This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
DataPipeline Logging Best Practices 3.1. Metadata: Information about pipeline runs, & data flowing through your pipeline 3.2. Introduction 2. Setup & Logging architecture 3. Obtain visibility into the code’s execution sequence using text logs 3.3. Monitoring UI & Traceability 3.5.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Today, we are going to apply these principles to the datapipelines. The idea is to transpose these 7 principles to datapipeline knowing that Datapipelines are 100% flexible : if you have the skills, you build the pipeline you want. How does a bad datapipeline process look like ?
However, we've found that this vertical self-service model doesn't work particularly well for datapipelines, which involve wiring together many different systems into end-to-end data flows. Datapipelines power foundational parts of LinkedIn's infrastructure, including replication between data centers.
We cannot scale our expertise as fast as we can scale the Data Cloud. There are just not enough hours in a day to do all the data profiling, design, and coding required to build, deploy, manage, and troubleshoot an ever-growing set of datapipelines with transformations.
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Forward thinking Dataviz is hierarchical — Malloy, once again, provides an excellent article about a new way to see data visualisations. This is Croissant. It's inspirational.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. What are the common challenges faced by engineers and data practitioners in organizing the metadata for their systems? What are the goals of the project?
Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1): Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom).
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. How is the governance of DataHub being managed?
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Open data is the future. And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. A few solutions manage both.
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. The anticipated growth in datapipelines presents both challenges and opportunities.
Understanding DataSchema requires grasping schematization , which defines the logical structure and relationships of data assets, specifying field names, types, metadata, and policies. This is achieved by attaching these elements to individual fields in data assets, providing a thorough understanding of the data.
Today’s post follows the same philosophy: fitting local and cloud pieces together to build a datapipeline. And, when it comes to data engineering solutions, it’s no different: They have databases, ETL tools, streaming platforms, and so on — a set of tools that makes our life easier (as long as you pay for them). not sponsored.
In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service datapipeline development. Key requirements for building datapipelines Every datapipeline starts with a business requirement.
Next, look for automatic metadata scanning. This basically means the tool updates itself by pulling in changes to data structures from your systems. It has real-time metadata updates, deep data lineage, and its flexible if you want to customize or extend it for your teams specific needs.
what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? What were the requirements and selection criteria that led to the selection of that combination of technologies?
Canva writes about its custom solution using dbt and metadata capturing to attribute costs, monitor performance, and enable data-driven decision-making, significantly enhancing its Snowflake environment management. link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. This is what managing data without metadata feels like. Chaos, right?
Data stacks are becoming more and more complex. This brings infinite possibilities for datapipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Data stacks are becoming more and more complex.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.
As a data or analytics engineer, you knew where to find all the transformation logic and models because they were all in the same codebase. You probably work closely with the colleague who builds the datapipeline that you were consuming. There was only one data team, two at most. null, null).
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. The anticipated growth in datapipelines presents both challenges and opportunities.
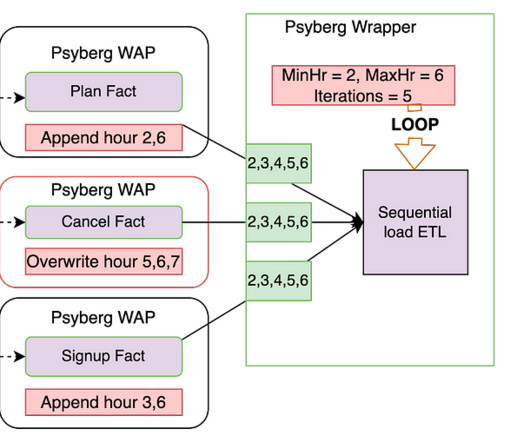
We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Furthermore, we’ll delve into the inner workings of Psyberg, its unique features, and how it integrates into our datapipelining workflows. This is mainly used to identify new changes since the last update.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. We want interoperability for any data stored versus we have to think how to store the data in a specific node to optimize the processing. We want to have our hands free and be totally devoted to devops principles.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
We’re excited to announce today that Snowflake has invested in Metaplane , a leading end-to-end data observability platform that helps data teams improve the quality and performance of their data. Metaplane ensures that every company can trust the data that powers their business.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
The mission of the data discovery team is twofold: 1) The data team must discover the data in the IT landscape 2) The data team must make the data in the IT landscape discoverable to the operations team Let’s unpack this. 1) The data discovery team must work on discovering the IT landscape.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
Now, let’s explore the state of our pipelines after incorporating Psyberg. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep datapipeline. The session metadata table can then be read to determine the pipeline input.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Benefits: Cost and Time Efficiency : no longer need to move data between system Data Consistency : reduces the occurrence of similar-yet-different datasets, leading to fewer datapipelines and simpler data management. It excels in event-driven architectures and datapipelines.
In every step,we do not just read, transform and write data, we are also doing that with the metadata. Last part, it was added the data security and privacy part. Every data governance policy about this topic must be read by a code to act in your data platform (access management, masking, etc.)
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable DataPipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
We all know that data freshness plays a critical role in the performance of Lakehouse. If we can place the metadata, indexing, and recent data files in Express One, we can potentially build a Snowflake-style performant architecture in Lakehouse. Apache Hudi, for example, introduces an indexing technique to Lakehouse.
Reading Time: 7 minutes In today’s data-driven world, efficient datapipelines have become the backbone of successful organizations. These pipelines ensure that data flows smoothly from various sources to its intended destinations, enabling businesses to make informed decisions and gain valuable insights.
Stemming from this analogy, “you” is the orchestrator in data orchestration, and the recipe is the datapipeline. It was created in 2014 by Airbnb and has since been widely adopted by the data engineering community, primarily as it was the first orchestrator allowing to author datapipelines programmatically.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content