This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rise of the datageneralist: smaller teams, bigger impact — You don't need to convince me. With synthetic data you can then publicly seek for help among the world's data scientists. A new datapipelines observability solution enters the game. As an echo of last bullet point.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a data engineer? It can be applicable for multiple roles such as data analyst, data architect, data engineer etc.
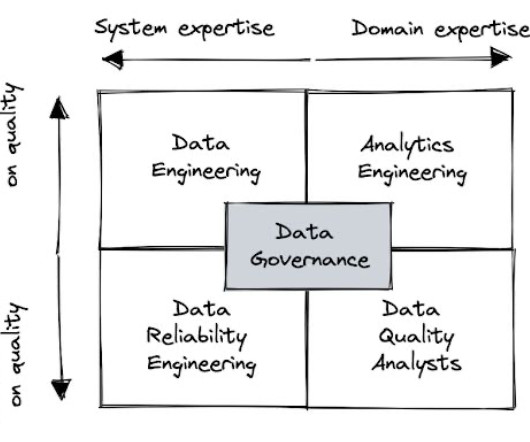
Specialists or generalists? We examine which team structures are the best suited for efficiently improving data quality. Sure, data quality is everyones’ problem. Mercari uses a data reliability engineering team structure. Engineer or analyst? Image courtesy of Shane Murray. But who owns the solution?
Roughly, the operations in a datapipeline consist of the following phases: Ingestion — this involves gathering in the needed data. Processing — this involves processing the data to get the end results you want. Processing — this involves processing the data to get the end results you want.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? They are also accountable for communicating data trends. These are as follows: 1.
Additionally, they create and test the systems necessary to gather and process data for predictive modelling. Data engineers play three important roles: Generalist: With a key focus, data engineers often serve in small teams to complete end-to-end data collection, intake, and processing.
Let us take a look at the top technical skills that are required by a data engineer first: A. Technical Data Engineer Skills 1.Python Python is ubiquitous, which you can use in the backends, streamline data processing, learn how to build effective data architectures, and maintain large data systems.
Themes I was drawn to the articles that speak to a theme in the data world that I am passionate about: how datapipelines and data team practices are evolving to be more like traditional product development. 7 Be Intentional About the Batching Model in Your DataPipelines Different batching models.
Depending on the industry, the data analyst could go by a different title (e.g. Regardless of title, the data analyst is a generalist who can fit into many roles and teams to help others make better data-driven decisions. What do data analysts do? Integrating external or new datasets into existing datapipelines.
” Self-serve data infrastructure as a platform The principle of creating a self-serve data infrastructure is to provide tools and user-friendly interfaces so that generalist developers (and non-technical people) can quickly get access to data or develop analytical data products speedily and seamlessly.
What is Data Engineering? Data engineering is all about building, designing, and optimizing systems for acquiring, storing, accessing, and analyzing data at scale. Data engineering builds datapipelines for core professionals like data scientists, consumers, and data-centric applications.
In that case, Data Science is a comparatively broader and generalist role than Machine Learning Engineer, which is quite a specialist role and, therefore, sees a lot more vacancies, according to Indeed. As for the job prospects, both roles are emerging and attract a lot of opportunities, thereby creating an overwhelmingly high demand.
Certification Provider : Cloudera Duration : 120 minutes Cost : $330 Importance : With this certification, you can aim for better career opportunities and prove your proficiency in using Cloudera products for data analysis and management. Ideal if you are looking for big data certification for beginners.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content