This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Start trusting your data with Monte Carlo today! What are the capabilities that a centralized and holistic view of a platform’s metadata can enable?
The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle. Having completed the Data Collection step in the previous blog, ECC’s next step in the data lifecycle is Data Enrichment.
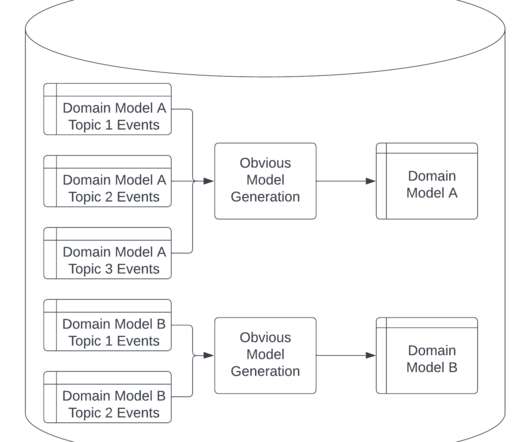
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
link] Netflix: Netflix’s Distributed Counter Abstraction Netflix writes about scalable Distributed Counter abstractions for accurately counting events across its global services with millisecond latency. Due to the platform's diverse user base and workloads, Canva faced challenges maintaining visibility into Snowflake usage and costs.
Today’s post follows the same philosophy: fitting local and cloud pieces together to build a datapipeline. And, when it comes to data engineering solutions, it’s no different: They have databases, ETL tools, streaming platforms, and so on — a set of tools that makes our life easier (as long as you pay for them). not sponsored.
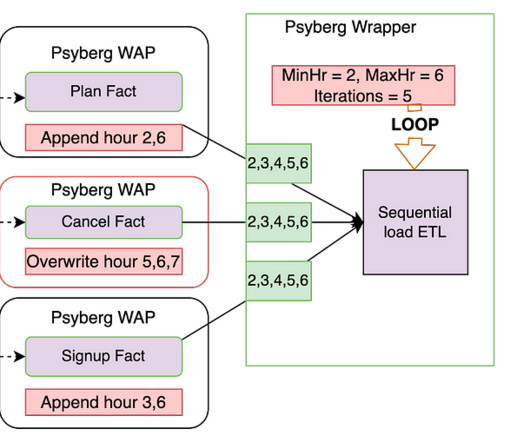
We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Furthermore, we’ll delve into the inner workings of Psyberg, its unique features, and how it integrates into our datapipelining workflows. It also becomes inefficient as the data scale increases.
In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service datapipeline development. Key requirements for building datapipelines Every datapipeline starts with a business requirement.
The challenges around memory, data size, and runtime are exciting to read. Sampling is an obvious strategy for data size, but the layered approach and dynamic inclusion of dependencies are some key techniques I learned with the case study. Passes include app-brain-date networking, birds of a feature, post-event parties, etc.
Kafka is designed for streaming events, but Fluss is designed for streaming analytics. Architecture Difference The first difference is the Data Model. It excels in event-driven architectures and datapipelines. It maintains metadata, manages tablet allocation, lists nodes, and handles permissions.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
In every step,we do not just read, transform and write data, we are also doing that with the metadata. Last part, it was added the data security and privacy part. Every data governance policy about this topic must be read by a code to act in your data platform (access management, masking, etc.)
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. We want interoperability for any data stored versus we have to think how to store the data in a specific node to optimize the processing. ” He/She is managing triggers, he/she needs to check conditions (event type ?
Now, let’s explore the state of our pipelines after incorporating Psyberg. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep datapipeline. The session metadata table can then be read to determine the pipeline input.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. What are the most interesting, innovative, or unexpected ways that you have seen column-aware data modeling used?
Try Astro Free → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. Let me know in the comments.
At our recent Snowday event, we announced a wave of Snowflake product innovations for easier application development, new AI and LLM capabilities, better cost management and more. If you missed the event or need a refresh of what was presented, watch any Snowday session on demand. Learn more about Iceberg Tables here. Learn more here.
Developing event-driven pipelines is going to be a lot easier - Meet Functions! Memphis Logo]([link] Developing event-driven pipelines is going to be a lot easier - Meet Functions! Developing event-driven pipelines is going to be a lot easier - Meet Functions!
I won’t bore you with the importance of data quality in the blog. Instead, Let’s examine the current datapipeline architecture and ask why data quality is expensive. Instead of looking at the implementation of the data quality frameworks, Let's examine the architectural patterns of the datapipeline.
You won't want to miss this live event on April 23rd! This article highlights their growing complexity, from multimodal interaction to enterprise adoption, underscoring the data and infrastructure challenges beneath the surface. Introducing Apache Airflow® 3.0 Be among the first to see Airflow 3.0
Application Logic: Application logic refers to the type of data processing, and can be anything from analytical or operational systems to datapipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs.
Summary Data lineage is the common thread that ties together all of your datapipelines, workflows, and systems. In order to get a holistic understanding of your data quality, where errors are occurring, or how a report was constructed you need to track the lineage of the data from beginning to end.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA.
Summary Building clean datasets with reliable and reproducible ingestion pipelines is completely useless if it’s not possible to find them and understand their provenance. The solution to discoverability and tracking of data lineage is to incorporate a metadata repository into your data platform.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. So our solution was to start using an intentional contract: Events. What are Events? Events are facts about what happened within your service.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
This week’s episode is also sponsored by Datacoral, an AWS-native, serverless, data infrastructure that installs in your VPC. Raghu Murthy, founder and CEO of Datacoral built data infrastructures at Yahoo! For someone who wants to get started with Dagster can you describe a typical workflow for writing a datapipeline?
Stateless Data Processing : As the name suggests, one should use this pattern in scenarios where the columns in the target table solely depend on the content of the incoming events, irrespective of their order of occurrence. A missed event in such a scenario would result in incorrect analysis due to a wrong derived state.
Modern Data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days. RudderStack’s smart customer datapipeline is warehouse-first.
Summary At the core of every datapipeline is an workflow manager (or several). Deploying, managing, and scaling that orchestration can consume a large fraction of a data team’s energy so it is important to pick something that provides the power and flexibility that you need.
RudderStack’s smart customer datapipeline is warehouse-first. It builds your customer data warehouse and your identity graph on your data warehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. You can observe your pipelines with built in metadata search and column level lineage.
This leads us to event streaming microservices patterns. Now that the profile change event is published, it can be received by the quote service. Now that the profile change event is published, it can be received by the quote service. In fact, schemas are more than just a contract between two event streaming microservices.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder.
Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code. Monitoring data quality, tracing incidents, and testing changes can be daunting and often takes hours to days or even weeks. What is the workflow for someone getting Sifflet integrated into their data stack?
The terms ‘data orchestration’ and ‘datapipeline orchestration’ are often used interchangeably, yet they diverge significantly in function and scope. Data orchestration refers to a wide collection of methods and tools that coordinate any and all types of data-related computing tasks.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or data lake.
Today’s episode is Sponsored by Prophecy.io – the low-code data engineering platform for the cloud. Prophecy provides an easy-to-use visual interface to design & deploy datapipelines on Apache Spark & Apache Airflow. You can observe your pipelines with built in metadata search and column level lineage.
Rather than manually defining all of the mappings ahead of time, we can rely on the power of graph databases and some strategic metadata to allow connections to occur as the data becomes available. If you are struggling to maintain a tangle of datapipelines then you might find some new ideas for reducing your workload.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content