This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Understand how BigQuery inserts, deletes and updates — Once again Vu took time to deep dive into BigQuery internal, this time to explain how data management is done. This is Croissant.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current datapipeline architecture and ask why data quality is expensive. Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the datapipeline.
Bad data can infiltrate at any point in the data lifecycle, so this end-to-end monitoring helps ensure there are no coverage gaps and even accelerates incident resolution. Data and datapipelines are constantly evolving and so data quality monitoring must as well,” said Lior.
There were several inputs that certainly could help us measure quality, but if they could not be automatically measured ( Automated ), or if they were so convoluted that data practitioners wouldn’t understand what the criterion meant or how it could be improved upon ( Actionable ), then they were discarded.
A shorter time-to-value indicates that your organization is efficient at processing and analyzing data for decision-making purposes. Monitoring this metric helps identify bottlenecks in the datapipeline and ensures timely insights are available for business users.
Selecting the strategies and tools for validatingdata transformations and data conversions in your datapipelines. Introduction Data transformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. This process also creates a sqlite database for storing the metadata of the pipeline process.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. For example, grouping the ones about metadata, discoverability, and column naming might have made a lot of sense.
Each type of tool plays a specific role in the DataOps process, helping organizations manage and optimize their datapipelines more effectively. Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. In this article: Why Are DataOps Tools Important?
How dbt Core aids data teams test, validate, and monitor complex data transformations and conversions Photo by NASA on Unsplash Introduction dbt Core, an open-source framework for developing, testing, and documenting SQL-based data transformations, has become a must-have tool for modern data teams as the complexity of datapipelines grows.
In this article, we assess: The role of the data warehouse on one hand, and the data lake on the other; The features of ETL and ELT in these two architectures; The evolution to EtLT; The emerging role of datapipelines. Let’s take a closer look.
If the transformation step comes after loading (for example, when data is consolidated in a data lake or a data lakehouse ), the process is known as ELT. You can learn more about how such datapipelines are built in our video about data engineering. The essential components of the virtual layer are.
Here is a list of the most popular tools for data lineage in Python: OpenLineage and Marquez : OpenLineage is an open framework for data lineage collection and analysis. Marquez is a metadata service that implements the OpenLineage API.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack provides datapipelines that make it easy to collect data from every application, website, and SaaS platform, then activate it in your warehouse and business tools. Sign up free to test out the tool today.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
This requires implementing robust data integration tools and practices, such as datavalidation, data cleansing, and metadata management. These practices help ensure that the data being ingested is accurate, complete, and consistent across all sources.
Pradheep Arjunan - Shared insights on AZ's journey from on-prem to the cloud data warehouses. Google: Croissant- a metadata format for ML-ready datasets Google Research introduced Croissant, a new metadata format designed to make datasets ML-ready by standardizing the format, facilitating easier use in machine learning projects.
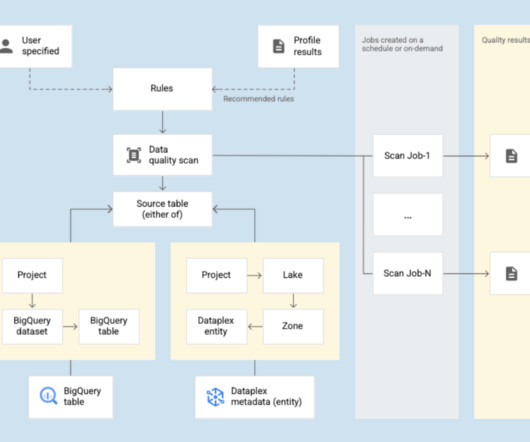
With Dataplex, teams get lineage and visibility into their data management no matter where it’s housed, centralizing the security, governance, search and discovery across potentially distributed systems. Dataplex works with your metadata. The SQL expression should evaluate to true (pass) or false (fail) per row.
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Re-Imagining Data Observability Ryan Yackel 2022-11-04 10:36:35 Data observability has become one of the hottest topics of the year – and for good reason. Data observability provides an end-to-end view into exactly what’s happening with datapipelines across an organization’s data fabric.
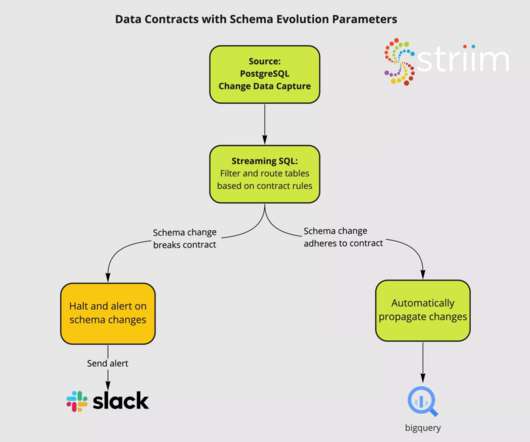
A data contract is a formal agreement between the users of a source system and the data engineering team that is extracting data for a datapipeline. This data is loaded into a data repository — such as a data warehouse — where it can be transformed for end users. temperature).
This results in rallying 26 team members—likely the cream of the crop—to spend an entire day investigating the problem, only to discover that a single blank field passed through the datapipeline was the culprit. This existing paradigm fails to address the challenges and intricacies of “Data in Use.”
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Data cleansing: Implement corrective measures to address identified issues and improve dataset accuracy levels.
Integrating these principles with data operation-specific requirements creates a more agile atmosphere that supports faster development cycles while maintaining high quality standards. Organizations need to automate various aspects of their data operations, including data integration, data quality, and data analytics.
Regardless of the approach you choose, it’s important to keep a scrutinous eye on whether or not your data outputs are matching (or close to) your expectations; often, relying on a few of these measures will do the trick. Contextual understanding: Data quality is also influenced by the availability of relevant contextual information.
Data Governance Examples Here are some examples of data governance in practice: Data quality control: Data governance involves implementing processes for ensuring that data is accurate, complete, and consistent. This may involve datavalidation, data cleansing, and data enrichment activities.
All of these options allow you to define the schema of the contract, describe the data, and store relevant metadata like semantics, ownership, and constraints. We can specify the fields of the contract in addition to metadata like ownership, SLA, and where the table is located. Consistency in your tech stack.
Why is HDFS only suitable for large data sets and not the correct tool for many small files? NameNode is often given a large space to contain metadata for large-scale files. The metadata should come from a single file for optimal space use and economic benefit. And storing these metadata in RAM will become problematic.
This guide provides definitions, a step-by-step tutorial, and a few best practices to help you understand ETL pipelines and how they differ from datapipelines. The crux of all data-driven solutions or business decision-making lies in how well the respective businesses collect, transform, and store data.
It allows organizations to see how data is being used, where it is coming from, its quality, and how it is being transformed. DataOps Observability includes monitoring and testing the datapipeline, data quality, data testing, and alerting. What is missing in data lineage?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content