategies and tools for validatingdata transformations and data conversions in your datapipelines. Introduction Data transformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
GPT-Based Data Engineering Accelerators: Given below is the list of some of the GPT-based data engineering accelerators. 1. DataGPT OpenAI developed DataGpt for performing data engineering tasks. Datagpt creates code for datapipelines and transformations. Its technology is based on transformer architecture.
Data Profiling 2. Data Cleansing 3. DataValidation 4. Data Auditing 5. Data Governance 6. Use of Data Quality Tools Refresh your intrinsic data quality with data observability 1. Data Profiling Data profiling is getting to know your data, warts and quirks and secrets and all.
Key Takeaways Data quality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies.
Accurate data ensures that these decisions and strategies are based on a solid foundation, minimizing the risk of negative consequences resulting from poor data quality. There are various ways to ensure data accuracy. Data cleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Data cleaning is an essential step to ensure your data is safe from the adage “garbage in, garbage out.” Because effective data cleaning best practices fix and remove incorrect, inaccurate, corrupted, duplicate, or incomplete data in your dataset; data cleaning removes the garbage before it enters your pipelines.
Table of Contents What Does an AI Data Quality Analyst Do? An AI Data Quality Analyst should be comfortable with: Data Management : Proficiency in handling large datasets. Data Cleaning and Preprocessing : Techniques to identify and remove errors. Attention to Detail : Critical for identifying data anomalies.
Tracking data lineage is especially important when working with Python, as the language is so easy to use that you can end up digging your own grave if you start making large unintended changes to your most important datasets. Automated Tools for Python Data Lineage So how can we easily add data lineage to our Python workflows?
Pradheep Arjunan - Shared insights on AZ's journey from on-prem to the cloud data warehouses. Google: Croissant- a metadata format for ML-ready datasets Google Research introduced Croissant, a new metadata format designed to make datasets ML-ready by standardizing the format, facilitating easier use in machine learning projects.
There were several inputs that certainly could help us measure quality, but if they could not be automatically measured ( Automated ), or if they were so convoluted that data practitioners wouldn’t understand what the criterion meant or how it could be improved upon ( Actionable ), then they were discarded.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
Another way data ingestion enhances data quality is by enabling data transformation. During this phase, data is standardized, normalized, and enriched. Data enrichment involves adding new, relevant information to the existing dataset, which provides more context and improves the depth and value of the data.
Regardless of the approach you choose, it’s important to keep a scrutinous eye on whether or not your data outputs are matching (or close to) your expectations; often, relying on a few of these measures will do the trick. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies.
7 Data Testing Methods, Why You Need Them & When to Use Them Helen Soloveichik August 30, 2023 What Is Data Testing? Data testing involves the verification and validation of datasets to confirm they adhere to specific requirements. In this article: Why Is Data Testing Important?
Having the data warehouse as a central source of truth can help present a more consistent view of the campaign. Screenshot of Monte Carlo’s data profiling feature, which can help with data consistency. Understand and Document the Context : Data engineers may not always have the full business context behind a dataset.
While this is a critical step in preventing larger data incidents—it doesn’t tell you how to fix an issue once you find it. Traditionally, root-causing data quality issues required manually parsing through datasets—sometimes for weeks at a time—to discover the source of a particular data anomaly.
While this is a critical step in preventing larger data incidents—it doesn’t tell you how to fix an issue once you find it. Traditionally, root-causing data quality issues required manually parsing through datasets—sometimes for weeks at a time—to discover the source of a particular data anomaly.
Re-Imagining Data Observability Ryan Yackel 2022-11-04 10:36:35 Data observability has become one of the hottest topics of the year – and for good reason. Data observability provides an end-to-end view into exactly what’s happening with datapipelines across an organization’s data fabric.
The value of that trust is why more and more companies are introducing Chief Data Officers – with the number doubling among the top publicly traded companies between 2019 and 2021, according to PwC. In this article: Why is data reliability important? Note that datavalidity is sometimes considered a part of data reliability.
Companies need to analyze large volumes of datasets, leading to an increase in data producers and consumers within their IT infrastructures. These companies collect data from production applications and B2B SaaS tools (e.g., This data makes its way into a data repository, like a data warehouse (e.g.,
As an Azure Data Engineer, you will be expected to design, implement, and manage data solutions on the Microsoft Azure cloud platform. You will be in charge of creating and maintaining datapipelines, data storage solutions, data processing, and data integration to enable data-driven decision-making inside a company.
The key features of the Data Load Accelerator include: Minimal and reusable coding: The model used is configuration-based and all data load requirements will be managed with one code base. Snowflake allows the loading of both structured and semi-structured datasets from cloud storage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content