This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Handling and processing the streaming data is the hardest work for Data Analysis. We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined DataPipeline appeared first on Analytics Vidhya.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Can you describe your experiences with Kafka?
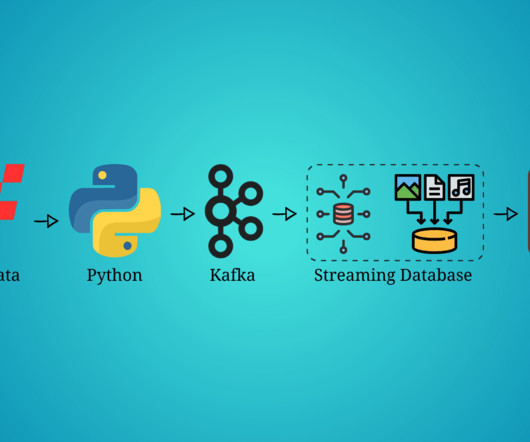
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
It addresses many of Kafka's challenges in analytical infrastructure. The combination of Kafka and Flink is not a perfect fit for real-time analytics; the integration of Kafka and Lakehouse is very shallow. How do you compare Fluss with Apache Kafka? Fluss and Kafka differ fundamentally in design principles.
It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process. That’s where datapipeline tools come in. This blog is all about that—specifically, the top 10 datapipeline tools that data engineers worldwide rely on.
Datapipelines are a significant part of the big data domain, and every professional working or willing to work in this field must have extensive knowledge of them. Table of Contents What is a DataPipeline? The Importance of a DataPipeline What is an ETL DataPipeline?
Whether it’s customer transactions, IoT sensor readings, or just an endless stream of social media hot takes, you need a reliable way to get that data from point A to point B while doing something clever with it along the way. That’s where datapipeline design patterns come in. Data Mesh Pattern 8.
Snowflake enables organizations to be data-driven by offering an expansive set of features for creating performant, scalable, and reliable datapipelines that feed dashboards, machine learning models, and applications. But before data can be transformed and served or shared, it must be ingested from source systems.
For example, developers can provision Kafka topics, Espresso tables, Venice stores and more via Nuage , our internal cloud-like infra management platform. Datapipelines power foundational parts of LinkedIn's infrastructure, including replication between data centers.
Today, Kafka is used by thousands of companies, including over 80% of the Fortune 100. Kafka's popularity is skyrocketing, and for good reason—it helps organizations manage real-time data streams and build scalable data architectures. As a result, there's a growing demand for highly skilled professionals in Kafka.
Looking for the ultimate guide on mastering Apache Kafka in 2024? The ultimate hands-on learning guide with secrets on how you can learn Kafka by doing. Discover the key resources to help you master the art of real-time data streaming and building robust datapipelines with Apache Kafka. Here it is!
Rudderstack]([link] RudderStack provides all your customer datapipelines in one platform. You can collect, transform, and route data across your entire stack with its event streaming, ETL, and reverse ETL pipelines. Rudderstack]([link] RudderStack provides all your customer datapipelines in one platform.
Explore the full potential of AWS Kafka with this ultimate guide. Elevate your data processing skills with Amazon Managed Streaming for Apache Kafka, making real-time data streaming a breeze. According to IDC , the worldwide streaming market for event-streaming software, such as Kafka, is likely to reach $5.3
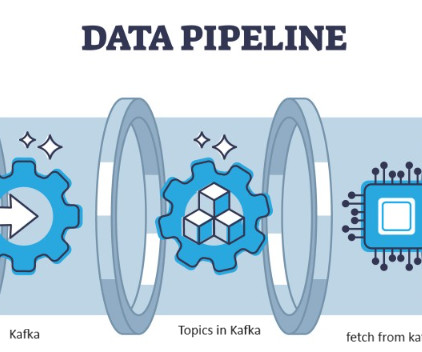
Your search for Apache Kafka interview questions ends right here! Let us now dive directly into the Apache Kafka interview questions and answers and help you get started with your Big Data interview preparation! What are topics in Apache Kafka? Kafka stores data in topics that are split into partitions.
If you’re looking for everything a beginner needs to know about using Apache Kafka for real-time data streaming, you’ve come to the right place. This blog post explores the basics about Apache Kafka and its uses, the benefits of utilizing real-time data streaming, and how to set up your datapipeline.
Kafka, while not in the top 5 most in demand skills, was still the most requested buffer technology requested which makes it worthwhile to include it. I'll use Python and Spark because they are the top 2 requested skills in Toronto. The remaining tech (stages 3, 4, 7 and 8) are all AWS technologies.
Taming the torrent of data pouring into your systems can be daunting. Kafka Topics are your trusty companions. Learn how Kafka Topics simplify the complex world of big data processing in this comprehensive blog. More than 80% of all Fortune 100 companies trust, and use Kafka. Table of Contents What is Kafka Topic?
In our previous blog, Dima Kalashnikov explained how we configure our Internal services pipeline in the Analytics Platform. In this post, we will explain how our team automates the creation of new datapipeline deployments. Now, we can have a pipeline ready in minutes.
Confluent’s new Stream Designer is the industry’s first visual interface for rapidly building, testing, and deploying streaming datapipelines natively on Apache Kafka.
Building reliable datapipelines is a complex and costly undertaking with many layered requirements. In order to reduce the amount of time and effort required to build pipelines that power critical insights Manish Jethani co-founded Hevo Data. Data stacks are becoming more and more complex.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
Following part 1 and part 2 of the Spring for Apache Kafka Deep Dive blog series, here in part 3 we will discuss another project from the Spring team: Spring Cloud Data Flow , which focuses on enabling developers to easily develop, deploy, and orchestrate event streaming pipelines based on Apache Kafka ®.
This datapipeline is a great example of a use case for Apache Kafka ®. The data processing pipeline characterizes these objects, deriving key parameters such as brightness, color, ellipticity, and coordinate location, and broadcasts this information in alert packets. The case for Apache Kafka.
Summary How much time do you spend maintaining your datapipeline? Contact Info LinkedIn Parting Question From your perspective, what is the biggest gap in the tooling or technology for data management today? How much end user value does that provide? How much end user value does that provide? Links Datacoral Yahoo!
In the same way that application performance monitoring ensures reliable software and keeps application downtime at bay, Monte Carlo solves the costly problem of broken datapipelines. Get started for free at dataengineeringpodcast.com/hightouch. Can you describe what Decodable is and the story behind it?
The ksqlDB project was created to address this state of affairs by building a unified layer on top of the Kafka ecosystem for stream processing. Developers can work with the SQL constructs that they are familiar with while automatically getting the durability and reliability that Kafka offers. How is ksqlDB architected?
In this third installment of the Universal Data Distribution blog series, we will take a closer look at how CDF-PC’s new Inbound Connections feature enables universal application connectivity and allows you to build hybrid datapipelines that span the edge, your data center, and one or more public clouds.
Project Idea : Use the StatsBomb Open Data to study player and team performances. Build a datapipeline to ingest player and match data, clean it for inconsistencies, and transform it for analysis. Load raw data into Google Cloud Storage, preprocess it using Mage VM, and store results in BigQuery.
The Kafka Summit Program Committee recently published the schedule for the San Francisco event, and there’s quite a bit to look forward to. I remember two to three years back, I spent all my time listening to talks about various ETL architectures in the Pipelines track. Interests evolve over time too. What’s the Time?…and
Unlocking Kafka's potential: tackling tail latency with eBPF. Forward thinking Dataviz is hierarchical — Malloy, once again, provides an excellent article about a new way to see data visualisations. Coding datapipelines is faster than renting connector catalogs — This is something I've always believed.
Data engineers manage that massive amount of data using various data engineering tools, frameworks, and technologies. Data engineering tools are specialized applications that make building datapipelines and designing algorithms easier and more efficient.
Spark Streaming Vs Kafka Stream Now that we have understood high level what these tools mean, it’s obvious to have curiosity around differences between both the tools. Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing.
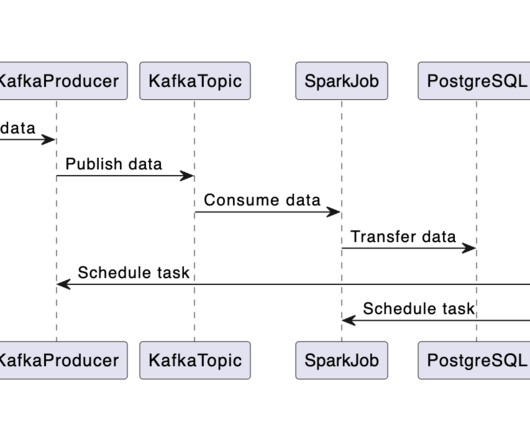
The first phase focuses on building a datapipeline. This involves getting data from an API and storing it in a PostgreSQL database. Overview Let’s break down the datapipeline process step-by-step: Data Streaming: Initially, data is streamed from the API into a Kafka topic.
Data Collection The first step is to collect real-time data (purchase_data) from various sources, such as sensors, IoT devices, and web applications, using data collectors or agents. These collectors send the data to a central location, typically a message broker like Kafka.
The data generated was as varied as the departments relying on these applications. Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly datapipeline maintenance. They chose the Precisely Data Integrity Suites Data Integration Service.
Table of Contents What is Data Ingestion in a Data Engineering Project? Why do you need a Data Ingestion Layer in a Data Engineering Project? Types of Data Ingestion How does Data Ingestion Work in the DataPipeline? Data Ingestion vs. ETL - How are they different?
On-premise and cloud working together to deliver a data product Photo by Toro Tseleng on Unsplash Developing a datapipeline is somewhat similar to playing with lego, you mentalize what needs to be achieved (the data requirements), choose the pieces (software, tools, platforms), and fit them together.
In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service datapipeline development. Key requirements for building datapipelines Every datapipeline starts with a business requirement.
Kafka can continue the list of brand names that became generic terms for the entire type of technology. Similar to Google in web browsing and Photoshop in image processing, it became a gold standard in data streaming, preferred by 70 percent of Fortune 500 companies. What is Kafka? What Kafka is used for.
Trains are an excellent source of streaming data—their movements around the network are an unbounded series of events. Using this data, Apache Kafka ® and Confluent Platform can provide the foundations for both event-driven applications as well as an analytical platform. As with any real system, the data has “character.”
This indicates that more businesses will adopt the tools and methodologies useful in big data analytics, including implementing the ETL pipeline. Data engineers are in charge of developing data models , constructing datapipelines, and monitoring ETL (extract, transform, load).
Learn more about how you can benefit from a well-supported data management platform and ecosystem of products, services and support by visiting the IBM and Cloudera partnership page. The post IBM Technology Chooses Cloudera as its Preferred Partner for Addressing Real Time Data Movement Using Kafka appeared first on Cloudera Blog.
A datapipeline is a method for getting data from one system to another, whether for analytics purposes or for storage. Learning the elements that make up this proven architecture […].
Today, every company is a data company. There are many different datapipeline, integration, and ingestion tools in the market, but before you can feed your data analytics needs, data […].
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content