This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
by Jasmine Omeke , Obi-Ike Nwoke , Olek Gorajek Intro This post is for all data practitioners, who are interested in learning about bootstrapping, standardization and automation of batch datapipelines at Netflix. You may remember Dataflow from the post we wrote last year titled Datapipeline asset management with Dataflow.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. A variety of platforms have been developed to capture and analyze that information to great effect, but they are inherently limited in their utility due to their nature as storage systems.
Were explaining the end-to-end systems the Facebook app leverages to deliver relevant content to people. At Facebooks scale, the systems built to support and overcome these challenges require extensive trade-off analyses, focused optimizations, and architecture built to allow our engineers to push for the same user and business outcomes.
Today, we are going to apply these principles to the datapipelines. The idea is to transpose these 7 principles to datapipeline knowing that Datapipelines are 100% flexible : if you have the skills, you build the pipeline you want. How does a bad datapipeline process look like ?
However, we've found that this vertical self-service model doesn't work particularly well for datapipelines, which involve wiring together many different systems into end-to-end data flows. Datapipelines power foundational parts of LinkedIn's infrastructure, including replication between data centers.
In this episode Ian Schweer shares his experiences at Riot Games supporting player-focused features such as machine learning models and recommeder systems that are deployed as part of the game binary. Atlan is the metadata hub for your data ecosystem. Step off the hamster wheel and opt for an automated datapipeline like Hevo.
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. Connect your warehouse to Hightouch, paste a SQL query, and use their visual mapper to specify how data should appear in your SaaS systems.
Summary The binding element of all data work is the metadata graph that is generated by all of the workflows that produce the assets used by teams across the organization. The DataHub project was created as a way to bring order to the scale of LinkedIn’s data needs. No more scripts, just SQL.
Below is the entire set of steps in the data lifecycle, and each step in the lifecycle will be supported by a dedicated blog post(see Fig. 1): Data Collection – data ingestion and monitoring at the edge (whether the edge be industrial sensors or people in a vehicle showroom).
DataPipeline Observability: A Model For Data Engineers Eitan Chazbani June 29, 2023 Datapipeline observability is your ability to monitor and understand the state of a datapipeline at any time. We believe the world’s datapipelines need better data observability.
Summary Building a well managed data ecosystem for your organization requires a holistic view of all of the producers, consumers, and processors of information. The team at Metaphor are building a fully connected metadata layer to provide both technical and social intelligence about your data. No more scripts, just SQL.
In this episode Guy Yachdav, director of software engineering for ImmunAI, shares the complexities that are inherent to managing data workflows for bioinformatics. RudderStack’s smart customer datapipeline is warehouse-first. You can observe your pipelines with built in metadata search and column level lineage.
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Tool sprawl is another hurdle that data teams must overcome.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. This generalisation makes their data models complex and cryptic and require domain expertise. As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly.
The system leverages a combination of an event-based storage model in its TimeSeries Abstraction and continuous background aggregation to calculate counts across millions of counters efficiently. link] Grab: Metasense V2 - Enhancing, improving, and productionisation of LLM-powered data governance. Boyter on Bloom Filters and SQLite.
What are the other systems that feed into and rely on the Trino/Iceberg service? what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? Email hosts@dataengineeringpodcast.com with your story.
As a data or analytics engineer, you knew where to find all the transformation logic and models because they were all in the same codebase. You probably work closely with the colleague who builds the datapipeline that you were consuming. There was only one data team, two at most. How did they do it?
In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service datapipeline development. Key requirements for building datapipelines Every datapipeline starts with a business requirement.
Summary At the core of every datapipeline is an workflow manager (or several). Deploying, managing, and scaling that orchestration can consume a large fraction of a data team’s energy so it is important to pick something that provides the power and flexibility that you need.
As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. In this blog post, we’ll explore key strategies that data teams should adopt to prepare for the year ahead. Tool sprawl is another hurdle that data teams must overcome.
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
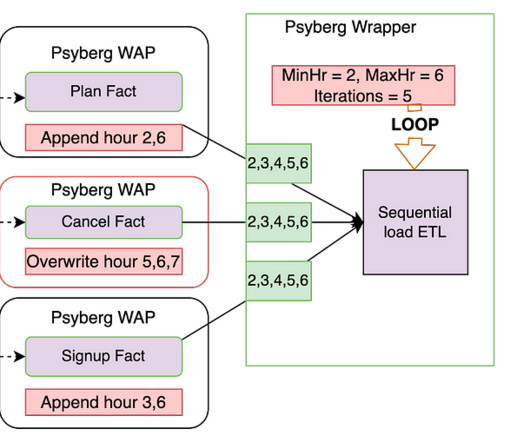
We’ll discuss batch data processing, the limitations we faced, and how Psyberg emerged as a solution. Furthermore, we’ll delve into the inner workings of Psyberg, its unique features, and how it integrates into our datapipelining workflows. What is late-arriving data? How does late-arriving data impact us?
In this episode Nick King discusses how you can be intentional about data creation in your applications and services to reduce the friction and errors involved in building data products and ML applications. Atlan is the metadata hub for your data ecosystem. What are some of the unique characteristics of that information?
Were sharing how Meta built support for data logs, which provide people with additional data about how they use our products. Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand.
Data stacks are becoming more and more complex. This brings infinite possibilities for datapipelines to break and a host of other issues, severely deteriorating the quality of the data and causing teams to lose trust. Data stacks are becoming more and more complex. Sifflet also offers a 2-week free trial.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. It enhances data quality, governance, and automation, transforming raw data into valuable insights. Imagine a library with millions of books but no catalog system to organize them.
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. It excels in event-driven architectures and datapipelines. Fluss is tailored for real-time analytics.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Especially once they realize 90% of all major data sources like Google Analytics, Salesforce, Adwords, Facebook, Spreadsheets, etc.,
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
The article summarizes the recent macro trends in AI and data engineering, focusing on Vibe coding, human-in-the-loop system design, and rapid simplification of developer tooling. As these assistants evolve, they signal a future where scalable, low-latency datapipelines become essential for seamless, intelligent user experiences.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for datapipelines. and then to Nuage 3.0, The article highlights Nuage 3.0's
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Struggling with broken pipelines? Missing data? Atlan is the metadata hub for your data ecosystem.
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
There’s a huge gap between the data quality most companies have by default and the data quality needed for successful AI. And that gap is directly affecting the performance and reliability of AI systems everywhere. Metaplane ensures that every company can trust the data that powers their business.
Summary There are extensive and valuable data sets that are available outside the bounds of your organization. Whether that data is public, paid, or scraped it requires investment and upkeep to acquire and integrate it with your systems. Atlan is the metadata hub for your data ecosystem.
Applying those same practices to data can prove challenging due to the number of systems that need to be included to implement a complete feature. Atlan is the metadata hub for your data ecosystem. Summary Agile methodologies have been adopted by a majority of teams for building software applications.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Our open, interoperable platform is deployed easily in all data ecosystems, and includes unique security and governance capabilities. 4-Ready for modern data fabric architectures.
Foundation Capital: A System of Agents brings Service-as-Software to life software is no longer simply a tool for organizing work; software becomes the worker itself, capable of understanding, executing, and improving upon traditionally human-delivered services. 60+ speakers from LinkedIn, Shopify, Amazon, Lyft, Grammarly, Mistral, et al.
Summary Data analysis is a valuable exercise that is often out of reach of non-technical users as a result of the complexity of datasystems. Atlan is the metadata hub for your data ecosystem. Modern data teams are dealing with a lot of complexity in their datapipelines and analytical code.
Now, let’s explore the state of our pipelines after incorporating Psyberg. Pipelines After Psyberg Let’s explore how different modes of Psyberg could help with a multistep datapipeline. The session metadata table can then be read to determine the pipeline input.
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies. I wonder if these systems expand more capabilities that eventually fall on their own weight.
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable DataPipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
In order to reduce the friction involved in aggregating disparate data sets that share geographic similarities the Unfolded team built a platform that supports working across raster, vector, and tabular data in a single system. Atlan is the metadata hub for your data ecosystem.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Data engineers don’t enjoy writing, maintaining, and modifying ETL pipelines all day, every day.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content