This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With these points in mind, I argue that the biggest hurdle to the widespread adoption of these advanced techniques in the healthcare industry is not intrinsic to the industry itself, or in any way related to its practitioners or patients, but simply the current lack of high-qualitydatapipelines.
Data ingestion When we think about the flow of data in a pipeline, data ingestion is where the data first enters our platform. There are two primary types of rawdata. And data orchestration tools are generally easy to stand-up for initial use-cases. Missed Nishith’s 5 considerations?
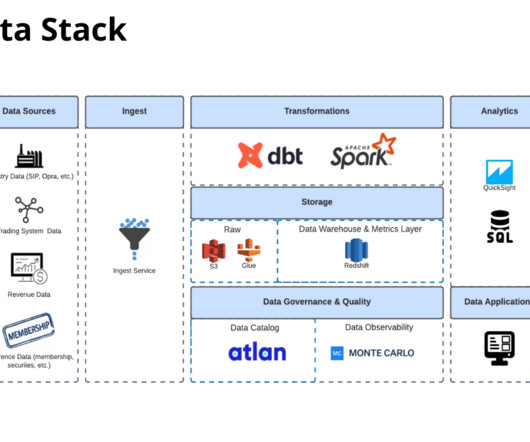
The Ten Standard Tools To Develop DataPipelines In Microsoft Azure. While working in Azure with our customers, we have noticed several standard Azure tools people use to develop datapipelines and ETL or ELT processes. We counted ten ‘standard’ ways to transform and set up batch datapipelines in Microsoft Azure.
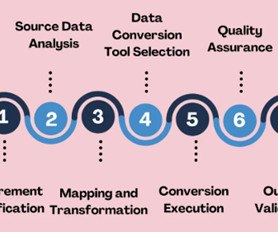
Selecting the strategies and tools for validating data transformations and data conversions in your datapipelines. Introduction Data transformations and data conversions are crucial to ensure that rawdata is organized, processed, and ready for useful analysis.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances dataquality, governance, and automation, transforming rawdata into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Running these automated tests as part of your DataOps and Data Observability strategy allows for early detection of discrepancies or errors. There are multiple locations where problems can happen in a data and analytic system. What is Data in Use?
AI models are only as good as the data they consume, making continuous data readiness crucial. Here are the key processes that need to be in place to guarantee consistently high-qualitydata for AI models: Data Availability: Establish a process to regularly check on data availability. Actionable tip?
An observability platform is a comprehensive solution that allows data engineers to monitor, analyze, and optimize their datapipelines. By providing a holistic view of the datapipeline, observability platforms help teams rapidly identify and address issues or bottlenecks.
while overlooking or failing to understand what it really takes to make their tools — and, ultimately, their data initiatives — successful. When it comes to driving impact with your data, you first need to understand and manage that data’squality. learn when and why data may be down.
As the data analyst or engineer responsible for managing this data and making it usable, accessible, and trustworthy, rarely a day goes by without having to field some request from your stakeholders. But what happens when the data is wrong? In our opinion, dataquality frequently gets a bad rep.
When it comes to data engineering, quality issues are a fact of life. Like all software and data applications, ETL/ELT systems are prone to failure from time-to-time. Among other factors, datapipelines are reliable if: The data is current, accurate, and complete. The data is unique and free from duplicates.
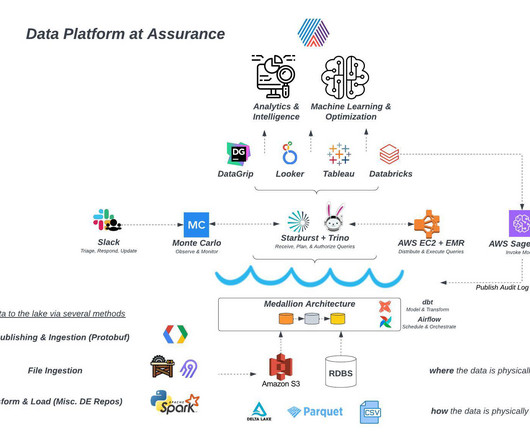
Business data assets at Assurance are loaded into the company’s lakehouse architecture through various methods, then stored in several data stores. The data team then uses tools like dbt and Airflow to refine, model and transform rawdata into usable, query-able assets through Trino and Starburst.
Run the test again to validate that the initial problem is solved and that your data meets your quality and accuracy standards. Schedule and automate Just like schema tests, custom data tests in dbt are typically not run just once but are incorporated into your regular datapipeline to ensure ongoing dataquality.
In this model, data objects are treated like “cattle, not pets,” meaning they are cared for interchangeably and not individually managed, which is ideal for high-throughput, scalable datapipelines. The Hub Data Journey provides the rawdata and adds value through a ‘contract.
A 2023 Salesforce study revealed that 80% of business leaders consider data essential for decision-making. However, a Seagate report found that 68% of available enterprise data goes unleveraged, signaling significant untapped potential for operational analytics to transform rawdata into actionable insights.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content