This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where datapipeline design patterns come in. Data Mesh Pattern 8.
Along with this, you will learn how to perform data analysis using GraphX and Neo4j. Apache Zeppelin Demo Big Data Project for Data Analysis : This project is best for beginners exploring big data tools. Depending on the company you want to work with, you will be asked to learn them deeply.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Summary Every part of the business relies on data, yet only a small team has the context and expertise to build and maintain workflows and datapipelines to transform, clean, and integrate it. RudderStack’s smart customer datapipeline is warehouse-first.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Struggling with broken pipelines?
Unify your data with live connections or extracts Youre no doubt under immense pressure to deliver real-time, actionable insights to the whole business, but the journey from data to insights is often complex and time-consuming. Maybe that requires mashing data from a Google Sheet with data from your cloud datawarehouse.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Batch processing: data is typically extracted from databases at the end of the day, saved to disk for transformation, and then loaded in batch to a datawarehouse. Batch data integration is useful for data that isn’t extremely time-sensitive. Electric bills are a relevant example.
For those using a robust analytics database, such as the Snowflake® Data Cloud , adding the power of a data engineering platform can help maximize the value you’re getting out of that database. DataWarehouses Have Boundaries Datawarehouses do what they’re meant to, they provide a high-performance environment for data analytics.
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a datapipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
When implemented effectively, smart datapipelines seamlessly integrate data from diverse sources, enabling swift analysis and actionable insights. They empower data analysts and business users alike by providing critical information while protecting sensitive production systems. What is a Smart DataPipeline?
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Are you spending too much time maintaining your datapipeline? Snowplow empowers your business with a real-time event datapipeline running in your own cloud account without the hassle of maintenance. Set up a demo and mention you’re a listener for a special offer!
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring data accessibility, accuracy, and utility. However, beneath their surface lies a host of invisible risks embedded within the datawarehouse layers.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Fortunately, there’s hope: in the same way that New Relic, DataDog, and other Application Performance Management solutions ensure reliable software and keep application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. The first 25 will receive a free, limited edition Monte Carlo hat!
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
This setup is particularly beneficial for e-commerce platforms and content providers aiming to enhance user engagement through data-driven decisions. GitHub Repository: tj /iceberg-demo 3. This project provides tools and methodologies for migrating Hive tables to Iceberg, focusing on preserving data integrity and optimizing storage.
Most of what is written though has to do with the enabling technology platforms (cloud or edge or point solutions like datawarehouses) or use cases that are driving these benefits (predictive analytics applied to preventive maintenance, financial institution’s fraud detection, or predictive health monitoring as examples) not the underlying data.
Summary Data lineage is the common thread that ties together all of your datapipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold. Struggling with broken pipelines?
Summary The flexibility of software oriented data workflows is useful for fulfilling complex requirements, but for simple and repetitious use cases it adds significant complexity. Coalesce is a platform designed to reduce repetitive work for common workflows by adopting a visual pipeline builder to support your datawarehouse transformations.
Are you spending too much time maintaining your datapipeline? Snowplow empowers your business with a real-time event datapipeline running in your own cloud account without the hassle of maintenance. Set up a demo and mention you’re a listener for a special offer!
So, you’re planning a cloud datawarehouse migration. But be warned, a warehouse migration isn’t for the faint of heart. As you probably already know if you’re reading this, a datawarehouse migration is the process of moving data from one warehouse to another. A worthy quest to be sure.
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
RudderStack’s smart customer datapipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer datapipeline is warehouse-first.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Are you spending too much time maintaining your datapipeline? Snowplow empowers your business with a real-time event datapipeline running in your own cloud account without the hassle of maintenance. Set up a demo and mention you’re a listener for a special offer!
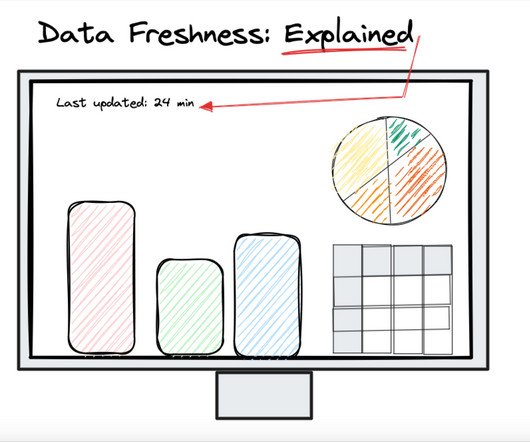
Pro-tip : Don’t confuse data freshness with data latency. Data latency is the time between when the event occurs and when the data is available in the core data system (like a datawarehouse) whereas data freshness is how recently the data within the final asset (table, BI report) has been updated.
Introduction This recipe shows how you can build a datapipeline to read data from ServiceNow and write to BigQuery. Benefits Striims unified data streaming platform empowers organizations to infuse real-time data into AI, analytics, customer experiences and operations.
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
As more organizations race to adopt GenAI and build AI-powered data products, DuckDB provides emerging applications as the storage layer of RAG knowledge bases to streamline and expedite data management. MotherDuck turbocharged DuckDB’s efficiency with multiplayer cloud analytics, making it a lightweight but powerful datawarehouse.
You work hard to make sure that your data is clean, reliable, and reproducible throughout the ingestion pipeline, but what happens when it gets to the datawarehouse? Dataform picks up where your ETL jobs leave off, turning raw data into reliable analytics.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content