This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly datapipeline maintenance. They realized they needed a more automated, streamlined way to access the data.
Summary How much time do you spend maintaining your datapipeline? This was a fascinating conversation with someone who has spent his entire career working on simplifying complex data problems. Managing and auditing access to your servers and databases is a problem that grows in difficulty alongside the growth of your teams.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. The article details how these building blocks are used to implement the JSON type, which provides support for dynamically changing data, high-performance storage, scalability, and tuning options.
Bronze layers can also be the raw database tables. Next, data is processed in the Silver layer , which undergoes “just enough” cleaning and transformation to provide a unified, enterprise-wide view of core business entities. Bronze layers should be immutable. However, this architecture is not without its challenges.
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE) , the only cloud-native service purpose-built for enterprise data engineering teams. Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex datapipelines anywhere.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. That’s where our friends at Ascend.io
At the same time Maxime Beauchemin wrote a post about Entity-Centricdata modeling. In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. I hope he will fill the gaps. dbt, as of today, is the leading framework.
At the same time Maxime Beauchemin wrote a post about Entity-Centricdata modeling. In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. I hope he will fill the gaps. dbt, as of today, is the leading framework.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
A star-studded baseball team is analogous to an optimized “end-to-end datapipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a datapipeline is integral to effective data management.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data Engineers are skilled professionals who lay the foundation of databases and architecture.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. Data Ingestion Data ingestion is the first step of both ETL and datapipelines.
A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use. Ride database.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
In terms of representation, data can be broadly classified into two types: structured and unstructured. Structured data can be defined as data that can be stored in relational databases, and unstructured data as everything else. There are many implications of large unstructured data for engineering.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
Your IT organization may have a permanent data lake, but data analytics teams need the ability to rapidly create insight from data. The DataKitchen Platform serves as a process hub that builds temporary analytic databases for daily and weekly ad hoc analytics work. Figure 3: Example process hub for biologic launch.
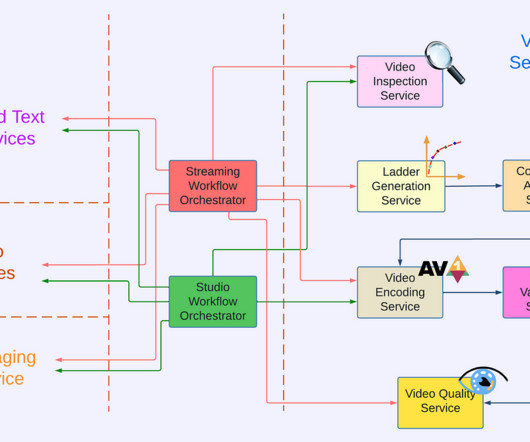
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Retrieval augmented generation (RAG) is an architecture framework introduced by Meta in 2020 that connects your large language model (LLM) to a curated, dynamic database. Data retrieval: Based on the query, the RAG system searches the database to find relevant data. A RAG flow in Databricks can be visualized like this.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Assess the needs and goals of the business.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. The author made an excellent attempt to describe what is vector databases to a 5-year-old.
It aims to explain how we transformed our development practices with a data-centric approach and offers recommendations to help your teams address similar challenges in your software development lifecycle. This approach ensured comprehensive data extraction while handling various edge cases and log formats.
Engineers work with Data Scientists to help make the most of the data they collect and have deep knowledge of distributed systems and computer science. In large organizations, data engineers concentrate on analytical databases, operate data warehouses that span multiple databases, and are responsible for developing table schemas.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable datapipelines, data storage solutions, and data processing systems.
For Ripple's product capabilities, the Payments team of Ripple, for example, ingests millions of transactional records into databases and performs analytics to generate invoices, reports, and other related payment operations. A lack of a centralized system makes building a single source of high-quality data difficult.
This provided a nice overview of the breadth of topics that are relevant to data engineering including data warehouses/lakes, pipelines, metadata, security, compliance, quality, and working with other teams. Open question: how to seed data in a staging environment? Test system with A/A test. Be adaptable.
Learn more in our detailed guide to data lineage visualization (coming soon) Integration with Multiple Data Sources Data lineage tools are designed to integrate with a wide range of data sources, including databases, data warehouses, and cloud-based data platforms.
Datos IO has extended its on-premise and public cloud data protection to RDBMS and Hadoop distributions. Its RecoverX distributed database backup product of latest version v2.0 Cloudera is more inclined on becoming a product centric business with 23% of its revenue coming from services past year in comparison to 31% for Hortonworks.
The demand for data-related professions, including data engineering, has indeed been on the rise due to the increasing importance of data-driven decision-making in various industries. Becoming an Azure Data Engineer in this data-centric landscape is a promising career choice.
But perhaps one of the most common reasons for data quality challenges are software feature updates and other changes made upstream by software engineers. These are particularly frustrating, because while they are breaking datapipelines constantly, it’s not their fault. He suggested : “Private vs. public methods.
Data engineers can find one for almost any need, from data extraction to complex transformations, ensuring that they’re not reinventing the wheel by writing code that’s already been written. Exceptional at data retrieval and manipulation within RDBMS. It's specialized for database querying.
It offers a wide range of services, including computing, storage, databases, machine learning, and analytics, making it a versatile choice for businesses looking to harness the power of the cloud. This cloud-centric approach ensures scalability, flexibility, and cost-efficiency for your data workloads.
As a result, a less senior team member was made responsible for modifying a production pipeline. Brooks law (for data): “ Adding data engineer personpower to a late data project makes it later.” Shouldn’t Marcus consider upgrading his technology? A better ETL tool? Pick some other hot tool?
Owing to the vitality of application software, businesses are actively seeking professionals with excellent technical expertise and a consumer-centric mindset to develop more practical application software systems that enhance customer experience. Database An automated data-keeping system is what a database management system (DBMS) is.
Real-time Data ingestion performs the utilization of data from various origins, does the data cleaning, validation, and preprocessing operations and at the end store it in the required format, either structured or unstructured. As real-time insights gain popularity, real-time data ingestion remains vital for companies worldwide.
They need to know everything about the data and apply various mathematical and statistical tools to identify the most significant features using feature selection, feature engineering , feature transformation, etc.
Gen AI can whip up serviceable code in moments — making it much faster to build and test datapipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. But what does that mean for the roles of data engineers and data scientists going forward?
Whether you're a seasoned data scientist or just stepping into the world of data, come with me as we unravel the secrets of data extraction and learn how it empowers us to unleash the full potential of data. What is data extraction? Patterns, trends, relationships, and knowledge discovered from the data.
Its flexibility allows it to operate on single-node machines and large clusters, serving as a multi-language platform for executing data engineering , data science , and machine learning tasks. Before diving into the world of Spark, we suggest you get acquainted with data engineering in general.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
ADF connects to various data sources, including on-premises systems, cloud services, and SaaS applications. It then gathers and relocates information to a centralized hub in the cloud using the Copy Activity within datapipelines. Transform and Enhance the Data: Once centralized, data undergoes transformation and enrichment.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content