This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
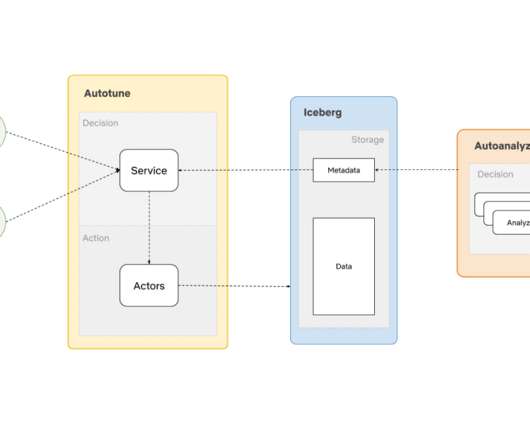
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Forward thinking Dataviz is hierarchical — Malloy, once again, provides an excellent article about a new way to see data visualisations. This is Croissant. It's inspirational.
To ensure comprehensive protection, it is essential to apply the necessary steps to all systems that store or process data, including distributed systems (web systems, chat, mobile and backend services) and datawarehouses. Consider the data flow from online systems to the datawarehouse, as shown in the diagram below.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! Are you bored with writing scripts to move data into SaaS tools like Salesforce, Marketo, or Facebook Ads?
Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1): Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom). 2 ECC data enrichment pipeline.
Summary Managing a datawarehouse can be challenging, especially when trying to maintain a common set of patterns. They provide an AWS-native, serverless, data infrastructure that installs in your VPC. Datacoral helps data engineers build and manage the flow of datapipelines without having to manage any infrastructure.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
By Anupom Syam Background At Netflix, our current datawarehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance datawarehouse.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
link] Jon Osborn: Best Practices for Using QUERY_TAG in Snowflake The modern datawarehouses are good at running at scale, given the cost is not a constraint. The service offers configurable counter types optimized for various use cases with a unified Control Plane configuration. I’ve seen a similar work by Ben E.
Meta joins the Data Transfer Project and has continuously led the development of shared technologies that enable users to port their data from one platform to another. 2024: Users can access data logs in Download Your Information. What are data logs?
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.
Data stacks are becoming more and more complex. This brings infinite possibilities for datapipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Data stacks are becoming more and more complex.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Summary Building a well managed data ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
What is the importance of embedding column-level lineage awareness into transformation tool vs. layering on top w/ dedicated lineage/metadata tooling? What are the most interesting, innovative, or unexpected ways that you have seen column-aware data modeling used? ML, reverse ETL, etc.) ML, reverse ETL, etc.)
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Summary Data lineage is the common thread that ties together all of your datapipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Struggling with broken pipelines? Missing data? Stale dashboards? If this resonates with you, you’re not alone.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
I’d like to discuss some popular Data engineering questions: Modern data engineering (DE). Does your DE work well enough to fuel advanced datapipelines and Business intelligence (BI)? Are your datapipelines efficient? Often it is a datawarehouse solution (DWH) in the central part of our infrastructure.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day.
Summary Building clean datasets with reliable and reproducible ingestion pipelines is completely useless if it’s not possible to find them and understand their provenance. The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Again, be prepared to have metadata challenges especially.
I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current datapipeline architecture and ask why data quality is expensive. Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the datapipeline.
Data engineering inherits from years of data practices in US big companies. Hadoop initially led the way with Big Data and distributed computing on-premise to finally land on Modern Data Stack — in the cloud — with a datawarehouse at the center. My advice on this point is to learn from others.
Modern Data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days. Once you sign up and create an alert in Datafold for your company data, they will send you a cool water flask.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
We are proud to announce the general availability of Cloudera Altus DataWarehouse , the only cloud data warehousing service that brings the warehouse to the data. Modern data warehousing for the cloud. Modern data warehousing for the cloud. Using Cloudera Altus for your cloud datawarehouse.
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring data accessibility, accuracy, and utility. However, beneath their surface lies a host of invisible risks embedded within the datawarehouse layers.
Summary The core of any data platform is the centralized storage and processing layer. For many that is a datawarehouse, but in order to support a diverse and constantly changing set of uses and technologies the data lakehouse is a paradigm that offers a useful balance of scale and cost, with performance and ease of use.
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or datawarehouse table that you are working with. Atlan is the metadata hub for your data ecosystem. Can you describe what Manta is and the story behind it?
Summary At the core of every datapipeline is an workflow manager (or several). Deploying, managing, and scaling that orchestration can consume a large fraction of a data team’s energy so it is important to pick something that provides the power and flexibility that you need.
RudderStack’s smart customer datapipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. RudderStack’s smart customer datapipeline is warehouse-first.
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
Reading Time: 7 minutes In today’s data-driven world, efficient datapipelines have become the backbone of successful organizations. These pipelines ensure that data flows smoothly from various sources to its intended destinations, enabling businesses to make informed decisions and gain valuable insights.
Your sunk costs are minimal and if a workload or project you are supporting becomes irrelevant, you can quickly spin down your cloud datawarehouses and not be “stuck” with unused infrastructure. Cloud deployments for suitable workloads gives you the agility to keep pace with rapidly changing business and data needs.
Modern Data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days. Once you sign up and create an alert in Datafold for your company data, they will send you a cool water flask.
They explain how to think about your data systems in a holistic and maintainable fashion, the security challenges that threaten to derail your efforts, and the power of using metadata as the foundation of everything that you do. Modern Data teams are dealing with a lot of complexity in their datapipelines and analytical code.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content