This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
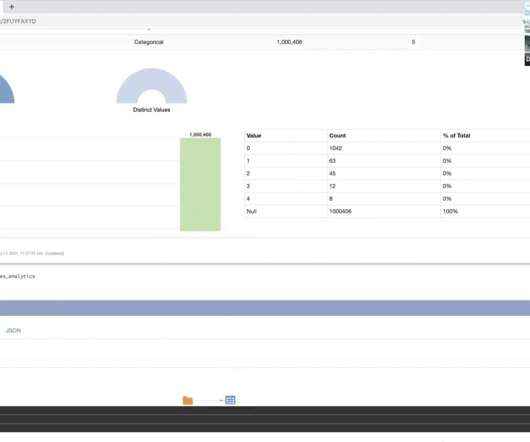
Project demo 3. Building efficient datapipelines with DuckDB 4.1. Use DuckDB to process data, not for multiple users to access data 4.2. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB? Introduction 2. Use DuckDB 4.4.
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where datapipeline design patterns come in. Data Mesh Pattern 8.
Register now and join thousands of fellow developers, data scientists and engineers to learn about the future of AI agents, how to effectively scale pandas, how to create retrieval-augmented generation (RAG) chatbots and much, much more. From Snowflake Native Apps to machine learning, there’s sure to be something fresh for everyone.
Since the previous Python connector API mostly communicated via SQL, it also hindered the ability to manage Snowflake objects natively in Python, restricting datapipeline efficiency and the ability to complete complex tasks. Or, experience these features firsthand at our free Dev Day event on June 6th in the Demo Zone.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
Summary Every part of the business relies on data, yet only a small team has the context and expertise to build and maintain workflows and datapipelines to transform, clean, and integrate it. RudderStack’s smart customer datapipeline is warehouse-first.
Building datapipelines isn’t always straightforward. The gap between the shiny “hello world” examples of demos and the gritty reality of messy data and imperfect formats is sometimes all too […].
How Organizations Can Overcome Data Quality and Availability Challenges Many businesses are shifting toward real-time datapipelines to ensure their AI and analytics strategies are built on reliable information. Enabling AI & ML with Adaptive DataPipelines AI models require ongoing updates to stay relevant.
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable datapipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
Teams can deploy and manage experiments using data available in Snowflake in real time, without having to deal with access to a third-party platform, exfiltrating sensitive conversion data or building complex datapipelines to get the data they need.
Blog An instant demo of data lineage is worth a thousand words Written by Ross Turk on August 10, 2021 They say that a picture is worth a thousand words. If you’ve ever tried to describe how all the jobs in your datapipeline are interrelated using just words, I am sure it wasn’t easy.
For those using a robust analytics database, such as the Snowflake® Data Cloud , adding the power of a data engineering platform can help maximize the value you’re getting out of that database. Magpie Fills in the Gaps for Better Data Engineering And we’re not talking about just ETL (extract, transform, load). Magpie can help.
Monte Carlo and Databricks double-down on their partnership, helping organizations build trusted AI applications by expanding visibility into the datapipelines that fuel the Databricks Data Intelligence Platform. This comprehensive visibility helps teams identify and resolve data issues before they cascade into AI failures.
When implemented effectively, smart datapipelines seamlessly integrate data from diverse sources, enabling swift analysis and actionable insights. They empower data analysts and business users alike by providing critical information while protecting sensitive production systems. What is a Smart DataPipeline?
With their extended partnership, data + AI observability leader and the Data AI Cloud bring reliability to structured and unstructured datapipelines in Snowflake Cortex AI. Read on for more details and find out how were thinking about unstructured data observability for AI. Why observability for unstructured data?
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
A well-executed datapipeline can make or break your company’s ability to leverage real-time insights and stay competitive. Thriving in today’s world requires building modern datapipelines that make moving data and extracting valuable insights quick and simple. What is a DataPipeline?
And now, from the mind of Barr Moses, comes the historic next children’s literary classic: Mastering Data Quality And Your ABCs. After all, in the age of virtual reality, generative AI, and cyber trucks, why shouldn’t children also learn how to write their first dbt test or spin up their first data observability solution? .
Tools like Python’s requests library or ETL/ELT tools can facilitate data enrichment by automating the retrieval and merging of external data. Read More: Discover how to build a datapipeline in 6 steps Data Integration Data integration involves combining data from different sources into a single, unified view.
How to analyze and resolve datapipeline incidents in Databand Niv Sluzki 2022-09-09 13:00:12 A datapipeline failure can cripple your downstream data flows. Whether it failed to start or quit unexpectedly, you need to know immediately if there is a pipeline incident.
It’s important to be able to talk about them, but in reality, no one has been able to deploy them and no one has had any success outside of a demo. We’re going to see an explosion in the total number of pipelines but with much smaller data volumes.” But the more pipelines expand, the more difficult data quality becomes.
” —David Webb, Data Architect at Travelpass Build modern datapipelines with Snowflake Python APIs Snowflake’s latest suite of Python APIs (GA soon) simplifies the datapipeline development process with Python.
How to create datapipeline and data quality SLA alerts in Databand Helen Soloveichik 2022-09-20 01:49:30 Data engineers often get inundated by alerts from data issues. Databand helps fix this problem by breaking through noisy alerts with focused alerting and routing when a datapipeline and quality issues occur.
Thats where data observability comes in. Tools like Monte Carlo monitor your datapipelines and flag issueslike broken jobs, missing records, or sudden spikes before they mess up your reports. Thats how you move from just working with data to actually making confident, smart decisions based on it.
Striim customers often utilize a single streaming source for delivery into Kafka, Cloud Data Warehouses, and cloud storage, simultaneously and in real-time. Building streaming datapipelines shouldnt require custom coding Building datapipelines and working with streaming data should not require custom coding.
Seamless Integration for Instant Insight: To maximize the benefits of real-time analytics, organizations need platforms that can seamlessly integrate AI models into their datapipelines. Striim provides the architecture to apply trained models to incoming data as it flows through the system.
Current open-source frameworks like YAML-based Soda Core, Python-based Great Expectations, and dbt SQL are frameworks to help speed up the creation of data quality tests. They are all in the realm of software, domain-specific language to help you write data quality tests. Download Now Request Demo
This approach delivers meaningful insights the moment data arrives, supported by continuous learning algorithms that adapt models dynamically to evolving conditions. By integrating AI/ML models directly into streaming datapipelines, organizations can detect anomalies, predict cascading impacts, and execute real-time interventions.
Going into the DataPipeline Automation Summit 2023, we were thrilled to connect with our customers and partners and share the innovations we’ve been working on at Ascend. The summit explored the future of datapipeline automation and the endless possibilities it presents.
kyutai released Moshi — Moshi is a "voice-enabled AI" The team as kyutai developed the model with an audio interface-first with an audio language model, which make the conversation with the AI more real (demo at 5:00 min) as it can interrupt you or kinda "think" (meaning for predict the next audio segment) while it speaks.
With this setting, the connector initially reads all the data from selected objects and then switches to incremental loading, ensuring ongoing updates are seamlessly captured. This flexibility makes it easy to keep your datapipeline running efficiently. Ready to power your business with real-time data?
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Bi-Directional Pipelines: Combining the Salesforce CDC Reader with Striims Snowflake CDC Reader creates the fastest bi-directional pipelines, keeping both Salesforce and Snowflake in sync. Unified Platform: Striim integrates Salesforce with other databases, providing a unified platform for handling all your Salesforce datapipelines.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Go to dataengineeringpodcast.com/atlan today to learn more about how Atlan’s active metadata platform is helping pioneering data teams like Postman, Plaid, WeWork & Unilever achieve extraordinary things with metadata and escape the chaos. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Their SDKs make event streaming from any app or website easy, and their extensive library of integrations enable you to automatically send data to hundreds of downstream tools. Sign up free at dataengineeringpodcast.com/rudder Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
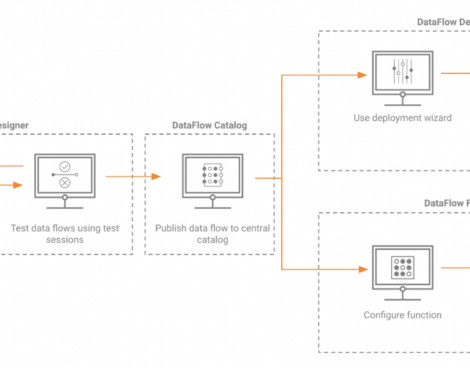
Data leaders will be able to simplify and accelerate the development and deployment of datapipelines, saving time and money by enabling true self service. It is no secret that data leaders are under immense pressure. For more information or to see a demo, go to the DataFlow Product page.
Its important to be able to talk about them, no one has had any success outside of a demo. Pipelines are expandingbut quality coverage isnt(Tomasz) At a dinner with a bunch of heads of AI, I asked how many people were satisfied with the quality of the outputs, and no one raised their hands.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
AI-assisted data modeling on shared data workloads Data sharing is critical to inform decision making across the organization. Snowflake eliminates the data sharing complexities of traditional datapipelines —making data secure, governed, and easily ready to query.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content