This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This traditional SQL-centric approach often challenged data engineers working in a Python environment, requiring context-switching and limiting the full potential of Python’s rich libraries and frameworks. These benefits extend far beyond the developer team.
The data generated was as varied as the departments relying on these applications. Some departments used IBM Db2, while others relied on VSAM files or IMS databases creating complex data governance processes and costly datapipeline maintenance.
Summary How much time do you spend maintaining your datapipeline? This was a fascinating conversation with someone who has spent his entire career working on simplifying complex data problems. How does the data-centric approach of DataCoral differ from the way that other platforms think about processing information?
To tackle these challenges, we’re thrilled to announce CDP Data Engineering (DE) , the only cloud-native service purpose-built for enterprise data engineering teams. Native Apache Airflow and robust APIs for orchestrating and automating job scheduling and delivering complex datapipelines anywhere.
With Astro, you can build, run, and observe your datapipelines in one place, ensuring your mission critical data is delivered on time. Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g., Generative AI demands the processing of vast amounts of diverse, unstructured data (e.g.,
What does an on-call rotation for a data engineer/data platform engineer look like as compared with an application-focused team? How does the focus on data assets/data products shift your approach to observability as compared to a table/pipelinecentric approach?
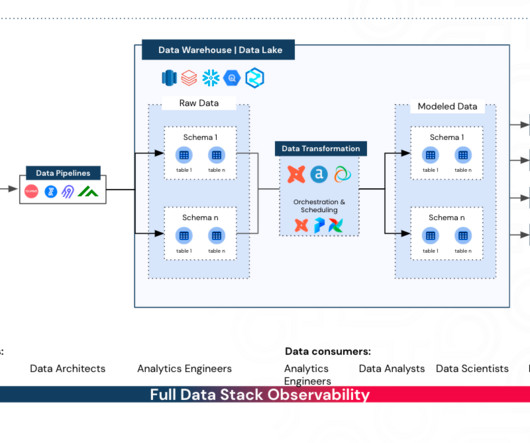
When data reaches the Gold layer, it is highly curated and structured, offering a single version of the truth for decision-makers across the organization. We have also seen a fourth layer, the Platinum layer , in companies’ proposals that extend the Datapipeline to OneLake and Microsoft Fabric.
After the launch of CDP Data Engineering (CDE) on AWS a few months ago, we are thrilled to announce that CDE, the only cloud-native service purpose built for enterprise data engineers, is now available on Microsoft Azure. . CDP data lifecycle integration and SDX security and governance. Key features of CDP Data Engineering.
The blog emphasizes the importance of starting with a clear client focus to avoid over-engineering and ensure user-centric development. impactdatasummit.com Thumbtack: What we learned building an ML infrastructure team at Thumbtack Thumbtack shares valuable insights from building its ML infrastructure team.
The list of Top 10 semi-finalists is a perfect example: we have use cases for cybersecurity, gen AI, food safety, restaurant chain pricing, quantitative trading analytics, geospatial data, sales pipeline measurement, marketing tech and healthcare. Our sincere thanks go out to everyone who participated in this year’s competition.
One paper suggests that there is a need for a re-orientation of the healthcare industry to be more "patient-centric". Furthermore, clean and accessible data, along with data driven automations, can assist medical professionals in taking this patient-centric approach by freeing them from some time-consuming processes.
However, that's also something we're re-thinking with our warehouse-centric strategy. How does reverse ETL factor into the enrichment process for profile data? Rudderstack]([link] RudderStack provides all your customer datapipelines in one platform. Let us know if you have opinions there!
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. The next problem will be the diversity of these mini data platforms (because of the configuration) and you even go deeper in problems with managing different technologies or version.
A star-studded baseball team is analogous to an optimized “end-to-end datapipeline” — both require strategy, precision, and skill to achieve success. Just as every play and position in baseball is key to a win, each component of a datapipeline is integral to effective data management.
In the modern world of data engineering, two concepts often find themselves in a semantic tug-of-war: datapipeline and ETL. Fast forward to the present day, and we now have datapipelines. Data Ingestion Data ingestion is the first step of both ETL and datapipelines.
At the same time Maxime Beauchemin wrote a post about Entity-Centricdata modeling. In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. I hope he will fill the gaps. dbt, as of today, is the leading framework.
At the same time Maxime Beauchemin wrote a post about Entity-Centricdata modeling. In the recent years dbt simplified and revolutionised the tooling to create data models. This week I discovered SQLMesh , a all-in-one datapipelines tool. I hope he will fill the gaps. dbt, as of today, is the leading framework.
In this episode founder Shayan Mohanty explains how he and his team are bringing software best practices and automation to the world of machine learning data preparation and how it allows data engineers to be involved in the process. Data stacks are becoming more and more complex. Data stacks are becoming more and more complex.
NVidia released Eagle a vision-centric multimodal LLM — Look at the example in the Github repo, given an image and a user input the LLM is able to answer things like "Describe the image in detail" or "Which car in the picture is more aerodynamic" based on a drawing.
To this end, UBL embarked on a data analytics project that would achieve its goals for an improved data environment. Next, it needed to enhance the company’s customer-centric approach for a needs-based alignment of products and services. Mr. Kashif Riaz, head of data and AI at UBL, shared his thoughts on this project. “To
To enable LGIM to better utilize its wealth of data, LGIM required a centralized platform that made internal data discovery easy for all teams and could securely integrate external partners and third-party outsourced datapipelines.
Data Engineering is typically a software engineering role that focuses deeply on data – namely, data workflows, datapipelines, and the ETL (Extract, Transform, Load) process. What is the role of a Data Engineer? Data scientists and data Analysts depend on data engineers to build these datapipelines.
Of course, this is not to imply that companies will become only software (there are still plenty of people in even the most software-centric companies), just that the full scope of the business is captured in an integrated software defined process. Here, the bank loan business division has essentially become software.
Without DataOps, companies can employ hundreds of data professionals and still struggle. The datapipelines must contend with a high level of complexity – over seventy data sources and a variety of cadences, including daily/weekly updates and builds. That’s the power of DataOps automation.
Here is the agenda, 1) Data Application Lifecycle Management - Harish Kumar( Paypal) Hear from the team in PayPal on how they build the data product lifecycle management (DPLM) systems. 3) DataOPS at AstraZeneca The AstraZeneca team talks about data ops best practices internally established and what worked and what didn’t work!!!
A data scientist is only as good as the data they have access to. Most companies store their data in variety of formats across databases and text files. This is where data engineers come in — they build pipelines that transform that data into formats that data scientists can use.
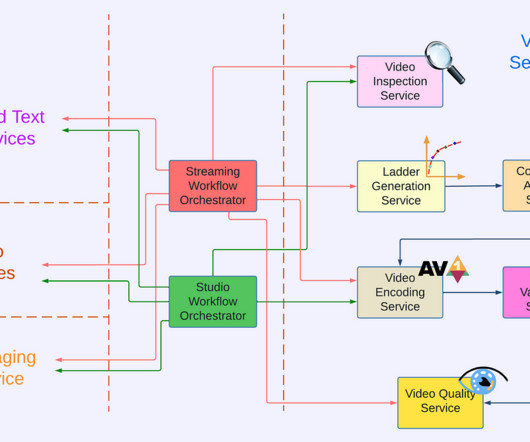
The Netflix video processing pipeline went live with the launch of our streaming service in 2007. By integrating with studio content systems, we enabled the pipeline to leverage rich metadata from the creative side and create more engaging member experiences like interactive storytelling.
Take Astro (the fully managed Airflow solution) for a test drive today and unlock a suite of features designed to simplify, optimize, and scale your datapipelines. Try For Free → Conference Alert: Data Engineering for AI/ML This is a virtual conference at the intersection of Data and AI.
Treating data as a product is more than a concept; it’s a paradigm shift that can significantly elevate the value that business intelligence and data-centric decision-making have on the business. DatapipelinesData integrity Data lineage Data stewardship Data catalog Data product costing Let’s review each one in detail.
In a nutshell, DataOps engineers are responsible not only for designing and building datapipelines, but iterating on them via automation and collaboration as well. So, does this mean you should choose DataOps engineering vs. data engineering when considering your next career move? What does a DataOps engineer do? It depends!
Data Cascades are said to be pervasive, to lack immediate visibility, but to eventually impact the world in a negative manner. Related to the neglect of data quality, it has been observed that much of the efforts in AI have been model-centric, that is, mostly devoted to developing and improving models , given fixed data sets.
These limited-term databases can be generated as needed from automated recipes (orchestrated pipelines and qualification tests) stored and managed within the process hub. . The process hub capability of the DataKitchen Platform ensures that those processes that act upon data – the tests, the recipes – are shareable and manageable.
” Key Partnership Benefits: Cost Optimization and Efficiency : The collaboration is poised to reduce IT and data management costs significantly, including an up to 68% reduction in data stack spend and the ability to build datapipelines 7.5x ABOUT ASCEND.IO Learn more at Ascend.io or follow us @ascend_io.
Business users are unable to find and access data assets critical to their workflows. Data engineers spend countless hours troubleshooting broken pipelines. The data team is constantly burning out and has a high employee turnover. Stakeholders fail to see the ROI behind expensive data initiatives.
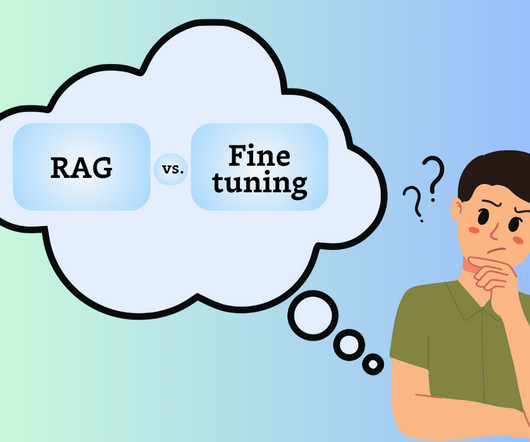
It can involve prompt engineering, vector databases like Pinecone , embedding vectors and semantic layers, data modeling, data orchestration, and datapipelines – all tailored for RAG. But when it’s done right, RAG can add an incredible amount of value to AI-powered data products. What is Fine Tuning?
The Nuances of Snowflake Costing Snowflake’s pricing strategy is an exemplification of its user-centric approach: pay for what you use. The Predictability of Pipelines In stark contrast to ad-hoc queries, pipelines are where cost optimization efforts can yield significant dividends.
Analytics Stacks for Startups Jan Katins, Senior IT Consultant/Data Engineer, kreuzwerker GmbH The stack should be relatively fast to implement (two weeks is possible), so you can quickly reap the benefits of having a data warehouse and BI Tooling in place or upload enriched data back to operational systems.
Streamlit gives data scientists and Python developers the ability to quickly turn data and models into interactive, enterprise-ready applications. Simplified streaming pipelines in Snowflake We are expanding our streaming capabilities with Dynamic Tables (public preview). We also announced the private preview of Snowflake CLI.
Cost Savings : Insights derived from data products can directly lead to cost savings in the business. Risk Reduction : Data-centric decision-making can also contribute to risk reduction. In the case of data products, these are networks of datapipelines, which makes them an integral part of your modern operational machinery.
Factors Data Engineer Machine Learning Definition Data engineers create, maintain, and optimize data infrastructure for data. In addition, they are responsible for developing pipelines that turn raw data into formats that data consumers can use easily. Assess the needs and goals of the business.
It aims to explain how we transformed our development practices with a data-centric approach and offers recommendations to help your teams address similar challenges in your software development lifecycle. This approach ensured comprehensive data extraction while handling various edge cases and log formats.
Data Engineering Weekly Is Brought to You by RudderStack RudderStack Profiles takes the SaaS guesswork, and SQL grunt work out of building complete customer profiles, so you can quickly ship actionable, enriched data to every downstream team. See how it works today.
This means moving beyond product-centric thinking to a data-driven customer experience model that’s consistent across all channels. Next, the wealth management industry is also shifting away from a product focus to a client-centric model. DataOS is the world’s first operating system.
An Azure Data Engineer is a professional responsible for designing, implementing, and managing data solutions using Microsoft's Azure cloud platform. They work with various Azure services and tools to build scalable, efficient, and reliable datapipelines, data storage solutions, and data processing systems.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content