This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
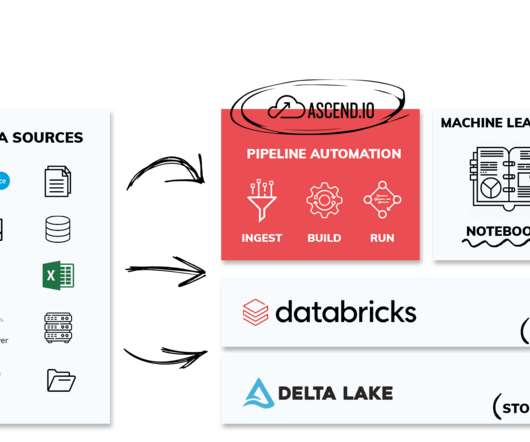
Register now Home Insights Data platform Article How To Use Airbyte, dbt-teradata, Dagster, and Teradata Vantage™ for Seamless Data Integration Build and orchestrate a datapipeline in Teradata Vantage using Airbyte, Dagster, and dbt. customer_demographics.sql`: Model for transforming customer demographic data.
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Next, look for automatic metadata scanning. This basically means the tool updates itself by pulling in changes to data structures from your systems. It has real-time metadata updates, deep data lineage, and its flexible if you want to customize or extend it for your teams specific needs.
The result was Apache Iceberg, a modern table format built to handle the scale, performance, and flexibility demands of today’s cloud-native data architectures. Metadata Layer 3. Data Layer What are the main use cases for Apache Iceberg? It maintains references to the latest metadata file for each table.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Blog An instant demo of data lineage is worth a thousand words Written by Ross Turk on August 10, 2021 They say that a picture is worth a thousand words. If you’ve ever tried to describe how all the jobs in your datapipeline are interrelated using just words, I am sure it wasn’t easy.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
kyutai released Moshi — Moshi is a "voice-enabled AI" The team as kyutai developed the model with an audio interface-first with an audio language model, which make the conversation with the AI more real (demo at 5:00 min) as it can interrupt you or kinda "think" (meaning for predict the next audio segment) while it speaks.
The result is a broken, reactive process that fails to prevent data quality issues at their source. Gartners solution emphasizes adopting augmented data quality technologies that use automation, AI/ML-driven insights, and metadata-driven workflows to improve efficiency. Download Now Request Demo
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. Visit dataengineeringpodcast.com/datafold today to book a demo with Datafold.
Summary Data lineage is the common thread that ties together all of your datapipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Summary Building clean datasets with reliable and reproducible ingestion pipelines is completely useless if it’s not possible to find them and understand their provenance. The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform.
This mission culminates in the esteemed recognition of honorable mention in Gartner’s 2023 Magic Quadrant for Data Integration, showcasing commitment to excellence and industry leadership in the data-driven era. Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines.
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
Atlan is the metadata hub for your data ecosystem. Instead of locking all of that information into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Go to dataengineeringpodcast.com/atlan today to learn more about how you can take advantage of active metadata and escape the chaos.
This mission culminates in the esteemed recognition of honorable mention in Gartner’s 2023 Magic Quadrant for Data Integration, showcasing commitment to excellence and industry leadership in the data-driven era. Data engineering excellence Modern offers robust solutions for building, managing, and operationalizing datapipelines.
Reimagine Data Governance with Sentinel and Sherlock: Striims AI Agents Striim 5.0 introduces Sentinel and Sherlock, which redefine real-time data governance by seamlessly integrating advanced AI capabilities into your datapipelines. Ready to take your data governance efforts to the next level?
The move to productize data also requires a way to package data products so they are easily and uniformly discoverable and consumed. Data products must be properly designed and organized to be reused across the organization. Data catalogs or data marketplaces can be used to enhance the value of your data mesh strategy.
This initiative is more than just an upgrade; it’s a reimagining of what a Data Automation Platform can be: dynamic, extensible, and highly intelligent. A unified platform that combines a powerful metadata core, an extensible plugin architecture, DataAware automation, and multiple AI Assistants. Let’s dive in!
Leveraging TensorFlow Transform for scaling datapipelines for production environments Photo by Suzanne D. Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. I have used Colab for this demo, as it is much easier (and faster) to configure the environment.
I’m Ross from Datakin I’d like to show you a new approach to keeping your pipelines running smoothly. Datakin observes your jobs as they run, collecting metadata that helps you understand how data flows through your ecosystem. Blog Datakin in 104 seconds Written by Ross Turk on Sep 13, 2021 Hi!
We hope the real-time demonstrations of Ascend automating datapipelines were a real treat—a long with the special edition T-Shirt designed specifically for the show (picture of our founder and CEO rocking the t-shirt below). Instead, it is a Sankey diagram driven by the same dynamic metadata that runs the Ascend control plane.
While it shares similarities with software versioning, data versioning has unique characteristics specific to your data management needs. Maintaining metadata about each version. By implementing data versioning, you can create a systematic approach to managing the evolution of your data.
The learning goes back to the fundamentals of pipeline design principles. Regularly review if pipelines are still required. Minimize the data used in pipelines, aka do incremental datapipeline design. Optimize pipeline schedules. Filter data effectively to make sure the query uses partition pruning.
These include internal data lakes, apps (1st or 3rd party), web SDK, internal or 3rd-party databases, and even spreadsheets generated within the marketing department. Without lineage or governance metadata, the quality of this data is anyone’s guess. New data is added to the catalog automatically upon ingestion.
The data engineering world is full of tips and tricks on how to handle specific patterns that recur with every datapipeline. In general, the root of the orphaned data problem lies in the interim storage of data between the individual processing steps that make up a datapipeline.
We built Magpie with integrated security and data governance features including data lineage, detailed activity tracking, object-level access control, metadata management, scheduling and dependency management, comprehensive reporting, and DevOps support. The time to identify more insights out of huge sets of data.
Slow running datapipelines cost data teams time, money, and goodwill. They utilize excess compute, cause data quality issues, and create a poor user experience for data consumers that must wait in exasperation for data to return, dashboards to load, and AI models to update.
With the monolithic architectures most organizations have today, business users are stuck, constantly waiting for new datapipelines to be built or amended based on their requests. Data engineers aren’t huge fans of this paradigm either. Anyone can query the metadata any time anywhere to get the information they need.
Whether your organization’s focus is improving the customer experience, automating operations, mitigating risk, or accelerating growth and profitability, every initiative relies on data that is trusted to be accurate, consistent, and contextualized.
Traditional approaches rely upon cascading batch-oriented datapipelines, meaning data takes hours or even days to flow through the enterprise. As a result, data made available is stale and of low fidelity. We aim to coherently feed these diverse inputs into a model with low latency and without a complex architecture.
Implementing a Proactive Approach: Best Practices To combat these hidden threats in your data warehouse, being proactive is essential. Implement these best practices to enhance your data integrity: Clear Documentation and Metadata Management : Ensure all your data assets and transformations are well-documented.
Please send your talk proposal today, and let's collaborate to make this the most exciting, insightful, and interactive Data Eng & AI conference yet! LinkedIn write about Hoptimator for auto generated Flink pipeline with multiple stages of systems. Please watch out for this space for the conference registration page soon!!!
In real-time ML, the freshness of the features, the serving latency, and the uptime and availability of the datapipeline and model matter. Generating Features for Real-Time Anomaly Detection Now download the anomaly detection dataset to the data / directory. 0 0 Ok, we have the imported data.
When a change is detected, the data is ingested into a data lake hosted on Amazon S3. There, the data is converted, tagged with metadata, cleaned, and de-duplicated in preparation for queries. They demoed but quickly eliminated Snowflake.
It was recommended to pause the crawlers and enable glue metadata registry on the Kinesis level. We proposed a few designed changes, one of the most suitable method is to use Athena and QuickSight for data analytics and data visualization (See appendix for dashboard that WeCloudData team created).
It was recommended to pause the crawlers and enable glue metadata registry on the Kinesis level. We proposed a few designed changes, one of the most suitable method is to use Athena and QuickSight for data analytics and data visualization (See appendix for dashboard that WeCloudData team created).
Gen AI can whip up serviceable code in moments — making it much faster to build and test datapipelines. Today’s LLMs can already process enormous amounts of unstructured data, automating much of the monotonous work of data science. It can show me how it built that chart, which dataset it used, and show me the metadata.”
Source: The Data Team’s Guide to the Databricks Lakehouse Platform Integrating with Apache Spark and other analytics engines, Delta Lake supports both batch and stream data processing. Besides that, it’s fully compatible with various data ingestion and ETL tools.
Prevention: Finally, data observability also provides mechanisms to prevent data issues from happening in the first place, like placing circuit breaking in pipelines and creating visibility around the impact code changes would make on data, among other proactive measures of preventing bad data from entering your pipelines in the first place.
In the case of data observability, however, a single pane of glass is integral to how efficient and effective your data team can be in its data reliability workflows. It’s great to know data moved from point A to point B, but your integration points will paint the full story of what happened to it along the way.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content