This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many organizations struggle with: Inconsistent data formats : Different systems store data in varied structures, requiring extensive preprocessing before analysis. Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Heres how they are tackling these issues: 1.
AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products. Essential Skills for AI Data Engineers Expertise in DataPipelines and ETL Processes A foundational skill for data engineers?
Solution: To provide AI with the full spectrum of correct and relevant information, you need to integrate your most comprehensive datasets. When your AI has access to all this high-qualitydata, you gain more relevant insights that help you power better decision-making and foster trust in AI outputs.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of dataquality tests. They are all in the realm of software, domain-specific language to help you write dataquality tests.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL).
Going into the DataPipeline Automation Summit 2023, we were thrilled to connect with our customers and partners and share the innovations we’ve been working on at Ascend. The summit explored the future of datapipeline automation and the endless possibilities it presents.
Supporting highqualitydatasets with strong guarantees for data completeness and latency requires an extremely robust data ingestion platform that becomes particularly complex at scale. Upstream data evolution breaks pipelines. Missed Nishith’s 5 considerations?
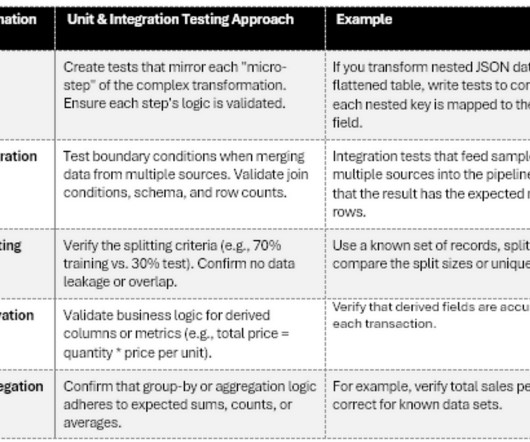
In this post, well see the fundamental procedures, tools, and techniques that data engineers, data scientists, and QA/testing teams use to ensure high-qualitydata as soon as its deployed. First, we look at how unit and integration tests uncover transformation errors at an early stage.
How confident are you in the quality of your data? Across industries and business objectives, high-qualitydata is a must for innovation and data-driven decision-making that keeps you ahead of the competition. Can you trust it for fast, confident decision-making when you need it most?
From AI-generated briefs filled with inaccuracies to scandals that never were , these incidents highlight how easily inadequate data can create flawed results with significant business implications – while simultaneously demonstrating the importance of feeding your AI with trusted, high-qualitydata.
Dataquality monitoring refers to the assessment, measurement, and management of an organization’s data in terms of accuracy, consistency, and reliability. It utilizes various techniques to identify and resolve dataquality issues, ensuring that high-qualitydata is used for business processes and decision-making.
Key Takeaways Dataquality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Data observability continuously monitors datapipelines and alerts you to errors and anomalies.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
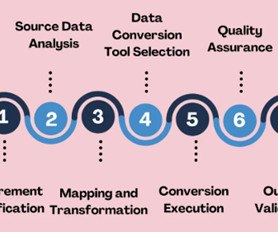
Selecting the strategies and tools for validating data transformations and data conversions in your datapipelines. Introduction Data transformations and data conversions are crucial to ensure that raw data is organized, processed, and ready for useful analysis.
Data cleaning is an essential step to ensure your data is safe from the adage “garbage in, garbage out.” Because effective data cleaning best practices fix and remove incorrect, inaccurate, corrupted, duplicate, or incomplete data in your dataset; data cleaning removes the garbage before it enters your pipelines.
link] Sponsored: IMPACT - Speaker Promo We know high-qualitydata is powerful. Napkin Math is a valuable resource for data platform engineers because it equips them with quick, intuitive calculations for estimating system performance and resource requirements. But can it predict presidential elections?
Data Volumes & Complexity : Describes large-scale or intricate datasets that place heavy demands on storage, processing, and performance. Complex data structures (e.g., Conclusion Effectively managing data transformation challenges requires a proactive, structured approach that evolves alongside your datapipelines.
Organizations need to connect LLMs with their proprietary data and business context to actually create value for their customers and employees. They need robust datapipelines, high-qualitydata, well-guarded privacy, and cost-effective scalability. Data engineers. Who can deliver?
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
The Essential Six Capabilities To set the stage for impactful and trustworthy data products in your organization, you need to invest in six foundational capabilities. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
By adopting a set of best practices inspired by Agile methodologies, DevOps principles, and statistical process control techniques, DataOps helps organizations deliver high-qualitydata insights more efficiently. In some cases, organizations may benefit from adopting elements from both methodologies.
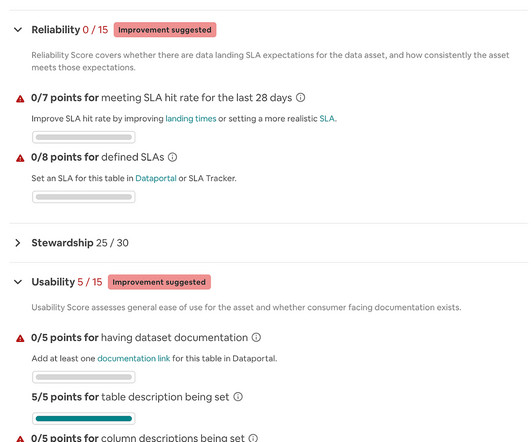
Enable full visibility into the quality of our offline data warehouse and individual data assets. Composing the Score Before diving into the nuances of measuring dataquality, we drove alignment on the vision by defining our DQ Score guiding principles.
New technologies are making it easier for customers to process increasingly large datasets more rapidly. If you happen to be a user of these products, you already know about the results that high-qualitydata produces: more and happier customers, lower costs and higher efficiency, and compliance with complex regulations – to name just a few.
Expanding end-to-end coverage across batch, streaming, and RAG pipelines enables organizations to realize the full potential of their AI initiatives with trusted, high-qualitydata. Data Product Dashboard – Speed is critical to maintaining reliable data products.
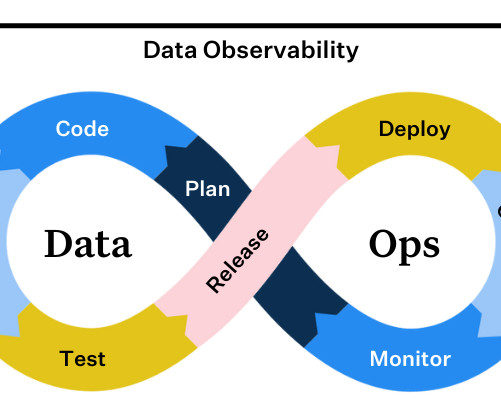
What Are Data Observability Tools? Data observability tools are software solutions that oversee, analyze, and improve the performance of datapipelines. Data observability tools allow teams to detect issues such as missing values, duplicate records, or inconsistent formats early on before they affect downstream processes.
Table of Contents Solve data silos starting at the people-level Keep data governance approachable Oliver Gomes’ data governance best practices Manage and promote the value of high-qualitydata How will Generative AI impact dataquality at Fox? The complexity of a modern datapipeline.
The key differences are that data integrity refers to having complete and consistent data, while data validity refers to correctness and real-world meaning – validity requires integrity but integrity alone does not guarantee validity. What is Data Integrity? How Do You Maintain Data Integrity?
Here are the 7 must-have checks to improve dataquality and ensure reliability for your most critical assets. Dataquality testing is the process of validating that key characteristics of a dataset match what is anticipated prior to its consumption. The data is unique and free from duplicates.
But even though the data landscape is evolving, many enterprise data organizations are still managing dataquality the “old” way: with simple dataquality monitoring. The basics haven’t changed: high-qualitydata is still critical to successful business operations.
As the use of AI becomes more ubiquitous across data organizations and beyond, dataquality rises in importance right alongside it. After all, you can’t have high-quality AI models without high-qualitydata feeding them. Table of Contents What Does an AI DataQuality Analyst Do?
DataOps was first spearheaded by large data-first companies such as Netflix, Uber, and Airbnb that had adopted continuous integration / continuous deployment (CI/CD) principles, even building open source tools to foster their growth for data teams. Monitor : Continuously monitoring and alerting for any anomalies in the data.
On the other hand, “Can the marketing team easily segment the customer data for targeted communications?” usability) would be about extrinsic dataquality. Use of DataQuality Tools Refresh your intrinsic dataquality with data observability 1.
Ensure dataquality Even if there are no errors during the ETL process, you still have to make sure the data meets quality standards. High-qualitydata is crucial for accurate analysis and informed decision-making. Your datapipelines will thank you.
An increasing number of GenAI tools use large language models that automate key data engineering, governance, and master data management tasks. These tools can generate automated outputs including SQL and Python code, synthetic datasets, data visualizations, and predictions – significantly streamlining your datapipeline.
While data engineering and Artificial Intelligence (AI) may seem like distinct fields at first glance, their symbiosis is undeniable. The foundation of any AI system is high-qualitydata. Here lies the critical role of data engineering: preparing and managing data to feed AI models.
They need high-qualitydata in an answer-ready format to address many scenarios with minimal keyboarding. What they are getting from IT and other data sources is, in reality, poor-qualitydata in a format that requires manual customization. A lot of business analytic teams are constantly firefighting.
Data Accuracy vs Data Integrity: Key Similarities Contribution to DataQualityData accuracy and data integrity are both essential components of dataquality. As mentioned earlier, dataquality encompasses a range of attributes, including accuracy, consistency, completeness, and timeliness.
GigaOm GigaOm’s Data Observability Radar Report covers the problem data observability tools look to solve saying, “Data observability is critical for countering, if not eliminating, data downtime, in which the results of analytics or the performance of applications are compromised because of unhealthy, inaccurate data.”
Regardless of the approach you choose, it’s important to keep a scrutinous eye on whether or not your data outputs are matching (or close to) your expectations; often, relying on a few of these measures will do the trick. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies.
A passing test means you’ve improved the trustworthiness of your data. Schedule and automate You’ll need to run schema tests continuously to keep up with your ever-changing data. If your datasets are updated or refreshed daily, you’ll want to run your schema tests on a similar schedule.
By applying rules and checks, data validation testing verifies the data meets predefined standards and business requirements to help prevent dataquality issues and data downtime. From this perspective, the data validation process looks a lot like any other DataOps process.
Gen AI can whip up serviceable code in moments — making it much faster to build and test datapipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. It can show me how it built that chart, which dataset it used, and show me the metadata.”
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content