

Data Engineering Best Practices - #2. Metadata & Logging
Start Data Engineering
FEBRUARY 22, 2024
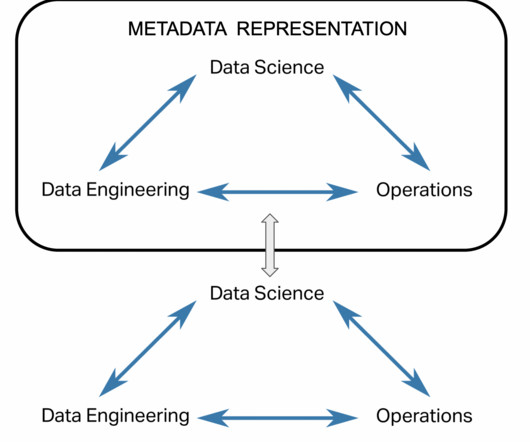
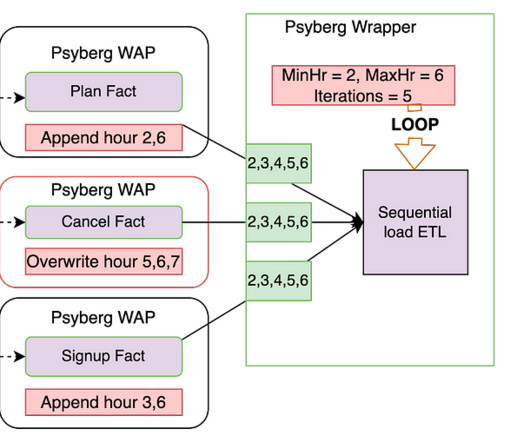
Data Pipeline Logging Best Practices 3.1. Metadata: Information about pipeline runs, & data flowing through your pipeline 3.2. Introduction 2. Setup & Logging architecture 3. Obtain visibility into the code’s execution sequence using text logs 3.3. Monitoring UI & Traceability 3.5.















































Let's personalize your content