This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AI data engineers are data engineers that are responsible for developing and managing datapipelines that support AI and GenAI data products. Essential Skills for AI Data Engineers Expertise in DataPipelines and ETL Processes A foundational skill for data engineers?
Datapipelines are the backbone of your business’s data architecture. Implementing a robust and scalable pipeline ensures you can effectively manage, analyze, and organize your growing data. We’ll answer the question, “What are datapipelines?” Table of Contents What are DataPipelines?
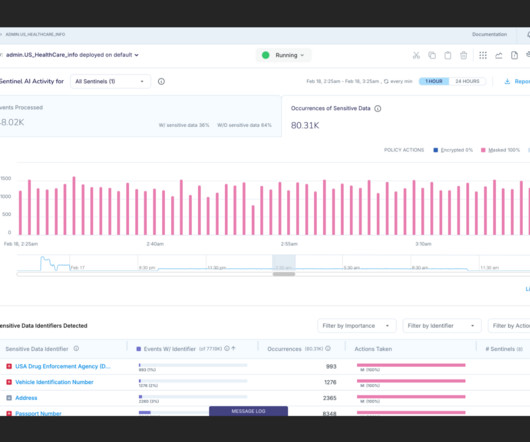
Reimagine Data Governance with Sentinel and Sherlock: Striims AI Agents Striim 5.0 introduces Sentinel and Sherlock, which redefine real-time data governance by seamlessly integrating advanced AI capabilities into your datapipelines. These intelligent agents ensure robust security without sacrificing system performance.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data scientists and data Analysts depend on data engineers to build these datapipelines.
In this post, we'll discuss some key data engineering concepts that data scientists should be familiar with, in order to be more effective in their roles. These concepts include concepts like datapipelines, data storage and retrieval, data orchestrators or infrastructure-as-code.
Modern technologies allow gathering both structured (data that comes in tabular formats mostly) and unstructureddata (all sorts of data formats) from an array of sources including websites, mobile applications, databases, flat files, customer relationship management systems (CRMs), IoT sensors, and so on.
They are also responsible for improving the performance of datapipelines. Data Architects design, create and maintain database systems according to the business model requirements. In other words, they develop, maintain, and test Big Data solutions.
Data architecture is the organization and design of how data is collected, transformed, integrated, stored, and used by a company. What is the main difference between a data architect and a data engineer? Also, they must have in-depth knowledge of data processing languages like Python, Scala, or SQL.
Automated tools are developed as part of the Big Data technology to handle the massive volumes of varied data sets. Big Data Engineers are professionals who handle large volumes of structured and unstructureddata effectively. A Big Data Engineer also constructs, tests, and maintains the Big Data architecture.
BI (Business Intelligence) Strategies and systems used by enterprises to conduct data analysis and make pertinent business decisions. Big Data Large volumes of structured or unstructureddata. Data Engineering Data engineering is a process by which data engineers make data useful.
Both data integration and ingestion require building datapipelines — series of automated operations to move data from one system to another. For this task, you need a dedicated specialist — a data engineer or ETL developer. Key differences between structured, semi-structured, and unstructureddata.
With a plethora of new technology tools on the market, data engineers should update their skill set with continuous learning and data engineer certification programs. What do Data Engineers Do? Let us take a look at the top technical skills that are required by a data engineer first: A. Technical Data Engineer Skills 1.Python
They transform unstructureddata into scalable models for data science. Data Engineer vs Machine Learning Engineer: Responsibilities Data Engineer Responsibilities: Analyze and organize unstructureddata Create data systems and pipelines.
They deploy and maintain database architectures, research new data acquisition opportunities, and maintain development standards. Average Annual Salary of Data Architect On average, a data architect makes $165,583 annually. They manage data storage and the ETL process.
Extract The initial stage of the ELT process is the extraction of data from various source systems. This phase involves collecting raw data from the sources, which can range from structured data in SQL or NoSQL servers, CRM and ERP systems, to unstructureddata from text files, emails, and web pages.
A Data Engineer's primary responsibility is the construction and upkeep of a data warehouse. In this role, they would help the Analytics team become ready to leverage both structured and unstructureddata in their model creation processes. They construct pipelines to collect and transform data from many sources.
With this tool, data science professionals can quickly extract and transform data. It allows integrating various data analysis & data-related components for machine learning (ML) and data mining objective by leveraging its modular datapipelining concept.
Traditional data warehouse platform architecture. Key data warehouse limitations: Inefficiency and high costs of traditional data warehouses in terms of continuously growing data volumes. Inability to handle unstructureddata such as audio, video, text documents, and social media posts. websites, etc.
Data engineering is a new and ever-evolving field that can withstand the test of time and computing developments. Companies frequently hire certified Azure Data Engineers to convert unstructureddata into useful, structured data that data analysts and data scientists can use.
Data Integration 3.Scalability Specialized Data Analytics 7.Streaming Such unstructureddata has been easily handled by Apache Hadoop and with such mining of reviews now the airline industry targets the right area and improves on the feedback given. Scalability 4.Link Link Prediction 5.Cloud Cloud Hosting 6.Specialized
They are responsible for establishing and managing datapipelines that make it easier to gather, process, and store large volumes of structured and unstructureddata. Building datapipelines requires using ETL technologies such as Talend, Apache Nifi, and Apache Airflow.
Big data enables businesses to get valuable insights into their products or services. Almost every company employs data models and big data technologies to improve its techniques and marketing campaigns. Most leading companies use big data analytical tools to enhance business decisions and increase revenues.
Sqoop in Hadoop is mostly used to extract structured data from databases like Teradata, Oracle, etc., and Flume in Hadoop is used to sources data which is stored in various sources like and deals mostly with unstructureddata. The complexity of the big data system increases with each data source.
Whether your goal is data analytics or machine learning , success relies on what datapipelines you build and how you do it. But even for experienced data engineers, designing a new datapipeline is a unique journey each time. Data engineering in 14 minutes.
As Peter Bailis put it in his post , querying unstructureddata using SQL is a painful process. We at Rockset have built the first schemaless SQL data platform. This impedance mismatch between dynamically typed languages and SQL's static typing has driven development away from SQL databases and towards NoSQL systems.
If the transformation step comes after loading (for example, when data is consolidated in a data lake or a data lakehouse ), the process is known as ELT. You can learn more about how such datapipelines are built in our video about data engineering.
In our earlier articles, we have defined “What is Apache Hadoop” To recap, Apache Hadoop is a distributed computing open source framework for storing and processing huge unstructured datasets distributed across different clusters. Apache Kafka Use Cases Spotify uses Kafka as a part of their log collection pipeline.
Additionally, columnar storage allows BigQuery to compress data more effectively, which helps to reduce storage costs. BigQuery enables users to store data in tables, allowing them to quickly and easily access their data. It supports structured and unstructureddata, allowing users to work with various formats.
8) Difference between ADLS and Azure Synapse Analytics Fig: Image by Microsoft Highly scalable and capable of ingesting and processing enormous amounts of data, Azure Data Lake Storage Gen2 and Azure Synapse Analytics are both available (on a Peta Byte scale). For data access, Synapse SQL, an enhanced version of TSQL, is used.
Qubole Using ad-hoc analysis in machine learning, it fetches data from a value chain using open-source technology for big data analytics. Qubole provides end-to-end services in moving datapipelines with reduced time and effort. Multi-source data can be migrated to one location through this tool.
We’d be remiss not to share that Joseph was a recent guest on Databand’s MAD Data Podcast , where he discussed ways to keep data systems from becoming unwieldy and shared tips for data teams to manage their data warehouses and keep datapipelines running reliably. You can also watch the video recording.
PostgreSQL has been gaining a lot of traction recently because of its ability to provide both RDBMS-like and NoSQL-like features which enable data to be stored in traditional rows and columns while also providing the option to store complete JSON objects. This will be read by the service and applied to the data in PostgreSQL.
Relational Database Management Systems (RDBMS) Non-relational Database Management Systems Relational Databases primarily work with structured data using SQL (Structured Query Language). SQL works on data arranged in a predefined schema. Non-relational databases support dynamic schema for unstructureddata.
Over the past decade, the IT world transformed with a data revolution. The rise of big data and NoSQL changed the game. Systems evolved from simple to complex, and we had to split how we find data from where we store it. Skills acquired : Core data concepts. Data storage options. Now, it's different.
Storage Layer: This is a centralized repository where all the data loaded into the data lake is stored. HDFS is a cost-effective solution for the storage layer since it supports storage and querying of both structured and unstructureddata. Insights from the system may be used to process the data in different ways.
As a result, today we have a huge ecosystem of interoperable instruments addressing various challenges of Big Data. On top of HDFS, the Hadoop ecosystem provides HBase , a NoSQL database designed to host large tables, with billions of rows and millions of columns. MongoDB: an NoSQL database with additional features.
Enter Striims AI Agents Sentinel and Sherlock: Pioneering AI-Powered Data Governance Striims AI agents, Sentinel and Sherlock, are pioneering tools that bring real-time, AI-powered governance to your datapipelines, increasing security without compromising performance.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content