This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
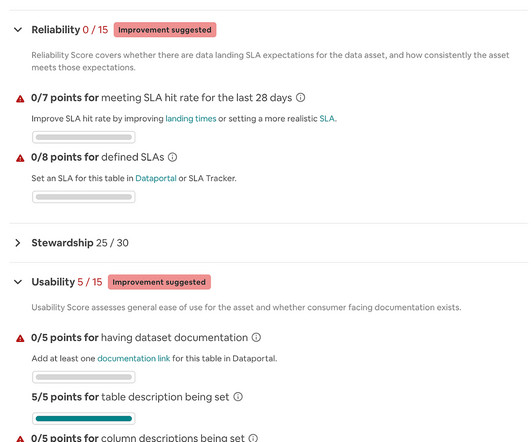
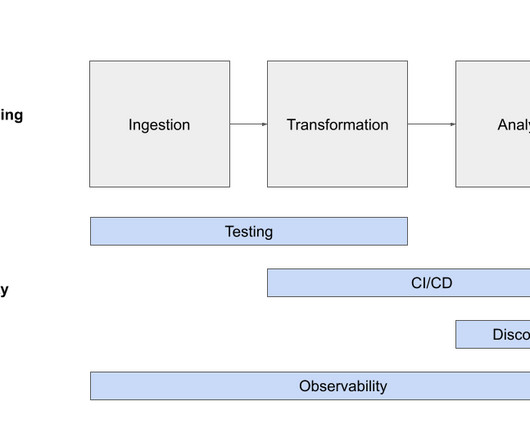
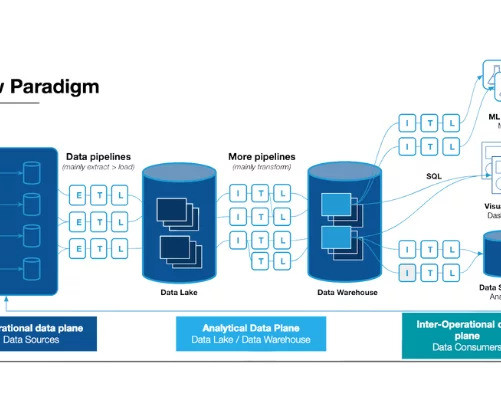
Summary A data lakehouse is intended to combine the benefits of data lakes (cost effective, scalable storage and compute) and datawarehouses (user friendly SQL interface). Data lakes are notoriously complex. Multiple open source projects and vendors have been working together to make this vision a reality.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Dagster offers a new approach to building and running data platforms and datapipelines. Starburst : 









































Let's personalize your content